
Failover-ontwerp voor meerdere regio's ten behoeve van noodherstel
Failover tussen regio's Het garandeert bedrijfscontinuïteit tijdens grote verstoringen door automatisch workloads over te zetten van een primaire naar een secundaire regio. Deze aanpak is ideaal voor grootschalige storingen zoals orkanen of regionale stroomuitval. Het brengt echter hogere kosten en een aanzienlijk grotere complexiteit met zich mee in vergelijking met andere methoden voor noodherstel.
Belangrijke aandachtspunten:
- BetrouwbaarheidBiedt sterke bescherming tegen regionale storingen dankzij geautomatiseerde failover en datareplicatie.
- KostenDuur vanwege dubbele infrastructuur en kosten voor gegevensoverdracht.
- ComplexiteitVereist een geavanceerde configuratie, inclusief DNS-routering en failback-processen.
- Hersteltijddoelstelling (RTO): Verschilt per configuratie:
- Actief-actief: Bijna nul RTO.
- Warmhoudstand: Minuten.
- Koude standby-tijd: Uren.
Andere opties zijn onder meer: actieve-actieve redundantie (hoge betrouwbaarheid, hoogste kosten) en actieve-passieve redundantie (voordeliger, langzamer herstel). De juiste strategie hangt af van de mate waarin uw bedrijf downtime kan verdragen en van uw budget.
| Redundantieoptie | Betrouwbaarheid | Kosten | RTO |
|---|---|---|---|
| Failover tussen regio's | Hoog (regionale stroomuitval) | Hoog | Minuten-uren |
| Actief-Actief | Hoogste (wereldwijde verkeersdeling) | Zeer hoog | Seconden |
| Actief-Passief | Gemiddeld (standby-configuratie) | Gematigd | Minuten-uren |
De juiste methode kiezen vereist een afweging tussen betrouwbaarheid, kosten en herstelsnelheid, gebaseerd op de kritische aard van uw systeem. Regelmatig testen en automatisering zijn essentieel voor succes.
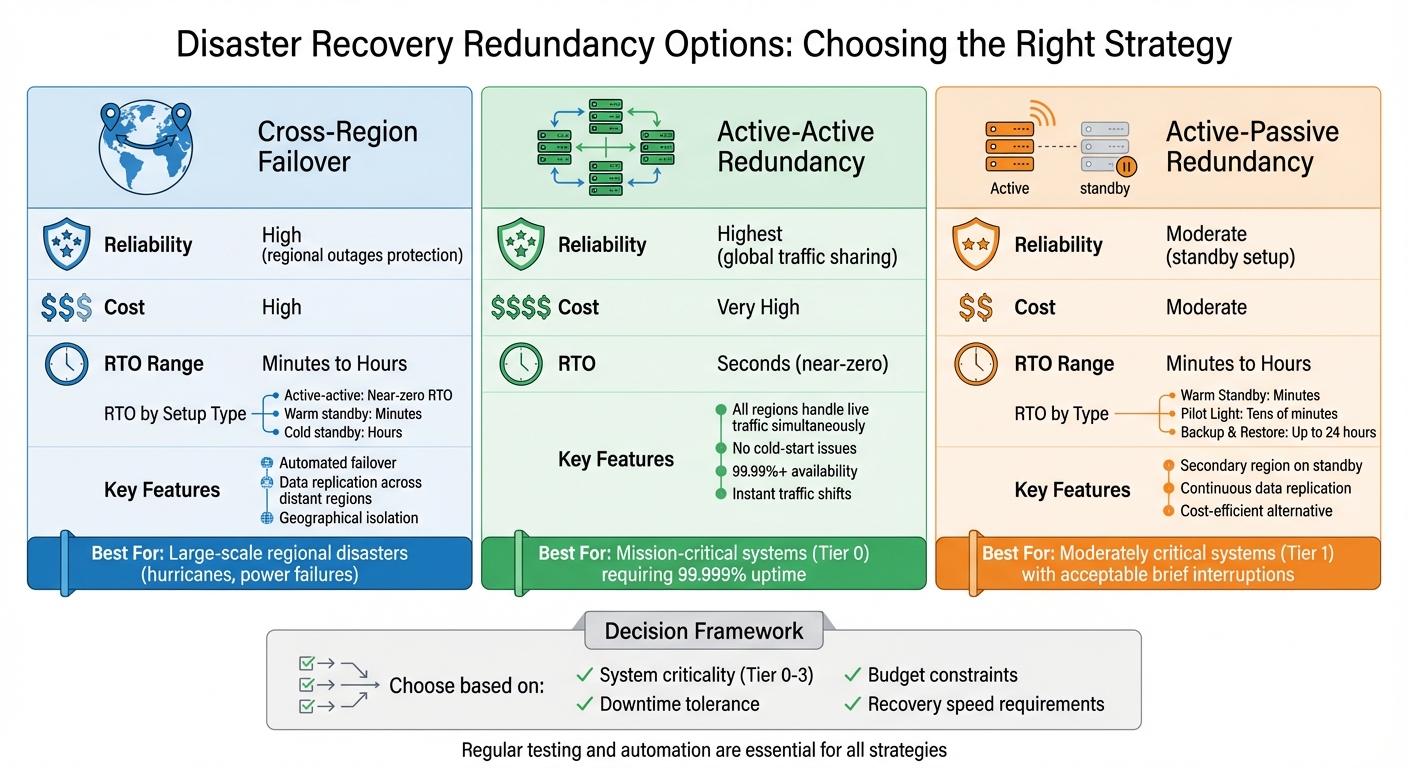
Vergelijking van redundantieopties voor noodherstel: kosten, RTO en betrouwbaarheid
Hoe configureert u failover voor applicaties tussen verschillende regio's?
