
How BGP Handles Failover Across Data Centers
BGP (Border Gateway Protocol) ensures reliable data routing between data centers, especially during outages. It dynamically redirects traffic to backup paths, minimizing downtime and maintaining service availability. Here’s how it works:
- Route Advertisements and Withdrawals: BGP informs routers about available paths. When a failure occurs, it withdraws affected routes and redirects traffic.
- Route Preferences: Attributes like
local-preferenceandAS-path prependingprioritize primary data centers while keeping backups ready. - Traffic Rerouting: BGP updates propagate across the network, ensuring traffic shifts seamlessly to operational paths, aided by tools like ECMP for load balancing.
Challenges include slow convergence times and complex configurations. Solutions like BFD, BGP Prefix Independent Convergence, and health monitoring tools reduce delays. Testing failover scenarios and synchronizing server resources across data centers ensure smooth transitions during outages.
BGP is a key tool for businesses to maintain operations during disruptions, balancing reliability and scalability.
BGP#: A System for Dynamic Route Control in Data Centers
How BGP Manages Failover Between Data Centers
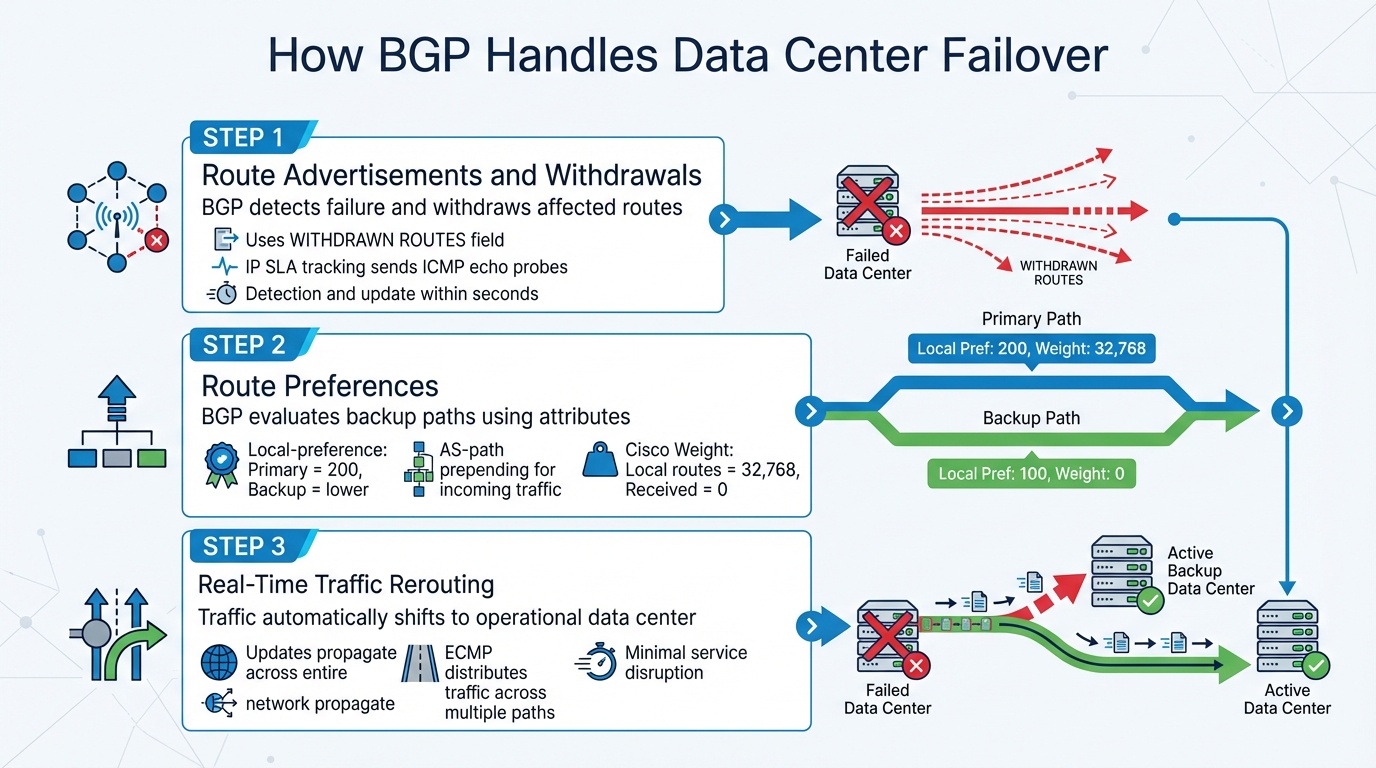
BGP Failover Process: How Traffic Reroutes During Data Center Outages
When a data center experiences an outage, BGP steps in to handle failover through route advertisements, attribute-based prioritization, and traffic rerouting. These mechanisms work together to ensure services stay online and traffic is quickly redirected, maintaining business operations even during disruptions.
