
Geen downtime dankzij redundantie van de load balancer.
Uitval is kostbaar. Voor grote bedrijven kan elke minuut offline $9.000 kosten, of $540.000 per uur. Naast financiële verliezen kan zelfs een vertraging van 1 seconde gebruikers wegjagen, en het niet nakomen van uptime-beloftes schaadt het vertrouwen en leidt tot boetes voor schending van de serviceovereenkomst (SLA). Het bereiken van hoge beschikbaarheid met load balancer redundantie is de sleutel tot het vermijden van dergelijke risico's.
Zo werkt het:
- Ontslag Dit houdt in dat er meerdere load balancers worden ingezet om single points of failure te elimineren.
- Failover-systemen Zorg ervoor dat het verkeer naadloos wordt omgeleid als een load balancer uitvalt.
- Actief-passief en actief-actief De verschillende configuraties zijn de belangrijkste redundantiemodellen, elk geschikt voor verschillende behoeften.
- Hulpmiddelen zoals gezondheidscontroles, sessiepersistentie en statussynchronisatie zorgen voor een soepele werking tijdens failover.
Praktische voorbeelden, van de storing bij British Airways tot wereldwijde softwarecrashes, laten zien waarom redundantie cruciaal is. Met de juiste strategie kunt u verstoringen voorkomen, de uptime garanderen en uw reputatie beschermen.
38 Single Point of Failure en redundantie (Volledige cursus Load Balancer Essentials)
Hoe werkt redundantie in load balancers?
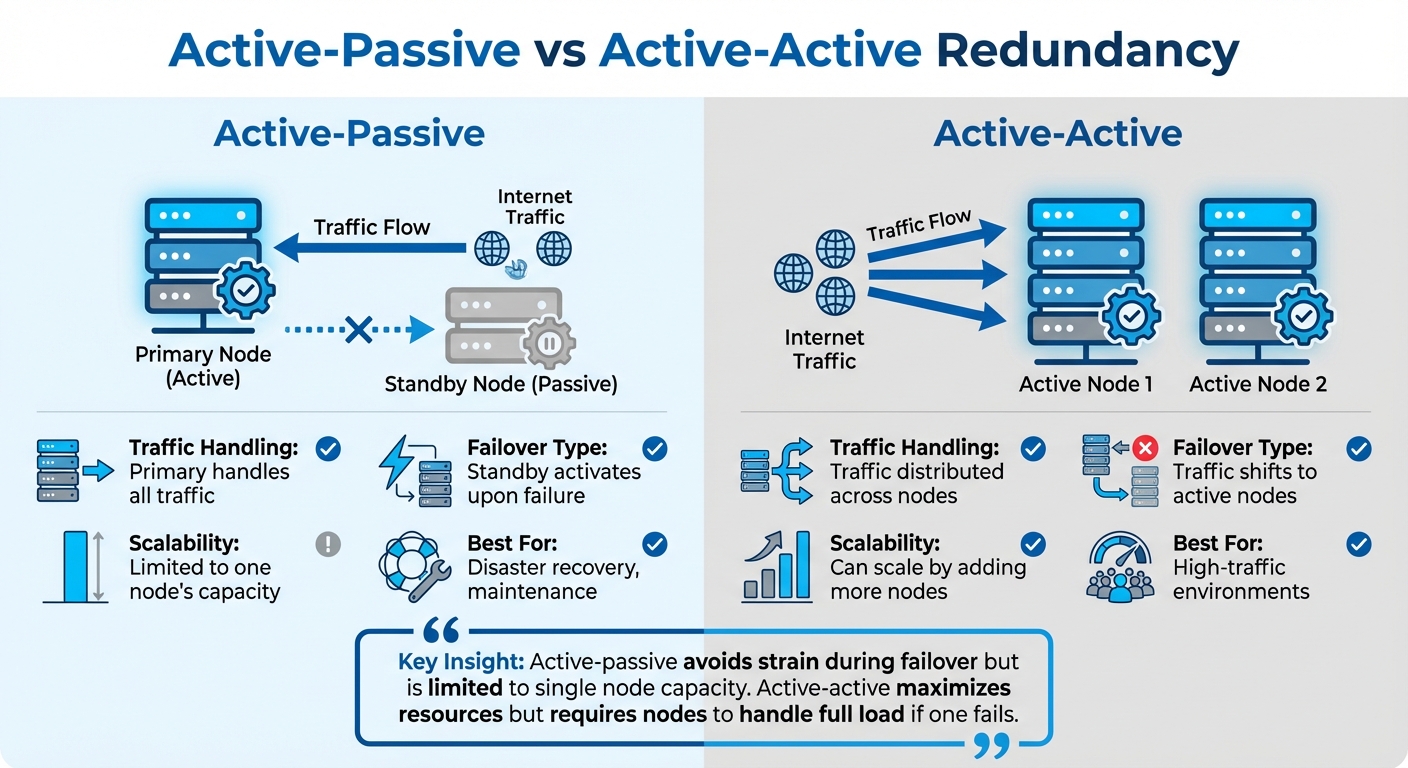
Vergelijking van redundantie tussen actieve en passieve loadbalancers en actieve en actieve loadbalancers
Redundantie in loadbalancers zorgt voor een ononderbroken dienstverlening door problemen te detecteren en verkeer automatisch om te leiden. Laten we de verschillende redundantiemodellen eens nader bekijken en zien hoe health checks en synchronisatie ervoor zorgen dat alles soepel blijft verlopen.
Actieve-passieve versus actieve-actieve redundantie
In actieve-passieve redundantie, Een primaire load balancer beheert het verkeer, terwijl een back-up load balancer stand-by blijft en direct de taken kan overnemen als de primaire load balancer uitvalt. Deze aanpak maakt vaak gebruik van stateful failover, waarbij actieve gebruikerssessies in realtime worden gemonitord om naadloze overgangen te garanderen zonder dat verbindingen worden verbroken.
