
Proactieve versus reactieve schaalvergroting: de belangrijkste verschillen
Als het gaat om het beheren van systeemprestaties en -kosten, zijn schaalstrategieën cruciaal. De twee belangrijkste benaderingen zijn: proactieve schaalvergroting en reactieve schaling – elk heeft zijn eigen voordelen en uitdagingen. Hier volgt een kort overzicht:
- Proactieve schaalvergroting: Maakt planningen mogelijk op basis van historische gegevens of voorspellingen om middelen toe te wijzen voordat de vraag toeneemt. Ideaal voor voorspelbare verkeerspatronen zoals openingstijden van bedrijven of seizoensgebonden evenementen.
- Reactieve schaalvergrotingReageert op pieken in de vraag in realtime door extra resources toe te voegen wanneer drempelwaarden (bijv. hoog CPU-gebruik) worden overschreden. Het meest geschikt voor onverwachte of onregelmatige pieken.
Belangrijkste punten:
- Proactieve schaalvergroting zorgt ervoor dat systemen van tevoren worden voorbereid, maar vereist nauwkeurige voorspellingen.
- Reactief schalen is flexibel en efficiënt bij plotselinge pieken, maar kan last hebben van vertragingen tijdens de toewijzing van resources.
- Het combineren van beide strategieën levert vaak de beste balans op tussen betrouwbaarheid en kostenefficiëntie.
Hieronder volgt een vergelijking van de twee benaderingen:
| Functie | Proactieve schaalvergroting | Reactieve schaalvergroting |
|---|---|---|
| Trekker | Verwachte vraag | Realtime statistieken |
| Tijdstip | Voordat de vraag piekt | Nadat de drempelwaarden zijn overschreden |
| Reactiesnelheid | Onmiddellijk (middelen vooraf toegewezen) | Er kunnen vertragingen optreden tijdens het opschalen. |
| Beste voor | Voorspelbare verkeerspatronen | Onvoorspelbare, plotselinge pieken |
| Kostenimpact | Vereist voorafgaande planning. | Flexibiliteit met betaling per gebruik |
De juiste strategie kiezen hangt af van de voorspelbaarheid van uw werklast, de systeemvereisten en de bedrijfsdoelstellingen. Voor de meeste toepassingen biedt een combinatie van beide benaderingen de beste resultaten.
Proactieve versus reactieve schaling: een complete vergelijkingsgids
Proactief opschalen: vooruit plannen
Hoe proactieve schaalvergroting werkt
Proactieve schaling is gebaseerd op het analyseren van historische belastinggegevens om verkeerspatronen te identificeren – of deze nu dagelijks, wekelijks of seizoensgebonden zijn. Op basis van deze patronen worden resources vooraf voorbereid, zodat systemen gereed zijn voordat de vraag piekt. Deze aanpak valt doorgaans in twee categorieën: geplande schaalvergroting, waarbij gebruik wordt gemaakt van vaste, tijdsgebonden acties (zoals een cronjob), en voorspellende schaalvergroting, waarbij gebruik wordt gemaakt van machine learning om de vraag te voorspellen. Voorspellende schaalvergroting vereist doorgaans minstens 1-2 weken aan historische gegevens om effectief te functioneren. Het belangrijkste verschil met reactieve schaalvergroting is de timing: resources worden toegewezen. voordat De toegenomen belasting komt eraan.
Deze methode initialiseert vooraf resources om aan de directe vraag te voldoen en schaalt vervolgens mee wanneer nodig. Voor applicaties met lange opstarttijden – zoals grote ERP-systemen of complexe webplatformen – is deze preventieve aanpak cruciaal. Het garandeert consistente prestaties en legt de basis voor de voordelen die hieronder worden beschreven.
Voordelen van proactieve schaalvergroting
Door resources paraat te hebben voordat de vraag toeneemt, elimineert proactieve schaling vertragingen, zorgt voor stabiele prestaties en minimaliseert downtime. Dit leidt tot een soepelere gebruikerservaring, zelfs tijdens piekuren.
Bedrijven die proactief schalen, zien vaak een 10% tot 40% verlaging van de onderhoudskosten vergeleken met reactieve methoden. Bovendien kunnen proactieve strategieën de downtime met wel ... verminderen. 50%, Dit is een cruciaal voordeel voor bedrijven die zich richten op het handhaven van een hoge beschikbaarheid. In tegenstelling tot overprovisionering – het aanhouden van overtollige resources "voor het geval dat" – vermindert deze aanpak verspilling van infrastructuur en waarborgt tegelijkertijd de uptime. Automatisering minimaliseert bovendien de risico's op handmatige fouten en de arbeidsintensieve aard van handmatige aanpassingen.
