
Hoe u de prestaties van een hybride cloud kunt monitoren
- Centraliseer de monitoringGebruik een uniform platform om gegevens te volgen in zowel cloud- als on-premises systemen.
- Stel basiswaarden vastDefinieer "normale" prestatiemetingen zoals CPU-gebruik, geheugenbelasting en latentie.
- Volg belangrijke statistieken:
- Rekenen en opslag: Monitor CPU, geheugen, schijf-IOPS en latentie.
- Netwerk: Houd de bandbreedte, het pakketverlies en de latentie tussen systemen in de gaten.
- Gebruikerservaring: Meet de tijd tot de eerste byte (TTFB), laadtijden van pagina's en foutpercentages.
- Automatiseer meldingenGebruik slimme waarschuwingen met dynamische drempelwaarden om valse positieven te verminderen en snel te reageren.
- Maak gebruik van AI: Pas AI toe voor anomaliedetectie en voorspellende analyses om problemen vroegtijdig te signaleren en de benodigde capaciteit te plannen.
Snelle tip:
Begin met een duidelijke inventarisatie van uw hybride assets, breng de afhankelijkheden in kaart en selecteer een monitoringtool die naadloos integreert in alle omgevingen. Gebruik AI en automatisering om handmatige inspanningen te verminderen en de responstijden te verbeteren.
Het monitoren en optimaliseren van een hybride cloudomgeving.
Stel uniforme monitoring in voor uw hybride omgeving.
Om een hybride cloudomgeving effectief te monitoren, is de eerste stap het samenbrengen van al uw tools en datastromen in één samenhangend systeem. Begin door al uw bezittingen catalogiseren Dit omvat fysieke servers, virtuele machines, cloud-instances, netwerkapparaten en edge-locaties. Zodra u alles in kaart hebt gebracht, kunt u de interactie tussen deze componenten analyseren en ze rangschikken op basis van hun belang voor uw bedrijf en SLA-vereisten. Deze inventarisatie helpt u bepalen welke elementen het meest gemonitord moeten worden.
Selecteer een monitoringplatform
Uw monitoringplatform moet naadloos samenwerken met zowel on-premises datacenters als cloudproviders. Zoek naar tools die het volgende bieden: REST API's en vooraf gebouwde plugins Voor platforms zoals AWS, Azure en GCP. Het moet agentgebaseerde monitoring ondersteunen voor nieuwere systemen en agentloze opties zoals SNMP-polling voor oudere hardware waar geen agents kunnen worden geïnstalleerd. Geïntegreerde platforms leiden vaak tot meetbare verbeteringen, zoals een verlaging van de gemiddelde detectietijd (MTTD) en de gemiddelde oplostijd (MTTR) met 15–201 TP3T, en in sommige gevallen tot een jaarlijkse kostenbesparing van miljoenen.
Let bij de keuze van een platform goed op het prijsmodel. Veel moderne oplossingen hanteren een prijsmodel gebaseerd op verbruik, gekoppeld aan de hoeveelheid verwerkte data. Gemiddeld genereert een virtuele machine maandelijks tussen de 1 GB en 3 GB aan monitoringdata, dus houd hier rekening mee in uw budget.
Gecentraliseerde dashboards configureren
Maak een gecentraliseerd dashboard die realtimegegevens uit al uw omgevingen verzamelt. Implementeer een uniforme monitoringagent – zoals Azure Monitor Agent of AWS SSM Agent – op zowel virtuele machines in de cloud als op on-premises servers om consistente gegevensverzameling te garanderen. Voor systemen zonder directe internettoegang, zoals filiaalvestigingen, kunt u een monitoringgateway instellen om lokaal gegevens te verzamelen en deze veilig naar uw centrale werkruimte te verzenden. Het dashboard moet belangrijke statistieken, zoals latentie en foutpercentages, in alle omgevingen correleren, waardoor u niet meer tussen meerdere consoles hoeft te schakelen. Gebruik vooraf geconfigureerde sjablonen voor services zoals EC2, Lambda of Kubernetes om snel inzicht te krijgen zonder uitgebreide configuratie.