Anderzijds, actieve-actieve redundantie Verdeelt het verkeer over alle beschikbare knooppunten. Deze configuratie is ideaal voor omgevingen met veel verkeer, omdat het het resourcegebruik maximaliseert. Als echter één knooppunt uitvalt, moeten de overgebleven knooppunten de volledige belasting overnemen, wat tot overbelasting kan leiden als ze al bijna hun maximale capaciteit hebben bereikt. Actieve-passieve configuraties voorkomen dit probleem, maar zijn tijdens een failover beperkt tot de capaciteit van het enige actieve knooppunt.
| Functie | Actief-Passief | Actief-Actief |
|---|---|---|
| Verkeersafhandeling | Primary verwerkt al het verkeer. | Verkeer verdeeld over knooppunten |
| Failovertype | De standby-modus wordt geactiveerd bij een storing. | Het verkeer verschuift naar actieve knooppunten. |
| Schaalbaarheid | Beperkt tot de capaciteit van één knooppunt | Kan worden opgeschaald door meer knooppunten toe te voegen. |
| Beste voor | Rampenbestrijding, onderhoud | Omgevingen met veel verkeer |
Gezondheidscontroles en failovermechanismen
Gezondheidscontroles zijn essentieel voor het bewaken van de responsiviteit van load balancers en servers. Deze controles komen in twee vormen voor:
- Actieve gezondheidscontrolesDeze versturen regelmatig testverzoeken (vaak "hartslagen" genoemd) om de systeemstatus te controleren, meestal elke 5 tot 30 seconden.
- Passieve gezondheidscontrolesDeze systemen monitoren live gebruikerstransacties en detecteren fouten zonder extra dataverkeer te genereren.
Wanneer een probleem wordt gedetecteerd, treedt het failovermechanisme in werking en wordt het verkeer omgeleid naar functionerende resources. De duur van een storing tijdens failover is afhankelijk van de DNS Time-to-Live (TTL)-instelling en het interval voor de statuscontrole. Voor een snel herstel wordt een DNS TTL van 30 tot 60 seconden aanbevolen, zodat clients snel bijgewerkte IP-adressen ontvangen.
Aansluiting afwatering Dit speelt een cruciale rol bij het voorkomen van abrupte onderbrekingen. Dit proces zorgt ervoor dat lopende sessies op natuurlijke wijze binnen een bepaalde tijd (meestal 300 seconden) worden afgesloten, terwijl nieuwe verbindingen naar functionerende knooppunten worden doorgestuurd.