Wanneer moet je proactieve schaalvergroting toepassen?
Proactief schalen werkt het beste wanneer de werkbelasting voorspelbare patronen volgt. Als uw verkeer bijvoorbeeld consistent piekt tijdens kantooruren en 's nachts afneemt, zorgt proactief schalen ervoor dat er tijdig voldoende capaciteit beschikbaar is. Het is ook zeer geschikt voor eenmalige gebeurtenissen met historische gegevens, zoals productlanceringen, marketingcampagnes of seizoensgebonden pieken zoals Black Friday. Terugkerende taken zoals batchverwerking, geplande data-analyse of het testen van werkbelastingen met bekende schema's zijn eveneens ideale kandidaten. De rode draad is voorspelbaarheid: als u de vraag kunt voorspellen, is proactief schalen de beste oplossing.
Om onverwachte kosten door onnauwkeurige voorspellingen te voorkomen, moet u altijd een maximumlimiet instellen voor het aantal resources dat automatisch kan worden toegewezen. Monitor de capaciteit regelmatig en pas de drempelwaarden aan naarmate uw applicatie zich ontwikkelt. Door vooruit te plannen en proactief te schalen, verbetert u niet alleen de prestaties, maar zorgt u er ook voor dat resources efficiënt worden gebruikt, waardoor de uptime hoog blijft zonder onnodige kosten.
Reactief schalen: aanpassen in realtime
Hoe werkt reactief schalen?
Reactief schalen houdt realtime statistieken zoals CPU-gebruik, geheugen, aanvraagsnelheid of wachtrijdiepte in de gaten. Wanneer deze statistieken vooraf gedefinieerde drempelwaarden overschrijden – bijvoorbeeld wanneer het CPU-gebruik gedurende een bepaalde tijd 70% overschrijdt – worden schaalacties geactiveerd. Dit kan betekenen dat... opschalen door meer instanties toe te voegen of schaalvergroting in door de capaciteit te verminderen. Om constante aanpassingen te voorkomen, worden afkoelperiodes gebruikt om het systeem tussen de wijzigingen te stabiliseren.
Sommige platforms kunnen bijvoorbeeld binnen enkele minuten nieuwe instanties opstarten, terwijl andere daar langer over doen. Deze verschillen hangen af van de configuratie van het platform en kunnen direct van invloed zijn op hoe snel uw systeem op wijzigingen reageert.
Voordelen van reactieve schaling
Reactieve schaling komt het beste tot zijn recht bij onverwachte verkeerspieken. Het past automatisch de resources aan om de belasting aan te kunnen zonder handmatige tussenkomst, waardoor uw service operationeel blijft. Bovendien is het efficiënt: resources worden alleen toegevoegd wanneer dat nodig is, wat helpt om onnodige kosten door ongebruikte capaciteit te voorkomen.
Maar zoals elk systeem kent ook dit zijn uitdagingen.
Nadelen van reactieve schaling
Een van de grootste uitdagingen is Vertragingen bij de levering. Het opstarten van nieuwe instanties, met name voor complexe services, kan tijdrovend zijn. Gedurende deze wachttijd kan uw systeem tijdelijk trager worden of zelfs fouten vertonen.
Een ander probleem is de grote afhankelijkheid van nauwkeurige monitoring. Als uw meetwaarden verkeerd geconfigureerd zijn of de drempelwaarden te smal zijn, kunt u te maken krijgen met snelle schaalschommelingen – onregelmatig op- en afschalen – wat uw systeem kan destabiliseren. Om dit te voorkomen, is het verstandig om:
- Stel duidelijke marges in tussen de drempelwaarden voor opschaling en inschaling.
- Houd een kleine buffer aan extra capaciteit aan (bijvoorbeeld door te werken met een benutting van 75% in plaats van de maximale capaciteit van 100% te benutten).
- Ontwerp je applicatie zodanig dat deze staatloos, Zodat elke instantie verzoeken kan verwerken zonder sessiegegevens te verliezen.