Een goede configuratie vereist vaak de juiste keuze. datacentrum locaties om de latentie te minimaliseren en redundantie te garanderen.
sbb-itb-59e1987
1. Failover tussen regio's
Failover tussen regio's Failover tussen regio's is een rampenherstelstrategie die is ontworpen om productieworkloads te verplaatsen van een primaire regio naar een secundaire regio die zich ver weg bevindt. Terwijl multi-AZ-strategieën lokale datacenterstoringen binnen een straal van ongeveer 100 kilometer afhandelen, is failover tussen regio's geschikt voor veel grotere rampen, zoals aardbevingen, overstromingen of regionale stroomuitval. Deze opzet is afhankelijk van infrastructuur die honderden of zelfs duizenden kilometers van elkaar verwijderd is. Hieronder gaan we dieper in op de betrouwbaarheid, kostenoverwegingen, operationele uitdagingen en de impact ervan op de Recovery Time Objective (RTO).
Betrouwbaarheid
Failover tussen regio's biedt geografische isolatie, Dit maakt het een robuuste oplossing voor regionale stroomuitval. Als bijvoorbeeld een orkaan een stroomstoring in een hele regio veroorzaakt, neemt de secundaire regio naadloos de stroomvoorziening over. Geautomatiseerde monitoringsystemen detecteren prestatieproblemen en activeren failover, terwijl continue replicatie op blokniveau ervoor zorgt dat gegevens intact blijven en zowel de infrastructuur als kritieke informatie worden beschermd.
Het AWS Well-Architected Framework benadrukt dat het overslaan van de juiste failover-procedures een risico vormt. ""Hoog" risiconiveau Voor het beheersen van de werkdruk. Regelmatige hersteloefeningen zijn essentieel om ervoor te zorgen dat uw rampenherstelplan daadwerkelijk werkt wanneer dat nodig is. Deze oefeningen transformeren plannen van theoretisch naar bewezen, wat cruciaal is om de dienstverlening draaiende te houden en omzetverlies te voorkomen.