Route Advertisements and Withdrawals
BGP relies on route advertisements to inform peers about network reachability. Under normal conditions, these advertisements create a detailed map of available paths. However, when a failure occurs, BGP adjusts dynamically. It can withdraw the affected route using the WITHDRAWN ROUTES field, modify route attributes, or automatically remove routes if the session ends. This adaptability prevents traffic from being directed to non-functional paths.
To enhance this process, health monitoring tools like IP SLA tracking are often integrated with BGP. These tools send ICMP echo probes to verify path availability. When a failure is detected, the tool signals BGP to withdraw the problematic route, redirecting traffic to a backup path. Network engineer Matt DeShon highlights this capability: "BGP successfully detected the failure and updated its routing table within seconds, ensuring continuous service availability."
Setting Route Preferences
BGP uses attributes to determine which paths take priority. In multi-data center setups, the local-preference attribute plays a key role. Assigning a higher value (e.g., 200) to routes from the primary data center ensures it is the preferred path during normal operations, while backup routes with lower values act as secondary options.
For incoming traffic, AS-path prepending is a common technique. By artificially lengthening the AS-path of a backup route, administrators make it appear less desirable to external networks. This keeps traffic flowing to the primary data center unless it becomes unavailable, at which point the backup route takes over.
Cisco devices add another layer of control with the Weight attribute. Locally originated routes have a default weight of 32,768, while received routes start at 0. This gives network administrators precise control over traffic routing at the local level.
Real-Time Traffic Rerouting
When a failure occurs, BGP doesn’t just update a single router – it propagates the change across the entire network. The failed route is removed, and all BGP neighbors are notified to update their routing tables. This cascading update ensures traffic is redirected to operational data centers without delay.
In modern Clos (leaf-and-spine) topologies, BGP employs Equal Cost Multipath (ECMP) to distribute traffic across multiple paths with the same cost. This setup provides both load balancing and redundancy. If one path fails, traffic automatically shifts to other available paths without requiring manual intervention. This approach is crucial for scaling large data centers horizontally.
The speed of this rerouting hinges on convergence time, which is influenced by how quickly the failure is detected and how fast updates propagate through the network. With effective health monitoring, BGP can identify failures and reroute traffic within seconds, ensuring minimal service disruption.
Common BGP Failover Problems and Solutions
BGP failover can encounter technical challenges that slow recovery and complicate operations, especially in multi-data center setups.
Convergence Delays
One of the biggest hurdles in BGP failover is convergence time – the time it takes for the network to detect a failure and switch to backup paths. BGP is "prefix-dependent", meaning routers advertise only their best paths. When a path fails, the router withdraws the route, recalculates alternatives, and updates neighboring routers. This step-by-step process can take time.
Default BGP timers, like the Minimum Route Advertisement Interval (MRAI), add to the delay by spacing out updates to avoid route flapping. While this prevents instability, it slows convergence.
To address this, several techniques can help:
- Bidirectional Forwarding Detection (BFD): Detects faults in under a second.
- BGP Prefix Independent Convergence (PIC): Preloads primary and backup paths into routing tables, allowing instant switching without waiting for full recalculations.
- Reducing MRAI to 0 seconds: Speeds up the propagation of updates.
- Advertising best-external paths: Prepares the network for immediate failover by sharing alternative routes in advance.
These methods significantly reduce convergence delays, but BGP configurations come with their own set of challenges.