Statussynchronisatie en sessiepersistentie
Failover gaat niet alleen over het omleiden van verkeer, maar vereist ook het behoud van sessiecontinuïteit. Om dit te bereiken, moeten load balancers hun configuraties synchroniseren over redundante knooppunten. Hoewel moderne cloud load balancers werken als stateless services en geen applicatiegegevens opslaan of repliceren, repliceren ze wel configuratie-instellingen zoals load balancing-regels, health probes en lidmaatschappen van backendpools. Deze synchronisatie zorgt voor consistentie in alle beschikbaarheidszones.
""Load Balancer is een netwerkdoorvoerservice die geen applicatiegegevens opslaat of repliceert. Zelfs als u sessiepersistentie inschakelt op de load balancer, wordt er geen status op de load balancer opgeslagen." – Azure-documentatie
Sessiepersistentie Dit zorgt ervoor dat verzoeken van dezelfde client consistent naar dezelfde backend-instantie worden doorgestuurd. Dit wordt doorgaans bereikt met behulp van hash-algoritmen, zoals een 5-tuple flow hash (bron-IP, poort, protocol, bestemmings-IP, bestemmingspoort), in plaats van het opslaan van sessiestatus.
Om redundantie naadloos te laten werken, moeten de configuraties van de primaire en back-up load balancers identiek zijn. SSL-certificaten, beveiligingsbeleid en instellingen voor verkeersbeheer moeten overeenkomen om een consistente verwerking te garanderen, ongeacht welke load balancer actief is. Tools zoals Terraform kunnen deze synchronisatie automatiseren, waardoor het risico op fouten tijdens failover wordt verkleind.
Veelvoorkomende faalscenario's en hoe redundantie deze oplost.
Zelfs de meest betrouwbare infrastructuren kunnen storingen vertonen, maar redundantie helpt ervoor te zorgen dat de bedrijfsvoering soepel blijft verlopen.
Hardware- en softwarefouten
Hardware kan onverwacht uitvallen. Problemen zoals stroomuitval, storingen in het koelsysteem, En slijtage van de hardware kan load balancer-nodes binnen een beschikbaarheidszone platleggen. Aan de softwarekant kunnen problemen zoals proces crasht, kernelpanieken, of SNAT-poortuitputting kan net zulke ernstige verstoringen van de dienstverlening veroorzaken.
Zoneredundantie Deze uitdagingen worden aangepakt door load balancer-nodes te verdelen over meerdere fysiek gescheiden beschikbaarheidszones. Als de hardware in één zone uitvalt, nemen nodes in andere zones de taken over, waardoor de verkeersstroom blijft doorgaan. Om een hoge beschikbaarheid te garanderen, is het bovendien essentieel om meerdere gezonde backend-instanties paraat te hebben om de belasting op te vangen.
Bij softwareproblemen zoals het uitputten van SNAT-poorten is het monitoren van poortgebruik cruciaal. Zelfs een ogenschijnlijk goed functionerende load balancer kan uitvallen als er geen poorten meer beschikbaar zijn voor verbindingen. Oplossingen hiervoor zijn onder andere handmatige poorttoewijzing of het gebruik van NAT-gateways om deze knelpunten te voorkomen. Continue monitoring van poorten en de netwerkstatus kan helpen voorkomen dat dergelijke problemen escaleren.
Deze strategieën leggen de basis voor bredere oplossingen die netwerk- en geografische uitdagingen aanpakken.
| Type storing | Specifiek scenario | Redundantieoplossing |
|---|---|---|
| Hardware | Fysieke knooppuntstoring / Stroomuitval | Multi-node clusters / Zone-redundante implementatie |
| Software | Load balancer-proces crasht | Failover via actieve-passieve configuratie met behulp van health probes |
| Configuratie | SNAT-poortuitputting | Handmatige poorttoewijzing / Uitgaande regels |
| Vergankelijk | Intermitterende API-/netwerkstoringen | Logica voor opnieuw proberen aan de clientzijde / Exponentiële backoff |
Netwerkredundantie
Problemen op netwerkniveau kunnen ook de dienstverlening verstoren. Connectiviteitsproblemen kunnen een complete beschikbaarheidszone isoleren, waardoor gebruikers geen toegang meer hebben tot functionerende backendservers. Een enkel storingspunt in het netwerkpad kan verstrekkende gevolgen hebben.