Kostenoverwegingen
Failover tussen regio's is aanzienlijk duurder dan oplossingen met meerdere beschikbaarheidszones (Multi-AZ). De reden? Je bent in feite... waardoor uw opslag- en operationele kosten verdubbelen door gespiegelde databases en applicaties in verschillende regio's te onderhouden. Bovendien kunnen de kosten voor gegevensoverdracht bij replicatie tussen regio's snel oplopen, waarbij de kosten aanzienlijk variëren afhankelijk van de betrokken regio's.
Voor grote organisaties met meer dan 2.000 werknemers kunnen de kosten voor noodherstel met behulp van interne oplossingen variëren van... $675.000 tot $1.750.000 per jaar. Als je streeft naar een RTO die bijna nul is, verwacht dan dat de kosten nog hoger oplopen. Realtime replicatie om te voldoen aan minimale RPO-vereisten verhoogt de kosten nog verder. Om deze kosten te beheersen, kiezen veel bedrijven ervoor om alleen hun meest essentiële applicaties te repliceren in plaats van hun volledige omgeving.
Operationele complexiteit
Het instellen van failover tussen regio's is niet zo eenvoudig als het omzetten van een schakelaar – het vereist meer expertise. geavanceerde orkestratie. Je moet wereldwijde DNS-routering, asynchrone datareplicatie en geautomatiseerde failoverprocessen tussen verschillende regio's beheren. Het gebruik van Infrastructure as Code (IaC) is cruciaal voor het waarborgen van consistentie en herhaalbaarheid tussen je primaire en secundaire configuraties.
Het failbackproces – het terugzetten van de activiteiten naar de primaire regio na herstel – is nog complexer. Het omvat het opnieuw synchroniseren van gegevens om verlies te voorkomen, het omleiden van verkeer via DNS en het beheren van omgekeerde replicatie om de nieuw actieve instanties te beveiligen. Deze complexiteit vereist bekwame teams en gedetailleerde documentatie voor een soepele uitvoering.
Hersteltijddoelstelling (RTO)
Je RTO (Recovery Time Objective) is sterk afhankelijk van het failover-model dat je kiest. Actieve-actieve configuraties waardoor beide regio's het verkeer gelijktijdig kunnen verwerken en een RTO (Return Time Objective) van bijna nul wordt bereikt. Warme standby In configuraties waarbij minimale services in de secundaire regio draaien, kunnen RTO's (Recovery Time Objectives) van enkele minuten worden behaald. Aan de andere kant, koude standby Bij benaderingen waarbij resources pas na een storing worden ingeschakeld, worden RTO's (Recovery Time Objectives) in uren gemeten.
Voor systemen die een beschikbaarheid van 99,999% vereisen, worden RTO's doorgaans gemeten in seconden, Terwijl minder kritieke systemen met een beschikbaarheid van 99,91 TP3T een downtime van enkele uren kunnen tolereren. Geautomatiseerde runbooks en IaC-tools verminderen het risico op menselijke fouten tijdens failover, waardoor u zich aan strakke RTO-doelstellingen kunt houden – vooral omdat elke minuut downtime zich vertaalt in verloren omzet en klantvertrouwen.
2. Actieve-actieve redundantie
Actieve-actieve redundantie Dit zorgt ervoor dat applicaties gelijktijdig in twee of meer regio's draaien, waarbij het live verkeer over al deze regio's wordt verdeeld. In tegenstelling tot actieve-passieve configuraties, waarbij de secundaire regio inactief of minimaal actief blijft, verwerken alle regio's in actieve-actieve configuraties daadwerkelijke gebruikersverzoeken. Dit elimineert problemen met een koude start, omdat alle regio's altijd operationeel zijn. Laten we eens kijken hoe deze configuratie de betrouwbaarheid verhoogt, zelfs bij ernstige regionale storingen.
Betrouwbaarheid
Actieve-actieve configuraties bieden betrouwbaarheid van topklasse onder andere rampenherstelstrategieën. Diensten zoals Amazon Route 53 applicatieherstelcontroller De status van meerdere regio's wordt continu gemonitord en verkeer wordt automatisch omgeleid van falende infrastructuur. Deze configuratie is ideaal voor bedrijfskritische workloads (Tier 0) die Service Level Objectives vereisen die hoger liggen dan de standaardwaarden. 99.99%. Voor bedrijven waar zelfs een paar seconden downtime kan leiden tot omzetverlies of een afname van het klantvertrouwen, is dit niveau van betrouwbaarheid onmisbaar.