Configuration Complexity
Managing BGP across multiple data centers can get complicated. Configuring attributes like local-preference, AS-path prepending, and route policies across a large network demands precision and planning. As Matt Deshon, a network engineer, remarked:
"BGP configurations, especially when managing attributes like local-preference and AS-path prepending, can become complex in large environments. Proper documentation and testing were critical to success."
Simplifying operations is key. Using External BGP (EBGP) as the sole routing protocol avoids issues from protocol interactions. A clear Autonomous System Number (ASN) scheme – with private-use ASNs – helps keep different sites and network tiers distinct. Additionally, rigorous testing, including simulated link failures, ensures that configurations perform as expected in real-world conditions. Detailed documentation and testing are essential for success.
Even with simplified configurations, ensuring smooth traffic redirection is critical.
Maintaining Session Persistence During Failover
Fast route updates alone aren’t enough – session persistence is crucial to avoid disruptions during traffic redirection. Without proper synchronization, users may lose active connections, shopping carts, or ongoing work when traffic shifts between data centers, leading to a frustrating experience despite a technically successful failover.
The solution lies in synchronizing server resources across data centers. Database replicas, application servers, and session stores must stay consistent, enabling a seamless transition when traffic is redirected. BGP Graceful Restart helps by maintaining the forwarding state during control plane reconvergence, ensuring the data plane remains operational as routing updates propagate. For networks using Equal Cost Multipath (ECMP), implementing consistent hashing ensures that sessions remain mapped to the same functional next-hop, even during path failures. Adding route flap damping further stabilizes the network by preventing frequent link disruptions from impacting sessions.
sbb-itb-59e1987
Best Practices for BGP Failover Implementation
Implementing BGP failover effectively goes beyond simple configuration. It requires active monitoring and thorough testing to ensure your network can respond swiftly and reliably when issues arise.
Health Checks and Faster Failover Detection
The default BGP hold timer of 90 seconds is far too sluggish for today’s fast-paced applications. This is where Bidirectional Forwarding Detection (BFD) comes in. By sending rapid "hello" packets between BGP neighbors, BFD can detect failures in under a second. For example, setting BFD to detect issues within 300 milliseconds (with a multiplier of 3) speeds up response times significantly. In AWS Transit Gateway Connect setups, using BFD on unpinned tunnels can reduce failover times to just 0.9 seconds – a dramatic 70% improvement compared to relying solely on standard BGP timers.
For networks using multiple ISPs, IP SLA tracking adds an extra layer of reliability. Configure IP SLA monitors with ICMP echo probes to check path reachability every 10 seconds. Link these probes to a track object that BGP can use to adjust routing dynamically based on real-time conditions. Instead of just pinging the next-hop router, aim for a dependable external address like 8.8.8.8 to ensure end-to-end connectivity. If a health check fails, BGP will automatically withdraw the route and redirect traffic to the backup path.
These quick detection methods lay the groundwork for rigorous testing to ensure failover works as intended.
Testing and Validation
Thorough testing is essential to confirm that all proactive measures deliver the desired resilience. As AWS highlights in their reliability guidelines:
"The only error recovery that works is the path you test frequently."
Simulate link failures to verify that your secondary data center can handle the full production workload without missing a beat. This includes manually shutting down links between data centers to observe how quickly BGP routing tables update. Testing shouldn’t stop at the network layer – validate service quotas, database replication, and server load balancing during failover scenarios to ensure applications remain functional. Be mindful of configuration drift between primary and secondary sites, as inconsistencies can quietly sabotage your failover strategy. Using automated tools to detect and fix these discrepancies before an actual outage can save you from unnecessary downtime.
Serverion‘s Multi-Data Center BGP Implementation

Infrastructure and Features
Serverion takes advantage of BGP’s reliable failover capabilities by implementing a carefully designed Layer 3 architecture across its global data centers. This pure Layer 3 setup relies on EBGP to manage traffic between data centers. Each data center operates with its own AS number, enabling core routers to advertise internal prefixes while isolating failure zones. This structure supports Serverion’s wide range of hosting services, including affordable virtual private servers (VPS), high-performance dedicated servers, and specialized solutions like blockchain masternode hosting and AI GPU servers.