Zoneoverschrijdende taakverdeling Dit zorgt ervoor dat elk load balancer-knooppunt verkeer naar alle geregistreerde doelen kan routeren, ongeacht de zone. Dit voorkomt een ongelijke verkeersverdeling wanneer één zone netwerkproblemen ondervindt. Bovendien geven gezondheidscontroles vanuit meerdere regio's (doorgaans drie) een nauwkeuriger beeld van de netwerkconnectiviteit.
De failover-ratio Deze instelling bepaalt wanneer verkeer wordt omgeleid naar back-uppools. Als de verhouding bijvoorbeeld op 0,1 wordt ingesteld, wordt failover alleen geactiveerd wanneer er minder dan 10% aan primaire instanties gezond blijven. Dit voorkomt onnodige failovers tijdens kleine netwerkproblemen en biedt tegelijkertijd bescherming tegen grote storingen.
Geografische redundantie
Regionale stroomuitval, of deze nu wordt veroorzaakt door natuurrampen, storingen in het elektriciteitsnet of infrastructuurproblemen, kan alle voorzieningen in een bepaald gebied platleggen.
Wereldwijde load balancers Deze oplossing maakt gebruik van één enkel anycast IP-adres om verkeer naar de dichtstbijzijnde, goed functionerende regio te routeren. In tegenstelling tot DNS-gebaseerde failover, die afhankelijk is van TTL-instellingen en caching aan de clientzijde, werkt anycast-routing direct op netwerkniveau. Dit zorgt ervoor dat verkeer zonder vertraging wordt omgeleid. Bovendien werken regionale externe loadbalancers onafhankelijk van elkaar, waardoor een storing in één regio geen gevolgen heeft voor de gehele infrastructuur.
De Overbevoorradingspatroon Dit zorgt ervoor dat andere regio's het toegenomen verkeer kunnen verwerken wanneer één regio offline gaat. Door extra capaciteit in alle regio's te behouden, elimineert u de vertraging die automatisch schalen met zich meebrengt, waardoor de prestaties stabiel blijven tijdens storingen. Tools zoals Terraform kunnen het synchroniseren van SSL-certificaten, beveiligingsbeleid en verkeersbeheerinstellingen in alle regio's automatiseren, wat consistentie en betrouwbaarheid garandeert.
sbb-itb-59e1987
Het bouwen van een load balancer-architectuur zonder downtime.
Het opzetten van een load balancer met nul downtime vereist duidelijke uptime-doelen, het kiezen van het juiste redundantiemodel en het grondig testen van failoverprocessen. Deze elementen vormen de basis van een betrouwbare architectuur, zoals hieronder wordt uitgelegd.
Het instellen van uptime-doelen en SLA's
Uw beoogde uptime is de hoeksteen van uw architectuur en vormt de basis van elke beslissing. Elke extra "negen" in beschikbaarheid – zoals bijvoorbeeld bij een overstap van... 99.9% naar 99.99% Beschikbaarheid – voegt complexiteit en kosten toe. Ter context:
- A 99.9% SLA Dit staat ongeveer 8,76 uur downtime per jaar toe, wat voldoende kan zijn voor interne tools.
- A 99.99% SLA Dat reduceert dat tot ongeveer 52,6 minuten per jaar, een gangbare maatstaf voor klantgerichte applicaties.
- A 99.999% SLA Dit beperkt de downtime tot slechts 5 minuten per jaar en vereist actieve-actieve redundantie in meerdere regio's.
Deze uptime-doelstellingen hebben directe invloed op het ontwerp van uw load balancer. Met bijna 501.000 bedrijven die melden dat de kosten van downtime meer dan 1.000.000 per uur bedragen, is het afstemmen van SLA-verplichtingen op infrastructuurinvesteringen niet onderhandelbaar.
Het juiste redundantiemodel kiezen
De keuze tussen actief-actief en actief-passief De mate van redundantie hangt af van de behoeften van uw systeem en de hersteldoelstellingen.