Definieer basisprestatiemaatstaven
Het is cruciaal om te begrijpen wat "normaal" is voordat u problemen kunt identificeren. Gebruik historische gegevens om basisprestatieniveaus te definiëren voor metrics zoals CPU-gebruik, geheugenbelasting, netwerklatentie en storage IOPS voor uw gehele hybride infrastructuur. Documenteer deze benchmarks voor elk component – ze dienen als referentiepunt voor het opsporen van afwijkingen. U kunt bijvoorbeeld streven naar een MTTR (Mean Time to Repair) van 4 uur naar 3,2 uur binnen 90 dagen, en verder naar 2,5 uur binnen zes maanden. Deze basiswaarden verbeteren ook de nauwkeurigheid van AI-gestuurde anomaliedetectie door valse alarmen te minimaliseren. Zodra uw basiswaarden zijn vastgesteld, begint u deze metrics nauwlettend te volgen om ervoor te zorgen dat uw systeem op koers blijft.
Volg de belangrijkste prestatie-indicatoren
Nadat u uw basiswaarden hebt vastgesteld, is de volgende stap het monitoren van belangrijke statistieken op het gebied van rekenkracht/opslag, netwerkprestaties en applicatie-ervaring. Deze statistieken geven u een duidelijk beeld van de gezondheid van uw hybride cloud. Door voort te bouwen op uw uniforme dashboard en basisdefinities kunt u consistente prestatiebewaking handhaven.
Monitor reken- en opslagstatistieken
Stel waarschuwingen in om potentiële resourcebeperkingen te signaleren voordat ze grote problemen worden. Activeer bijvoorbeeld waarschuwingen wanneer... Het CPU-gebruik overschrijdt de 80%-waarde gedurende meer dan vijf minuten. of Het geheugengebruik overschrijdt 90%.. Een hoog geheugengebruik kan ertoe leiden dat systemen naar de schijf swappen, wat de applicatieprestaties aanzienlijk vertraagt. Deze drempelwaarden kunnen naadloos worden geïntegreerd met geautomatiseerde waarschuwingen, waardoor een soepele monitoring in verschillende omgevingen wordt gewaarborgd.
Voor opslag kunt u zich richten op statistieken zoals schijf-IOPS (invoer-/uitvoerbewerkingen per seconde) en schijflatentie. Als schijfoperaties voor veeleisende workloads meer dan 1000 per seconde bedragen, is het wellicht tijd om dit nader te onderzoeken – hoewel de exacte drempelwaarden afhangen van de behoeften van uw applicatie. Houd ook de gemiddelde schijfoverdrachtstijden in de gaten; pieken hierin duiden vaak op knelpunten in de opslag. Met Google Cloud Compute Engine krijgt u toegang tot meer dan 25 systeemstatistieken per VM-instantie, wat gedetailleerde inzichten biedt zonder extra configuratie.
Monitor netwerkprestatiegegevens
In hybride omgevingen is de netwerkprestatie een cruciale factor, aangezien gegevens vaak tussen on-premises systemen en cloudproviders stromen. Het is daarom belangrijk om deze te monitoren. bandbreedte, latentie tussen locaties, En pakketverlies. Zelfs een klein pakketverlies kan wijzen op hardware- of routeringsproblemen.
Besteed extra aandacht aan pakketfouten – zowel inkomend als uitgaand. Elke waarde boven nul moet onmiddellijk worden onderzocht. Daarnaast dient u de volgende gegevens bij te houden: TCP-verbindingsopbouwtijden; Vertragingen op deze plek kunnen duiden op netwerkcongestie of inefficiënties in de routering. Traditionele monitoringtools missen vaak problemen die zich voordoen in de "gaten" tussen omgevingen, dus het is cruciaal om de grenzen te bewaken waar verkeer overgaat.
Monitor applicatie- en gebruikerservaringstatistieken
Terwijl infrastructuurstatistieken zich richten op serverprestaties, geven applicatiestatistieken inzicht in de gebruikerstevredenheid. Een belangrijke statistiek om bij te houden is Tijd tot eerste byte (TTFB), Dit omvat onder andere DNS-resolutie, het opzetten van een TCP-verbinding, de TLS-handshake en de verwerkingstijd van de server. Vertragingen in een van deze stappen kunnen duiden op problemen tijdens omgevingsovergangen.
Andere belangrijke meetwaarden zijn onder meer: pagina laadtijden en Kernwebgegevens (zoals Largest Contentful Paint, Interaction to Next Paint en Cumulative Layout Shift). Samen laten deze zien hoe uw hybride configuratie de algehele gebruikerservaring beïnvloedt.