""Automatisering is beter dan heldhaftigheid: een geautomatiseerd failoverproces is oneindig veel beter dan erop te vertrouwen dat iemand handmatig problemen oplost tijdens een storing." – Alex Brooks, AWS Solutions Architect
Kostenefficiëntie
Actieve-actieve redundantie is de duurste Een optie voor noodherstel. Dit komt doordat u betaalt voor de volledige reken- en opslagcapaciteit in meerdere regio's, 24/7. De kosten worden verder verhoogd door continue datareplicatie tussen regio's en facturering per uur voor resources zoals Amazon EBS-volumes en snapshots. Voor bedrijven waar downtime direct van invloed is op de omzet, worden deze kosten echter vaak als de moeite waard beschouwd. Voor minder kritieke systemen bieden actieve-passieve warm standby-configuraties mogelijk een economischer alternatief.
Implementatiecomplexiteit
Het opzetten van actieve-actieve redundantie is complexer dan standaard failover-modellen. Het vereist nauwkeurige wereldwijde synchronisatie, inclusief gesynchroniseerde caching (bijv., ElastiCache), geavanceerde verkeersroutering en het handhaven van consistente gegevens in verschillende regio's.
Gegevensconsistentie vormt een aanzienlijke uitdaging. Synchrone replicatie garandeert nauwkeurigheid, maar verhoogt de schrijfvertraging en is meestal beperkt tot één regio. Asynchrone replicatie ondersteunt herstel tussen regio's, maar introduceert vertraging, wat kan leiden tot verouderde gegevens. Om deze complexiteit te beheersen, kan Infrastructure as Code (IaC) netwerktopologieën en beveiligingsconfiguraties over regio's repliceren. Automatiseringstools en runbooks zorgen voor de promotie van de database en de routering van verkeer tijdens storingen. Amazon CloudWatch Het systeem verzamelt gegevens om te bepalen wanneer failover moet plaatsvinden.
Hersteltijddoelstelling (RTO)
Actieve-actieve redundantie levert een RTO gemeten in seconden, waardoor de downtime vaak vrijwel nul is. Omdat alle regio's al live verkeer verwerken, houdt failover simpelweg in dat de verkeersgewichten worden aangepast in plaats van te wachten tot resources zijn opgestart of databases zijn gepromoveerd. Tools zoals AWS Global Accelerator Gebruik statische IP-adressen die constant blijven, zelfs wanneer backend-endpoints uitvallen, waardoor snellere verkeersverschuivingen mogelijk zijn in vergelijking met op DNS gebaseerde failover-methoden.
| Dimensie | Actieve-actieve redundantie | Actief-passief (warme stand-by) |
|---|---|---|
| Betrouwbaarheid | Hoogste; actief verkeer in alle regio's. | Hoog; vereist succesvolle failover |
| Kostenefficiëntie | Het duurst; alle middelen beschikbaar in alle regio's. | Kosteneffectiever; secundaire regio verkleind. |
| Complexiteit | Hoog; wereldwijde gegevenssynchronisatie is nodig. | Gemiddelde moeilijkheidsgraad; geautomatiseerde failover-scripts vereist. |
| RTO | Vrijwel nul; het verkeer verandert onmiddellijk. | Minuten tot uren; afhankelijk van de schaalvergroting/promotie. |
Deze tabel belicht de belangrijkste verschillen tussen actief-actieve en actief-passieve configuraties en biedt een duidelijker beeld van de afwegingen die daarbij horen.