- Actieve-actieve redundantie is ideaal voor bedrijfskritische systemen. Meerdere instanties verwerken het verkeer gelijktijdig, waardoor de hersteltijd (RTO) vrijwel nul is. Netflix gebruikt deze aanpak bijvoorbeeld door microservices te implementeren in meerdere AWS-regio's. Hun tool "Chaos Monkey" schakelt willekeurig productieservices uit om de failover-gereedheid te testen, waardoor een ononderbroken dienstverlening voor meer dan 230 miljoen abonnees wordt gegarandeerd.
- Actieve-passieve redundantie Dit werkt voor systemen die korte onderbrekingen kunnen verdragen. Hierbij wordt een reserve-exemplaar paraat gehouden om bij een storing op te schalen. Koude reserveonderdelen, Hoewel ze kosteneffectiever zijn, vereisen ze wel opstartresources tijdens een storing, wat leidt tot langere hersteltijden. Code.org heeft bijvoorbeeld met succes een verkeerspiek van 4001 TP3T tijdens grote online codeerevenementen beheerd met behulp van AWS Application Load Balancers. Dit laat zien hoe een juiste configuratie hoge beschikbaarheid ondersteunt, zelfs onder extreme omstandigheden.
Zodra u het redundantiemodel hebt gekozen, is continue monitoring essentieel om ervoor te zorgen dat het systeem onder belasting naar behoren functioneert.
Monitoring en testen op storingen
Het verschil tussen een theoretisch ontwerp en een robuuste architectuur zit hem in continue monitoring en proactieve tests. Ga verder dan de standaard TCP-controles door het implementeren van diepgaande gezondheidssondes om kritieke afhankelijkheden zoals databaseverbindingen en externe API's te controleren. Voeg een /gezondheid Gebruik een eindpunt in uw applicatie om te bevestigen dat de interne systemen functioneren voordat een 200 OK-status wordt geretourneerd. Voer gezondheidscontroles uit vanuit ten minste drie regio's om wereldwijde bereikbaarheid te garanderen.
Besteed aandacht aan poorttoewijzing en configureer handmatige poorttoewijzingen of NAT-gateways indien nodig. Houd de DNS TTL laag – tussen 30 en 60 seconden – zodat de maximale uitvalduur gelijk is aan de DNS TTL plus het interval voor de gezondheidscontrole vermenigvuldigd met de drempelwaarde voor ongezonde verbindingen.
Chaos engineering-tools zoals Azure Chaos Studio kunnen realistische storingen simuleren, zoals zone-uitval of het beëindigen van instanties, om failover-mechanismen te testen. Vergeet niet om de resultaten te valideren. failback-proces – ervoor zorgen dat het verkeer na herstel naadloos terugkeert naar het primaire knooppunt. Daarnaast exponentiële backoff met willekeurige jitter implementeren in de client-retry-logica om "retry-storms" tijdens gedeeltelijke storingen te voorkomen.
Hoe Serverion Ondersteunt hoge beschikbaarheid.

Wereldwijd datacenternetwerk
Serverion beheert een netwerk van datacenters die strategisch over de hele wereld zijn geplaatst. Dit zorgt voor geografische redundantie en beschermt tegen volledige uitval van datacenters. Dankzij loadbalancers die in deze regio's zijn ingezet, wordt het verkeer automatisch naar het dichtstbijzijnde operationele datacenter geleid. Zo kan een gebruiker in New York bijvoorbeeld indien nodig worden doorgestuurd naar een datacenter in Virginia. Of u nu kiest voor een actief-actief configuratie – waarbij meerdere regio's tegelijkertijd verkeer verwerken – of een actief-passief Dankzij de configuratie met stand-byfaciliteiten die klaarstaan om de taken over te nemen bij storingen, zorgt de infrastructuur van Serverion voor een soepele omleiding van gebruikers zonder dat handmatige DNS-updates nodig zijn. Dit ontwerp integreert naadloos met redundantiestrategieën en biedt ononderbroken service in alle regio's.