Foutpercentages vormen een ander cruciaal aandachtspunt. Houd mislukte verzoeken nauwlettend in de gaten, met name... HTTP 5xx-fouten, wat vaak wijst op integratieproblemen tussen cloud- en on-premises systemen. Voor workflows die meerdere omgevingen omvatten, meet u de resultaten. transactievoltooiingspercentages om ervoor te zorgen dat de volledige functionaliteit intact blijft.
""We ontvangen Catchpoint-meldingen binnen enkele seconden wanneer een site offline is. En binnen drie minuten kunnen we precies vaststellen waar het probleem vandaan komt, onze klanten informeren en met hen samenwerken." – Martin Norato Auer, VP CX Observability Services bij SAP
sbb-itb-59e1987
Geautomatiseerde bewaking en waarschuwingen configureren
Zodra je belangrijke statistieken bijhoudt, is de volgende stap het automatiseren van de monitoring. Dit helpt je potentiële problemen vroegtijdig op te sporen, vooral in hybride omgevingen, en vermindert de behoefte aan constant handmatig toezicht. Door deze processen te automatiseren, kun je sneller reageren en je team vrijmaken voor belangrijkere taken. Bovendien legt het een solide basis voor het verbeteren van de systeemprestaties.
Slimme meldingen configureren
Het instellen van effectieve waarschuwingen betekent onderscheid maken tussen daadwerkelijke problemen en tijdelijke storingen. Voor acute problemen zoals CPU-pieken of geheugenproblemen, metrische waarschuwingen bieden bijna realtime updates. Aan de andere kant, log query alerts Ze zijn beter geschikt voor het identificeren van patronen op meerdere servers, omdat ze het mogelijk maken om complexe datasets te analyseren met behulp van querytalen.
Statische drempelwaarden, zoals het activeren van een waarschuwing wanneer het CPU-gebruik 80% overschrijdt, kunnen vaak leiden tot valse alarmen tijdens voorspelbare verkeerspieken. Om dit te voorkomen, kunt u overwegen om gebruik te maken van dynamische drempels Aangedreven door machine learning. Deze drempelwaarden passen zich aan normale activiteitspatronen aan, waardoor u onnodige waarschuwingen kunt verminderen en u kunt concentreren op echte afwijkingen.
Het is ook belangrijk om de ernst van waarschuwingen te definiëren. Kritieke waarschuwingen, zoals uitval van resources, moeten bijvoorbeeld direct via sms aan de dienstdoende teams worden gemeld. Waarschuwingen met een lagere prioriteit kunnen daarentegen via standaard operationele kanalen worden verzonden. Zorg ervoor dat u ten minste één actiegroep per abonnement configureert, met daarin de meldingsmethoden en geautomatiseerde reacties, zodat u zeker weet dat u de belangrijkste gebeurtenissen vastlegt.
Automatische reactieacties instellen
Om automatisering verder te verbeteren, koppelt u uw meldingen aan geautomatiseerde reactietools. Bijvoorbeeld:, automatiseringshandleidingen Kan vastgelopen services onmiddellijk herstarten. Als het CPU-gebruik een kritiek niveau bereikt, regels voor automatisch schalen Kan automatisch meer virtuele machine-instanties toevoegen om de belasting op te vangen. In hybride configuraties, hybride runbook-medewerkers Herstelscripts kunnen rechtstreeks op lokale systemen worden uitgevoerd, waardoor de latentie als gevolg van cloudgebaseerde waarschuwingen wordt verminderd.
Voor een naadloze integratie kunt u webhooks gebruiken om waarschuwingen te koppelen aan uw bestaande workflows. Wanneer er prestatieproblemen optreden, kunnen geautomatiseerde acties resources opschalen, services herstarten of verkeer omleiden naar systemen die beter functioneren. Begin met eenvoudige automatisering en breid dit geleidelijk uit naar complexere, zelfherstellende workflows.
Koppel waarschuwingen in verschillende omgevingen
Om de monitoring te stroomlijnen, implementeer je uniforme agents in alle systemen om telemetrie te centraliseren. Deze aanpak biedt een uniform overzicht van zowel on-premises als in de cloud beheerde resources, waardoor het gemakkelijker wordt om problemen in meerdere omgevingen te identificeren en op te lossen.
Bij het oplossen van problemen, neem het volgende mee: correlatie-ID's in logboeken om transacties over servicegrenzen heen te volgen. Inschakelen gedistribueerde tracering Om verzoeken te volgen terwijl ze zich verplaatsen tussen on-premises systemen en cloudservices. Dit helpt om precies te bepalen waar latentie of storingen optreden. Door diagnostische logboeken in één platform te consolideren, kunt u bovendien in één keer query's uitvoeren op alle omgevingen, waardoor de analyse van de hoofdoorzaak aanzienlijk wordt versneld.