3. Actieve-passieve redundantie
Actieve-passieve redundantie Een actieve-passieve configuratie is een noodherstelconfiguratie waarbij uw primaire regio al het actieve verkeer afhandelt, terwijl een secundaire regio stand-by blijft en klaarstaat om het over te nemen indien nodig. Deze aanpak biedt een budgetvriendelijker alternatief voor actieve-actieve configuraties, maar brengt wel compromissen met zich mee, met name wat betreft de failover-snelheid. In tegenstelling tot actieve-actieve configuraties verwerkt de secundaire regio pas verzoeken wanneer er een storing optreedt. Er zijn twee hoofdtypen actieve-passieve configuraties: Pilootlicht, waardoor alleen essentiële resources zoals databases blijven draaien, en Warme standby, waardoor een lichtgewicht maar operationele versie van uw werkbelasting in de secundaire regio behouden blijft.
Betrouwbaarheid
Actieve-passieve configuraties zijn gebaseerd op continue gegevensreplicatie Om de betrouwbaarheid te garanderen, synchroniseert de primaire regio regelmatig gegevens met de secundaire regio. Deze gegevens worden beveiligd met encryptie en failover wordt geactiveerd door DNS-wijzigingen, die vaak worden gemonitord en geautomatiseerd via tools zoals CloudWatch.
Er zijn echter wel uitdagingen. De grootste zorg is replicatievertraging, waarbij data-updates mogelijk niet volledig gesynchroniseerd zijn tussen regio's. Sommige orchestratietools controleren niet automatisch op vertraging voordat een failover wordt geïnitieerd, wat betekent dat handmatige interventie nodig kan zijn om dataverlies te voorkomen. Na een failover vereist het systeem "omgekeerde replicatie" om de nieuw actieve regio te beschermen, wat niet automatisch gebeurt. Bovendien kan continue replicatie mislukken als de netwerkbandbreedte onvoldoende is, waardoor uw gegevens onbeschermd achterblijven.
Kostenefficiëntie
Actieve-passieve redundantie biedt een goede balans tussen kosten en prestaties. Het is voordeliger dan actieve-actieve configuraties, maar duurder dan eenvoudige back-up- en herstelmethoden. De kosten zijn afhankelijk van het type configuratie:
- Pilootlicht Hierdoor blijven de kosten laag doordat alleen essentiële resources zoals databases worden gebruikt, terwijl de rekenresources inactief blijven.
- Warme standby Dit is duurder omdat er een afgeschaalde versie van uw workload in de secundaire regio blijft draaien.
Andere terugkerende kosten zijn onder andere kosten voor gegevensoverdracht tussen regio's, opslagkosten bij Amazon EBS en uurkosten voor noodherstel. Om de kosten te optimaliseren, kunt u serverloze technologieën zoals AWS Lambda en Amazon API Gateway in de passieve regio gebruiken, waardoor u kosten voor inactieve computerbronnen vermijdt. Voor netwerken is VPC-peering een eenvoudigere en voordeligere optie dan Transit Gateway.
Implementatiecomplexiteit
Het opzetten van actieve-passieve redundantie vereist matige inspanning. Je moet DNS-omleiding configureren, geautomatiseerde failover-mechanismen instellen en een duidelijk proces definiëren voor het terugzetten van de activiteiten naar de primaire regio. Tools zoals AWS CloudFormation of HashiCorp Terraform kunnen de implementatie vereenvoudigen door te zorgen voor consistente resource-configuraties in alle regio's. Regelmatige failover-oefeningen zijn essentieel om te controleren of alles naar behoren werkt en om je team te trainen in het proces.
Het failbackproces voegt een extra laag complexiteit toe. Om terug te keren naar de primaire regio, moet u gegevens terug kopiëren vanuit de herstelregio, wat tijdrovend kan zijn. Dit houdt vaak in dat verouderde primaire databases worden verwijderd en nieuwe replica's worden aangemaakt. Het verbeteren van de beveiliging door kritieke gegevens te segmenteren in aparte AWS-accounts voor staging- en herstelregio's kan extra operationele overhead met zich meebrengen, waardoor herstelpogingen verder worden gecompliceerd. Deze factoren hebben uiteindelijk invloed op de hersteltijd, die we hierna zullen bespreken.