Gebruik van reactieve en proactieve elasticiteit om de toewijzing van resources in de cloud aan te passen.
sbb-itb-59e1987
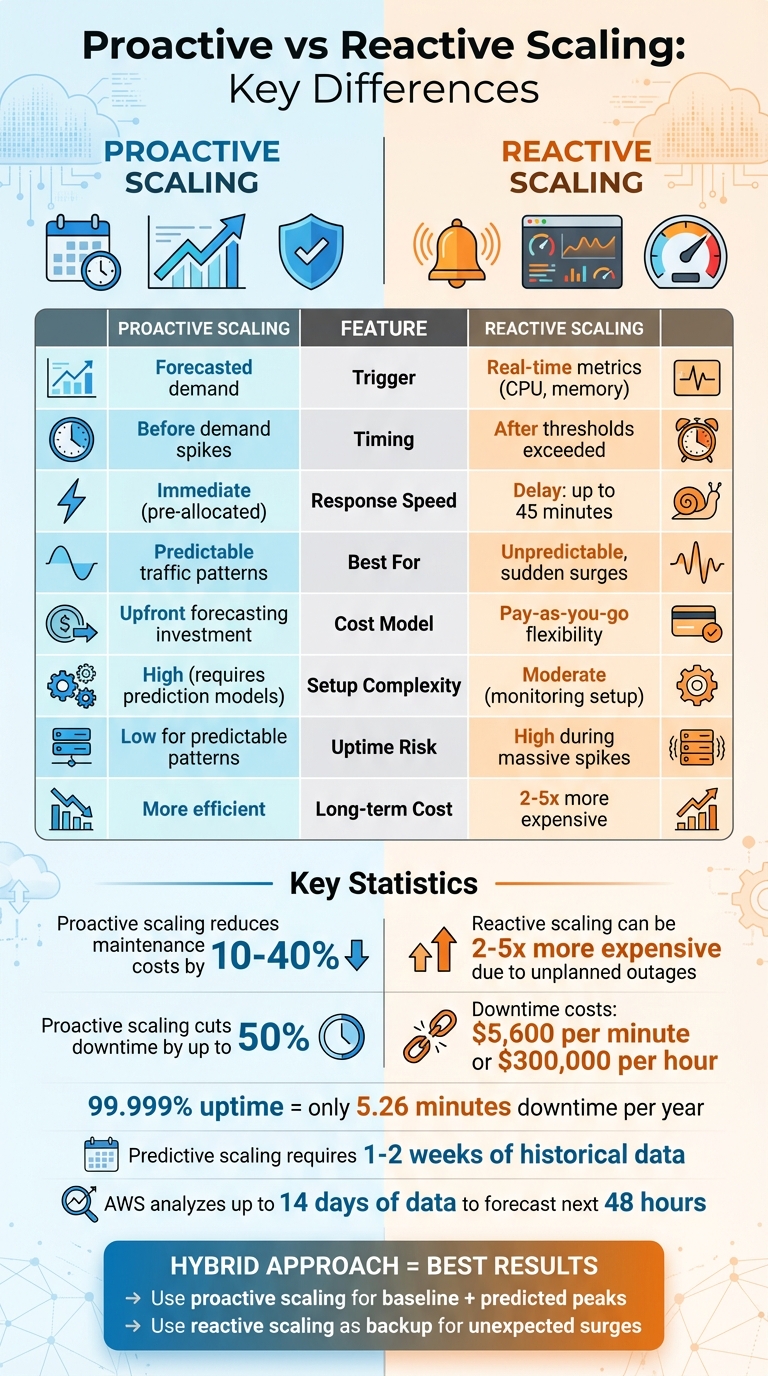
Proactieve versus reactieve schaling: belangrijkste verschillen
Laten we de belangrijkste verschillen tussen proactieve en reactieve schaalvergroting eens nader bekijken, voortbouwend op de operationele details die we eerder hebben besproken. Hieronder vindt u een tabel en analyse die de verschillen tussen deze twee strategieën uiteenzetten.