Tools zoals Azure Arc of AWS Systems Manager kunnen hybride monitoring verder vereenvoudigen. Met deze services kunt u niet-native VM's en Kubernetes-clusters beheren alsof het native resources zijn, waardoor consistente monitoringbeleidsregels en tagging in uw gehele infrastructuur worden gewaarborgd. Door uw waarschuwingssysteem te verenigen, creëert u een sterke basis voor het verbeteren van de algehele prestaties en betrouwbaarheid.
Gebruik AI en voorspellende analyses voor prestatieoptimalisatie.
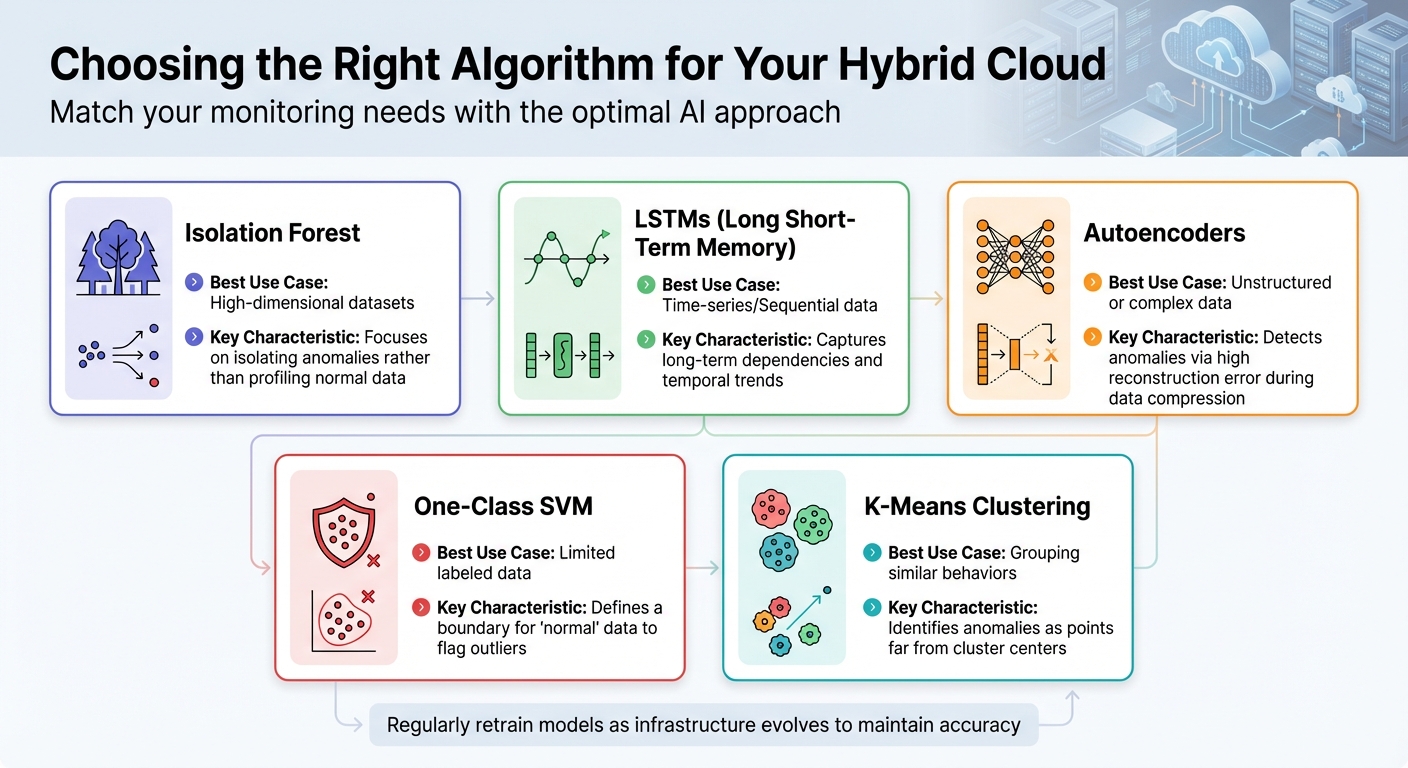
AI-algoritmen voor anomaliedetectie bij monitoring van hybride clouds
Zodra je geautomatiseerde waarschuwingen hebt ingesteld, is het tijd om de volgende stap te zetten. Door AI en machine learning te gebruiken, kun je prestatieproblemen identificeren voordat ze gebruikers beïnvloeden, waardoor je van een reactieve naar een proactieve aanpak overstapt. Deze geavanceerde tools analyseren enorme hoeveelheden telemetriegegevens in realtime en ontdekken patronen die handmatig bijna onmogelijk te detecteren zouden zijn. Dit maakt het beheren van prestaties in hybride cloudomgevingen veel efficiënter.