Hostingoplossingen voor redundante architecturen
Serverion biedt een reeks hostingoplossingen die specifiek zijn ontworpen voor architecturen met hoge beschikbaarheid. Hun schaalbare VPS-opties bieden volledige root-toegang, ideaal voor het creëren van aangepaste load balancing-configuraties. Voor applicaties die een hogere bandbreedte en dedicated resources vereisen, beschikken hun dedicated servers over dedicated IPv4-adressen om zwaar verkeer efficiënt af te handelen.
Voor diegenen die nauwkeurige controle over de plaatsing van hardware vereisen, bieden de colocatiediensten van Serverion de mogelijkheid om apparatuur over meerdere locaties te verdelen. Dit elimineert single points of failure en maakt het mogelijk om load balancing-nodes over verschillende datacenters te verspreiden. Deze aanpak is met name effectief voor actieve-actieve configuraties, waarbij prestaties en aanpassingsmogelijkheden op elk niveau van de stack cruciaal zijn.
Ondersteunende functies voor nul downtime
Het handhaven van redundantie in loadbalancers vereist een sterke onderliggende infrastructuur om escalerende storingen te voorkomen. De DNS-hosting van Serverion, uitgerust met lage TTL-instellingen, zorgt voor een snelle omleiding van verkeer naar functionerende servers tijdens failovers. Hun DDoS-beschermingssysteem verdeelt aanvalsverkeer over meerdere knooppunten, waardoor overbelasting die de dienstverlening zou kunnen verstoren, wordt voorkomen.
Om de betrouwbaarheid verder te verbeteren, biedt Serverion betaalbare SSL-certificaten voor veilige verbindingen en 24/7 serverbeheer voor proactieve monitoring van de serverstatus. Functies zoals het afvloeien van verbindingen stellen actieve gebruikers in staat hun sessies ongestoord af te ronden tijdens onderhoud, terwijl geautomatiseerde statuscontroles – die elke 10 seconden worden uitgevoerd – snel problemen detecteren en failoverprocessen initiëren. Samen zorgen deze tools voor een naadloze ervaring zonder downtime.
Conclusie
Het garanderen van redundantie in de load balancer is cruciaal voor het behoud van een ononderbroken dienstverlening. Zoals Dave Patten, architect en adviseur, het treffend verwoordt:
""Ontwerpen voor hoge beschikbaarheid (HA) en noodherstel (DR) is niet alleen een technische noodzaak, maar ook een strategische vereiste.""
Door middel van actieve-passieve of actieve-actieve configuraties kunnen storingen op één punt worden geëlimineerd, waardoor services operationeel kunnen blijven, zelfs bij storingen in hardware, netwerk of datacenter.
De kern van redundantie wordt gevormd door een paar belangrijke praktijken: het gebruik van Virtuele IP-adressen Voor naadloze failover, continue monitoring van de systeemstatus om potentiële problemen vroegtijdig op te sporen en het distribueren van infrastructuur over meerdere zones of regio's. Zo kunnen VRRP-gebaseerde failovers onderbrekingen tot slechts een seconde beperken – nauwelijks merkbaar voor eindgebruikers. Systemen die streven naar een uptime van 99,991 TP3T laten zien hoe redundantie grote storingen kan omzetten in kleine, beheersbare gebeurtenissen die uw klanten niet eens merken.
Het wereldwijde netwerk van Serverion is een uitstekend voorbeeld van deze aanpak, met datacenters verspreid over meerdere regio's voor geografische redundantie. Of u nu aangepaste load balancing-configuraties beheert op hun VPS-platforms met volledige root-toegang, dedicated servers inzet voor toepassingen met veel verkeer, of colocatiediensten gebruikt om hardware over verschillende locaties te verdelen, de infrastructuur is ontworpen om downtime tot een minimum te beperken. Hun DNS-hosting zorgt voor snelle omleiding van verkeer tijdens failovers en de ingebouwde DDoS-bescherming beschermt tegen aanvallen die uw redundante systemen zouden kunnen overbelasten.