Vergelijkingstabel: Proactieve versus reactieve schaling
| Functie | Reactieve schaalvergroting | Proactieve schaalvergroting |
|---|---|---|
| Trekker | Realtime drempelwaarden | Voorspellingsgegevens |
| Tijdstip | Nadat de drempelwaarden zijn overschreden | Vooruitlopend op verwachte wijzigingen |
| Reactiesnelheid | Onderhevig aan vertraging in de beschikbaarheid van resources | Vrijwel direct (bronnen reeds aanwezig) |
| Beschikbaarheidsrisico | Hoog tijdens plotselinge, massale pieken | Laag voor voorspelbare patronen |
| Kostenimpact | Optimaliseert de elasticiteit; betalen per gebruik. | Vereist investeringen in prognoses vooraf. |
| Complexiteit van de installatie | Gemiddeld; afhankelijk van de monitoringsinstellingen. | Hoog; vereist nauwkeurige voorspellingsmodellen. |
Timing en reactiesnelheid
Het meest opvallende verschil tussen proactieve en reactieve schaalvergroting ligt in wanneer Er worden resources beschikbaar gesteld. Reactief schalen wacht tot drempelwaarden – zoals 70% CPU-gebruik – zijn bereikt voordat extra resources worden toegewezen. Deze aanpak heeft echter een nadeel: sommige cloudservices kunnen veel resources verbruiken. tot 45 minuten om de schaalvergroting te voltooien. Deze vertraging betekent dat de resources mogelijk niet op tijd gereed zijn om plotselinge verkeerspieken op te vangen, wat de dienstverlening tijdens cruciale momenten kan verstoren.
Proactieve schaalvergroting hanteert een andere aanpak. De benodigde middelen zijn immers al toegewezen. voordat Vraagpieken doen zich voor, waardoor vertragingen worden geëlimineerd. Als u bijvoorbeeld een productlancering voorbereidt of uw piektijden voor verkeer kent, zorgt proactieve schaling ervoor dat uw systeem volledig is uitgerust om de piek zonder vertragingen op te vangen.
Kosten en resourcegebruik
Strategieën voor resourceallocatie hebben ook een directe impact op kosten en prestaties, die cruciaal zijn voor het behoud van beschikbaarheid en efficiëntie.
Reactieve schaalvergroting werkt volgens een pay-as-you-go-model, waarbij resources alleen worden toegevoegd wanneer dat nodig is. Hoewel deze aanpak de initiële kosten minimaliseert, kan dit op de lange termijn tot hogere kosten leiden. Volgens het Marshall Institute kan reactieve schaalvergroting 2 tot 5 keer duurder vanwege ongeplande storingen en de noodzaak tot noodreparaties.
Aan de andere kant vereist proactieve schaling een investering vooraf in prognoses en resourceallocatie. Dit leidt echter vaak tot aanzienlijke besparingen op de lange termijn door downtime te verminderen en zowel overprovisionering (geldverspilling) als onderprovisionering (prestatieproblemen) te voorkomen. Voor workloads met onvoorspelbaar verkeer biedt reactieve schaling meer flexibiliteit. Maar voor workloads met consistente patronen blijkt proactieve schaling op de lange termijn kostenefficiënter te zijn.
De juiste schaalstrategie kiezen
De keuze tussen proactieve en reactieve schaalvergroting is niet altijd eenvoudig. De beslissing hangt af van factoren zoals voorspelbaarheid van de belasting, toepassingsgedrag, En zakelijke behoeften. Laten we eens kijken wanneer elke aanpak het meest zinvol is.
Wanneer moet je proactieve schaalvergroting toepassen?
Proactieve schaalvergroting is ideaal als uw verkeerspatronen voorspelbaar zijn. Als u bijvoorbeeld weet dat de vraag piekt tijdens kantooruren of op vrijdagmiddag, kunt u zich met deze strategie van tevoren voorbereiden.
Het is ook een must voor applicaties met lange opstarttijden. Als het initialiseren van je app enkele minuten duurt, kan reactief schalen ertoe leiden dat gebruikers moeten wachten – of erger nog, fouten tegenkomen – totdat nieuwe resources beschikbaar komen. Door resources vooraf toe te wijzen, voorkom je deze vertragingen.
Hoog Service Level Agreements (SLA's) Dit is nog een reden om voor proactieve schaling te kiezen. Als u een uptime van 99,9991 TP3T belooft (waarbij slechts 5,26 minuten downtime per jaar is toegestaan), is wachten tot reactieve schaling dit heeft ingehaald geen optie. Aan de andere kant kan reactieve schaling voldoende zijn voor workloads met een uptime van 99,91 TP3T (ongeveer 8,76 uur downtime per jaar).
Wanneer moet je reactieve schaling gebruiken?