Hersteltijddoelstelling (RTO)
De RTO voor actieve-passieve configuraties hangt af van de gekozen strategie:
- Back-up maken en herstellenHet herstel duurt doorgaans tot 24 uur.
- Pilootlicht: Bereikt een RTO (Recovery Time Objective) van enkele tientallen minuten, omdat de benodigde rekenkracht tijdens het herstelproces moet worden toegewezen en opgeschaald.
- Warme standbyBiedt sneller herstel, vaak binnen enkele minuten, omdat de instanties al actief zijn en alleen nog maar opgeschaald hoeven te worden.
AWS Elastic Disaster Recovery is een handig hulpmiddel dat de kostenbesparingen van Pilot Light combineert met de snellere hersteltijden van Warm Standby.
Automatisering speelt een cruciale rol bij het verkorten van de RTO (Recovery Time Objective) door handmatige stappen te elimineren. Zo bepalen DNS TTL-instellingen en Route 53-routeringsupdates hoe snel gebruikers worden doorgestuurd naar de herstelregio. Daarnaast kan het gebruik van dataplane-API's de betrouwbaarheid van failover tijdens regionale storingen verbeteren, wat zorgt voor een soepelere overgang.
Voordelen en nadelen
Elke redundantiemethode kent zijn eigen afwegingen, waarbij kosten, complexiteit en herstelsnelheid tegen elkaar worden afgewogen. Hieronder een nadere blik op hoe deze methoden zich tot elkaar verhouden:
Failover tussen regio's Het is een solide keuze voor prioritaire workloads die ononderbroken bedrijfsactiviteiten vereisen tijdens regionale storingen. Het ondersteunt geautomatiseerde failover met een gedefinieerde hersteltijd (RTO). Deze handigheid is echter niet goedkoop. Gegevensoverdracht en -synchronisatie kunnen aanzienlijke kosten met zich meebrengen en het failbackproces kan complex zijn, met omgekeerde replicatie en handmatige opschoning. Zoals John Formento van Amazon Web Services opmerkt:
""Als de architectuur met meerdere regio's niet correct is opgezet, kan de algehele beschikbaarheid van de workload afnemen.""
Actieve-actieve redundantie Het biedt een razendsnel herstel met een bijna nul RTO (Recovery Time Objective) en zorgt ervoor dat gebruikers worden bediend vanuit de dichtstbijzijnde geografische locatie. Deze configuratie is ideaal voor een wereldwijd publiek dat topprestaties nodig heeft. Aan de andere kant drijft het onderhouden van volledig operationele applicatiestacks in meerdere regio's de kosten op. Gegevenssynchronisatie kan ook een probleem vormen en een slecht ontworpen systeem kan onbedoeld de algehele beschikbaarheid verminderen.
Actieve-passieve redundantie Een meer budgetvriendelijke optie is het gebruik van warm standby- of pilot light-configuraties om kosten te besparen. Omdat u niet betaalt voor inactieve computerbronnen, is het voordeliger. Bovendien verstoren failover-oefeningen de primaire omgeving niet. Het nadeel? Een hogere RTO (Recovery Time Objective) vergeleken met actieve-actieve configuraties. Herstel is afhankelijk van hoe snel passieve resources kunnen schalen en DNS-verkeer kan worden omgeleid. Daarnaast is het beheren van datareplicatie cruciaal om problemen zoals replicatievertraging te voorkomen, wat kan leiden tot dataverlies tijdens een failover.
| Redundantiemethode | Belangrijkste voordelen | Belangrijkste nadelen |
|---|---|---|
| Failover tussen regio's | Geautomatiseerd herstel; gedefinieerde RTO; waarborgt bedrijfscontinuïteit | Hoge kosten voor gegevensoverdracht; complex failbackproces; risico op gegevensverlies door replicatievertraging |
| Actief-Actief | Vrijwel nul RTO; verbetert de algehele prestaties; hoogste beschikbaarheid | Duur; lastige gegevenssynchronisatie; potentieel verminderde beschikbaarheid bij verkeerde configuratie. |
| Actief-Passief | Kostenefficiënt; de boorwerkzaamheden hebben geen invloed op de primaire systemen; sneller dan koude back-ups. | Hogere RTO dan actief-actief; vereist zorgvuldig replicatiebeheer om gegevensverlies te voorkomen. |
Deze analyse belicht de belangrijkste overwegingen bij het kiezen van de beste redundantiestrategie voor uw rampenherstelplan. Elke methode heeft zijn sterke en zwakke punten, waardoor de juiste keuze sterk afhangt van uw specifieke behoeften en prioriteiten.