Een echt veerkrachtige architectuur omvat geautomatiseerde gezondheidscontroles, het afhandelen van verbindingen en continue monitoring. Dankzij deze maatregelen verstoren onderhoudsvensters de bedrijfsvoering niet langer en worden hardwarestoringen routineproblemen die uw systeem naadloos afhandelt. Dit soort planning zorgt ervoor dat uw gebruikers kunnen rekenen op een consistente service, ongeacht wat er achter de schermen gebeurt. Naast het verminderen van downtime versterkt deze strategie de reputatie van uw organisatie op het gebied van betrouwbaarheid.
Veelgestelde vragen
Wat is het verschil tussen actieve-passieve en actieve-actieve load balancer-redundantie?
Als het om redundantie gaat, zijn er twee populaire benaderingen: actief-passief en actief-actief opstellingen.
In een actieve-passieve configuratie, A primaire lastverdeler beheert al het verkeer terwijl een stand-by-eenheid De standby-eenheid blijft inactief en staat klaar om in te springen als de primaire eenheid uitvalt. Hoewel deze configuratie eenvoudig en gemakkelijk te beheren is, brengt het wel een korte onderbreking met zich mee tijdens het failoverproces. Een nadeel is dat de standby-eenheid tijdens normaal gebruik ongebruikt blijft, wat kan aanvoelen als een gemiste kans voor resourcebenutting.
Aan de andere kant, een actieve-actieve configuratie houdt in meerdere load balancers Door gelijktijdig samen te werken, wordt het verkeer efficiënt verwerkt. Deze aanpak benut de beschikbare resources optimaal, vermindert de latentie en zorgt voor een soepele overgang met minimale verstoring als een load balancer uitvalt. De configuratie is echter complexer en vereist functies zoals gesynchroniseerde sessiegegevens of gedeelde IP-adressen om alles consistent te houden en potentiële problemen te voorkomen.
Serverion biedt ondersteuning voor beide modellen, waardoor u flexibel kunt kiezen tussen de eenvoud van actief-passief of de hogere prestaties en betrouwbaarheid van actief-actief, afhankelijk van de behoeften van uw toepassing.
Hoe voorkomen load balancer health checks en failover-systemen downtime?
De health checks van de load balancer houden de backendservers constant in de gaten door kleine tests uit te voeren, zoals TCP-handshakes of HTTP-verzoeken, om te controleren of ze correct functioneren. Als een server naar verwachting reageert, blijft deze in de rotatie om het verkeer af te handelen. Maar als meerdere controles achter elkaar mislukken, wordt de server tijdelijk verwijderd totdat deze de tests opnieuw kan doorstaan. Dit proces zorgt ervoor dat alleen functionerende servers het verkeer afhandelen, waardoor de kans op serviceonderbrekingen wordt verkleind.
Failovermechanismen vullen deze gezondheidscontroles aan door het verkeer om te leiden wanneer er problemen optreden. In een actief-passief De configuratie zorgt ervoor dat het verkeer wordt overgezet naar een back-upserverpool als de primaire server offline gaat. Ondertussen, in actief-actief Dankzij deze configuraties verwerken meerdere servers tegelijkertijd het verkeer, en wordt de belasting van een uitvallende server automatisch verdeeld over de gezonde servers. Samen zorgen deze systemen ervoor dat load balancers services soepel blijven draaien, waardoor platforms zoals Serverion Betrouwbare prestaties leveren en uitval voor hun gebruikers voorkomen.
Hoe draagt geografische redundantie bij aan een ononderbroken dienstverlening?
Geografische redundantie houdt in dat loadbalancers en servers over meerdere datacenters op verschillende locaties worden verspreid om de dienstverlening soepel te laten verlopen. Deze opzet zorgt ervoor dat als één locatie problemen ondervindt – zoals een stroomstoring, een netwerkprobleem of zelfs een natuurramp – de dienstverlening niet volledig stilvalt. In plaats daarvan wordt het verkeer automatisch omgeleid naar functionerende regio's, zodat gebruikers ononderbroken toegang hebben.
Serverion brengt dit concept in de praktijk door datacenters over de hele wereld te beheren. Hun infrastructuur maakt het mogelijk om workloads over verschillende geografische zones te verdelen. Als een locatie uitvalt, verplaatst hun systeem het verkeer onmiddellijk naar een andere locatie, waardoor de betrouwbare uptime wordt gegarandeerd die moderne applicaties vereisen.