Reactief schalen komt het beste tot zijn recht in scenario's met onvoorspelbaar of volatiel verkeer. Als u een product lanceert zonder historische verkeersgegevens, te maken krijgt met plotselinge buzz op sociale media of onregelmatige pieken als gevolg van nieuwsberichten, zorgt reactief schalen ervoor dat u alleen betaalt voor resources wanneer de vraag een bepaalde drempel overschrijdt, zoals CPU- of geheugengebruik.
Deze aanpak is met name kostenefficiënt voor pieken in de werkdruk Geactiveerd door ongeplande gebeurtenissen. U vermijdt de kosten van het aanhouden van ongebruikte capaciteit tijdens rustige perioden en kunt snel terugschalen nadat een piek in de vraag is afgenomen.
Reactieve schaling werkt echter het beste met stateless applicaties. Als uw applicatie afhankelijk is van instantiespecifieke gegevens of langlopende taken, hebt u een doordacht ontwerp nodig om een soepele afsluiting tijdens opschaling te garanderen. Houd bovendien de onderliggende systemen in de gaten: het opschalen van uw webservers zonder rekening te houden met de databasecapaciteit kan knelpunten veroorzaken.
Voor de beste resultaten kan een combinatie van reactieve en proactieve beleidsmaatregelen een evenwicht vinden tussen kosten en prestaties.
Beide strategieën combineren
De meest efficiënte schaalvergroting combineert vaak beide benaderingen. Proactieve schaalvergroting zorgt voor uw verwachte basisverkeer en voorspelde pieken, terwijl reactieve schaalstappen als een back-up voor onverwachte pieken. Deze hybride aanpak minimaliseert overcapaciteit en behoudt tegelijkertijd de betrouwbaarheid.
""Het doel van kostenoptimaliserend schalen is om op het laatst verantwoorde moment op te schalen en af te schalen zodra dat praktisch mogelijk is." – Microsoft Azure Well-Architected Framework
Je kunt bijvoorbeeld proactieve schaling plannen voor reguliere kantooruren en tegelijkertijd reactieve beleidsregels toepassen om afwijkingen van je voorspelling te beheren. AWS Predictive Scaling analyseert bijvoorbeeld tot 14 dagen aan historische gegevens om de vraag voor de komende 48 uur te voorspellen, wat een solide basis vormt. Reactieve schaling vangt vervolgens alles op wat buiten die voorspellingen valt.
Om te voorkomen dat de kosten tijdens gebeurtenissen zoals DDoS-aanvallen of softwarefouten uit de hand lopen, moet u altijd een maximale limiet op het aantal instanties dat automatisch kan worden toegevoegd. Gebruik daarnaast de Gaskleppatroon Om uw systeem te beschermen terwijl er tijdens plotselinge pieken nieuwe resources worden opgestart. Voorkom ten slotte "flapping" (het snel toevoegen en verwijderen van resources) door voldoende marge in te stellen tussen de drempelwaarden voor opschalen en afschalen.
Conclusie
De keuze tussen proactieve en reactieve schaling hangt af van uw werkbelastingpatronen en bedrijfsdoelen. Voor workloads met voorspelbare verkeerspatronen zorgt proactieve schaling ervoor dat uw systemen klaar zijn voordat de vraag piekt, waardoor potentiële prestatieproblemen worden voorkomen. Reactieve schaling is daarentegen ideaal voor het opvangen van onverwachte pieken, waarbij de kosten beheersbaar blijven door alleen resources toe te voegen wanneer dat nodig is.
Houd rekening met de mogelijke gevolgen: stilstand kan ongeveer ... kosten. $5.600 per minuut, waarbij de verliezen oplopen tot $300.000 per uur. Als je streeft naar een uptime van "vijf negens" (99,999%) – wat neerkomt op slechts 5,26 minuten downtime per jaar – Proactieve maatregelen zijn essentieel om aan de vraag te blijven voldoen en de betrouwbaarheid te waarborgen.
Veel succesvolle systemen hanteren een hybride aanpak. Proactieve schaling zorgt voor uw basisbehoeften en verwachte pieken, terwijl reactieve schaling als back-up fungeert voor plotselinge, onvoorziene vraag. Deze combinatie biedt een evenwicht tussen kostenefficiëntie en betrouwbaarheid, met name wanneer uw applicaties zijn ontworpen voor stateless werking, waardoor naadloze schaling mogelijk is.