Conclusie
De keuze voor de juiste redundantiemethode hangt af van uw bedrijfsbehoeften en de kritische aard van uw systemen. missiekritieke systemen (Tier 0), waar zelfs een paar seconden downtime onaanvaardbaar is, actieve-actieve redundantie Dat is de juiste aanpak. Deze systemen vereisen vaak Service Level Objectives (SLO's) van 99,999% of hoger en Recovery Time Objectives (RTO's) die in feite nul zijn.
Voor matig kritieke systemen (Tier 1), waar korte onderbrekingen beheersbaar zijn, een actief-passief warm standby Deze configuratie biedt een goede middenweg tussen kosten en snel herstel. Deze methode is met name effectief voor klantgerichte applicaties die betrouwbare prestaties vereisen zonder al te veel geld uit te geven. Regelmatig testen is echter cruciaal om ervoor te zorgen dat uw noodherstelplan werkt wanneer het het meest nodig is.
Als het gaat om operationele systemen (Tier 2), waar langere RTO's van een paar uur acceptabel zijn, actieve-passieve koude standby biedt een kostenefficiënte optie. Op dezelfde manier, administratieve werklast (niveau 3) Vaak wordt er gebruikgemaakt van back-up- en herstelmethoden, waarbij de hersteltijden variëren van uren tot dagen. Deze gelaagde strategieën vormen de basis van een robuust rampenherstelplan.
Om deze strategieën naadloos te laten werken, stemt u uw redundantiemethoden af op de kritikaliteit van uw workloads. Beheerde services kunnen dit proces vereenvoudigen door redundantie- en replicatietaken te automatiseren. Het automatiseren van failovermechanismen is een andere belangrijke stap om downtime te verminderen. Zoals het Microsoft Azure Well-Architected Framework adviseert:
""Meer redundantie in de werkbelasting betekent hogere kosten. Overweeg zorgvuldig het toevoegen van redundantie en evalueer uw architectuur regelmatig om ervoor te zorgen dat u de kosten beheersbaar houdt.""
Begin met het categoriseren van uw workloads in niveaus en stel duidelijke RTO- en Recovery Point Objective (RPO)-doelen vast voor elk niveau. De meest effectieve aanpak is niet per se de duurste, maar degene die een balans biedt tussen bescherming en duurzaamheid.
Voor operationele veerkracht kunt u overwegen samen te werken met Serverion. Met hun hosting in meerdere regio's kunt u ononderbroken werking garanderen, zelfs tijdens regionale verstoringen, zodat uw kritieke systemen altijd operationeel blijven, wat er ook gebeurt.
Veelgestelde vragen
Welke kosten moet ik in overweging nemen bij het opzetten van failover tussen regio's voor noodherstel?
Het opzetten van failover tussen regio's brengt diverse kosten met zich mee die zorgvuldig overwogen moeten worden. Een aanzienlijke kostenpost is verbonden aan computerbronnen in de secundaire regio. Als u kiest voor een warm-standby- of hot-standby-configuratie, krijgt u te maken met hogere kosten vanwege het draaien van extra instanties, opslag en licentievereisten. Een cold-standby-configuratie is daarentegen over het algemeen voordeliger, omdat deze voornamelijk bestaat uit het bewaren van gerepliceerde gegevens zonder dat er continu instanties hoeven te draaien.