To maintain seamless operations, the network employs IP SLA tracking with ICMP echo probes, which continuously monitor the health of inter-data center connections. If a failure is detected, BGP swiftly withdraws the affected route and redirects traffic to a backup location within seconds. Primary routes are assigned higher local-preference values (typically 200), while AS-path prepending ensures backup routes remain secondary. This setup minimizes service interruptions and keeps customer workloads running smoothly, even during unexpected outages.
Benefits for Customers
Serverion’s BGP-driven network design offers clear advantages for businesses relying on its hosting services. By limiting failure domains to individual data centers, the infrastructure avoids the widespread disruptions and broadcast storms often associated with Layer 2 designs. Automated failover mechanisms ensure uninterrupted service without requiring manual intervention – an essential feature for time-sensitive applications like PBX hosting or blockchain operations.
The network’s scalable Clos topology, combined with ECMP, ensures efficient load balancing and low latency. This active-active configuration allows all data centers to share traffic during normal conditions, maintaining consistent performance. Additionally, the infrastructure’s cost-efficient design – accounting for only 10–15% of overall data center expenses – delivers enterprise-grade reliability without inflating costs, making it a smart choice for businesses of all sizes.
Conclusion: BGP for Reliable Data Center Failover
BGP plays a critical role in ensuring uninterrupted services during data center failovers by automating traffic rerouting. Even if an entire facility goes offline, BGP, when paired with tools like IP SLA tracking, can detect issues and adjust routing tables within seconds, keeping latency disruptions to a minimum.
This functionality brings clear benefits: smaller failure domains thanks to fully routed Layer 3 designs, seamless active-active traffic distribution using ECMP, and the ability to scale efficiently for large data centers. With BGP, multiple data centers can share traffic simultaneously, optimizing performance without breaking the bank – network infrastructure typically accounts for only 10–15% of total data center costs.
That said, BGP does come with its share of challenges. Convergence delays can affect real-time applications, route flaps may lead to instability, and its configuration requires a high level of expertise. To address these issues, consider implementing route flap damping, fine-tuning BGP timers, and ensuring server resources are synchronized across sites.
FAQs
How does BGP minimize downtime during a data center outage?
BGP, or Border Gateway Protocol, plays a crucial role in keeping data flowing smoothly even during a data center outage. It does this by dynamically rerouting traffic. If the primary route goes down, BGP automatically shifts traffic to a preconfigured backup route, ensuring operations continue with minimal disruption.
This process works because BGP advertises both primary and backup paths ahead of time. In the event of a failure, it quickly switches to the backup path, maintaining service availability and minimizing the impact on users.
What challenges does BGP face during failover, and how can they be addressed?
Border Gateway Protocol (BGP) plays a critical role in managing traffic between multiple data centers, but it’s not without its challenges, especially when it comes to failover. One major issue is slow convergence, which can delay the rerouting of traffic after a failure. On top of that, BGP lacks built-in security, leaving it vulnerable to misconfigurations or even malicious updates. Traditional failover mechanisms, like Prefix-Independent Convergence (PIC), also have their limits – typically relying on just one primary and one backup path. For more intricate setups, this can fall short. Adding to the complexity, coordinating failover with server resources like databases or application replicas can be tricky.
However, these challenges can be addressed with careful planning and implementation of best practices. For instance, using advanced BGP features such as backup-path extensions allows secondary routes to be preloaded, speeding up failover. Adjusting attributes like Local Preference and AS-Path Prepending can help optimize traffic flow during outages. To tackle security concerns, measures such as RPKI validation and route monitoring can block unauthorized updates. Additionally, integrating BGP with automated health checks ensures traffic is only redirected to sites that are fully operational, reducing downtime and boosting reliability. Serverion’s global infrastructure leverages these strategies to provide dependable and efficient failover solutions for its clients.
Why is session persistence crucial for BGP failover, and how is it managed?
Session persistence plays a key role in BGP failover by ensuring that routes learned from a BGP peer remain active, even if that peer becomes unavailable. This helps avoid traffic disruptions, like black holes, and keeps services running smoothly during failover events.
One way BGP maintains session persistence is through long-lived graceful restart (LLGR). This feature temporarily holds onto BGP-learned routes until either the LLGR stale timer runs out or the peer indicates that its routing updates are complete. By stabilizing routes during transitions, session persistence ensures a smoother failover process across data centers.