Zodra uw schaalstrategie is vastgesteld, wordt de infrastructuur die u kiest van cruciaal belang. Serverion’De hostingoplossingen van bieden een solide basis voor zowel proactieve als reactieve schaalvergroting. Met een wereldwijd gedistribueerde infrastructuur, 24/7 ondersteuning en ingebouwde DDoS-bescherming kunt u vol vertrouwen geautomatiseerde schaalvergroting implementeren, waardoor u zich kunt concentreren op het verfijnen van uw beleid in plaats van u zorgen te maken over de onderliggende systemen.
Veelgestelde vragen
Wat zijn de voordelen van het combineren van proactieve en reactieve schaalstrategieën?
Door proactieve en reactieve schaalvergroting te combineren, ontstaat een slimme balans voor het beheren van de verkeersvraag. Proactieve schaalvergroting vertrouwt op voorspellende tools om verkeersstijgingen te anticiperen, zodat u zich van tevoren kunt voorbereiden, verspilling van middelen kunt minimaliseren en kosten kunt beheersen. Ondertussen, reactieve schaling Past zich aan om onverwachte verkeerspieken op te vangen, zodat uw systemen stabiel en responsief blijven wanneer er plotselinge pieken optreden.
Door deze twee strategieën te combineren, voorkomt u de valkuilen van overprovisionering (wat uw budget uitput) en tegelijkertijd onderprovisionering (wat tot downtime kan leiden). Deze evenwichtige aanpak zorgt niet alleen voor een efficiënter gebruik van resources, maar houdt uw systemen ook betrouwbaar. Voor Serverion-klanten is deze hybride methode direct geïntegreerd in de autoscaling-tools van het platform, waardoor uw applicaties snel, economisch en betrouwbaar blijven – zelfs bij onvoorspelbare verkeersschommelingen.
Wat is het verschil tussen voorspellende schaalvergroting en geplande schaalvergroting in proactieve strategieën?
Voorspellende schaalvergroting maakt gebruik van historische gegevens en machine learning om de toekomstige vraag te voorspellen en de resources automatisch aan te passen voordat de behoefte zich voordoet. Geplande schaalvergroting daarentegen werkt volgens een vast schema, waarbij de capaciteit wordt verhoogd of verlaagd op basis van specifieke, vooraf bepaalde data en tijden.
Hoewel beide methoden een proactieve aanpak hanteren, biedt voorspellende schaling een flexibelere en responsievere oplossing. Geplande schaling blinkt daarentegen uit in scenario's met consistente, voorspelbare werkbelastingen of terugkerende gebeurtenissen.
Wat zijn de grootste uitdagingen bij het gebruik van reactieve schaling?
Reactief schalen brengt de nodige uitdagingen met zich mee, die zowel de prestaties als de kosten beïnvloeden. Een belangrijk obstakel is de tijdsvertraging Er zit een vertraging tussen het vaststellen van een verkeerspiek en het inzetten van extra resources. Deze vertraging leidt vaak tot tijdelijke vertragingen of zelfs serviceuitval, omdat opschalen pas in werking treedt wanneer de vraag de vooraf gedefinieerde limieten al heeft overschreden. De situatie kan verergeren als het proces handmatige aanpassingen of complexe berekeningen vereist.
Een ander lastig aspect is het bepalen van de juiste monitoringstatistieken en drempelwaarden. Als de drempelwaarden te laag worden ingesteld, kunnen er onnodige schaalacties plaatsvinden, waardoor resources worden verspild en de kosten stijgen. Aan de andere kant kan het instellen van te hoge drempelwaarden leiden tot onderprovisionering, wat de gebruikerservaring negatief kan beïnvloeden. Reactief schalen is bovendien sterk afhankelijk van... betrouwbare gezondheidscontroles en waarschuwingssystemen. Eventuele gebreken of hiaten in deze systemen kunnen de reactie op plotselinge toenames in de vraag vertragen.
Ten slotte kan reactieve schilfering leiden tot onvoorspelbare kosten, Omdat onverwachte pieken in het verkeer kunnen leiden tot hogere kosten dan verwacht. Om deze problemen aan te pakken, biedt Serverion geautomatiseerde monitoring, robuuste gezondheidscontroles en flexibele schaalbeleidsregels, wat zorgt voor snellere reacties en efficiënter resourcebeheer.