Een andere belangrijke kostenpost waarmee rekening moet worden gehouden, is gegevensreplicatieopslag, wat in elke regio apart in rekening wordt gebracht. Door te kiezen voor regio's met lagere opslagkosten kunnen deze kosten beheersbaar blijven. Daarnaast, kosten voor gegevensoverdracht tussen regio's Deze kosten zijn van toepassing op doorlopende datareplicatie en al het verkeer dat tijdens failover-gebeurtenissen wordt gegenereerd. Bij grote datasets kunnen deze kosten snel oplopen.
Je moet ook rekening houden met het volgende: beheer- en licentiekosten voor tools voor noodherstel, monitoringsystemen en alle externe diensten waarop u vertrouwt. Om de kosten effectief te beheren, hanteren veel organisaties een gelaagde aanpak. Zo houden ze bijvoorbeeld alleen kritieke diensten in een warm-standby-status, gebruiken ze kostenefficiënte opslagoplossingen en plannen ze het bandbreedtegebruik zorgvuldig op basis van de hersteldoelen.
Door specifieke waarden toe te kennen aan deze kostencomponenten – zoals instantietarieven (bijv. $0.10/uur), opslagkosten (bijv. $0.023/GB per maand) en kosten voor gegevensoverdracht (bijv. $0.02/GB) – kunnen bedrijven een failoverstrategie ontwikkelen die een balans biedt tussen betrouwbaarheid en betaalbaarheid.
Hoe verbetert failover tussen regio's de betrouwbaarheid van gegevens tijdens regionale storingen?
Failover tussen regio's zorgt ervoor dat uw gegevens toegankelijk blijven door een veilige verbinding te behouden. gesynchroniseerde back-up in een secundaire regio. Als de primaire regio door een storing offline gaat, wordt het verkeer naadloos omgeleid naar de secundaire regio. Dit betekent dat gebruikers zonder onderbrekingen toegang blijven houden tot de meest recente gegevens.
Deze methode speelt een cruciale rol in rampenherstelplannen en helpt bedrijven bij het behalen van hun doelen. hoge beschikbaarheid en het verminderen van de downtime tijdens regionale storingen. Door data te repliceren over verschillende locaties kunnen bedrijven hun activiteiten beschermen en gebruikers een consistente ervaring bieden, ongeacht wat er gebeurt.
Waar moet ik op letten bij de keuze tussen een actieve-actieve en een actieve-passieve redundantieconfiguratie?
Bij het kiezen tussen actief-actief en actief-passief Bij het opzetten van redundantiesystemen is het belangrijk om factoren zoals kosten, prestatie-eisen en operationele complexiteit af te wegen.
Een actieve-passieve configuratie is over het algemeen budgetvriendelijker. Het maakt gebruik van een primaire server met een standby-server, waardoor het eenvoudig te implementeren en te onderhouden is. Aan de andere kant, een actieve-actieve configuratie Dit brengt hogere kosten met zich mee, omdat de infrastructuur verdubbelt en er meer inspanning nodig is om het te beheren.
Prestatie-eisen en tolerantie voor uitvaltijd zijn eveneens cruciale overwegingen. Actieve-actieve configuraties Ze blinken uit in omgevingen met veel verkeer waar consistente prestaties essentieel zijn. Door het verkeer over alle knooppunten te verdelen, elimineren ze failover-vertragingen. Voor kleinere applicaties of systemen met een gemiddelde belasting is een andere oplossing echter minder geschikt. actieve-passieve configuratie is vaak voldoende en gemakkelijker te hanteren.
Denk ten slotte na over de capaciteit van je team en hoeveel downtime acceptabel is. Actief-actieve systemen Dit vereist geavanceerd beheer en synchronisatie, waarvoor mogelijk meer geschoolde medewerkers nodig zijn. Ondertussen, actief-passieve opstellingen zijn eenvoudiger en werken goed voor teams met beperkte middelen of teams die korte uitvalperioden kunnen opvangen. Beide opties kunnen worden aangepast om de juiste balans te vinden tussen kosten, prestaties en beschikbaarheid voor uw specifieke behoeften.