Stel anomaliedetectie in
AI-gestuurde anomaliedetectie werkt door te begrijpen wat "normaal" eruitziet in uw hybride omgeving en automatisch alles wat ongebruikelijk is te signaleren. Machine learning-modellen evolueren mee met uw systeem en passen zich aan veranderingen in prestatiepatronen aan. Dit is vooral handig in hybride clouds, waar workloads regelmatig tussen on-premises en cloudbronnen worden verplaatst, waardoor dynamische prestatiebenchmarks ontstaan.
Er zijn verschillende soorten afwijkingen om te monitoren – puntafwijkingen, contextuele afwijkingen en collectieve afwijkingen – en het juiste algoritme hangt af van de situatie. Hier is een korte handleiding:
| Algoritme | Beste gebruiksscenario | Belangrijkste kenmerk |
|---|---|---|
| Isolatiebos | Datasets met hoge dimensionaliteit | De focus ligt op het isoleren van afwijkingen in plaats van het profileren van normale gegevens. |
| LSTM's | Tijdreeks-/sequentiële gegevens | Legt langetermijnafhankelijkheden en tijdstrends vast. |
| Auto-encoders | Ongestructureerde of complexe gegevens | Detecteert afwijkingen via een hoge reconstructiefout tijdens datacompressie. |
| Eénklasse SVM | Beperkte gelabelde gegevens | Definieert een grens voor "normale" gegevens om uitschieters te signaleren. |
| K-means clustering | Het groeperen van soortgelijk gedrag | Identificeert afwijkingen als punten die ver van de clustercentra verwijderd zijn. |
Voor tijdreeksdata werken Long Short-Term Memory (LSTM)-netwerken bijzonder goed, omdat ze trends in de tijd kunnen vastleggen. Bij het verwerken van hoogdimensionale data verspreid over meerdere servers zijn autoencoders een goede keuze. Deze neurale netwerken comprimeren en reconstrueren data, waarbij reconstructiefouten vaak wijzen op onregelmatigheden in het systeem.
Een van de uitdagingen bij anomaliedetectie is de onbalans in data – anomalieën komen minder vaak voor dan normale data, wat de modeltraining kan bemoeilijken. Om dit aan te pakken, gebruiken sommige teams Generative Adversarial Networks (GAN's) om synthetische anomaliedata te creëren wanneer er weinig voorbeelden uit de praktijk beschikbaar zijn. Houd statistieken zoals de Mean Time to Detection (MTTD) in de gaten om te meten hoe snel uw systeem prestatieproblemen identificeert.
""AI-gebaseerde anomaliedetectie verbetert niet alleen de realtime zichtbaarheid en de reactie op bedreigingen, maar effent ook de weg naar voorspellende, zelfherstellende en intelligente hybride cloudbeveiligingsecosystemen." – Kavita L. Desai
Vergeet niet om uw AI-modellen regelmatig opnieuw te trainen. Naarmate uw infrastructuur evolueert – of u nu nieuwe virtuele machines toevoegt, services opschaalt of workloads aanpast – kan wat vandaag als "normaal" wordt beschouwd er in de toekomst heel anders uitzien.
Voorspellende analyses toepassen voor capaciteitsplanning
Voorspellende analyses tillen capaciteitsplanning naar een hoger niveau door historische gebruikspatronen te analyseren en zo toekomstige resourcebehoeften te voorspellen. Dit verschuift de planning van reactief giswerk naar een proactiever, datagestuurd proces.
Begin met het centraliseren van de gegevensverzameling in uw hybride omgeving. Aggregeer logboeken en statistieken van on-premises systemen, private clouds en publieke cloudplatformen in een uniforme gegevensopslagplaats. Dit uitgebreide overzicht stelt machine learning-modellen in staat om patronen en verbanden tussen workloads en resourceverbruik te identificeren.
""Voorspellende analyses kunnen ook historische gegevens en gebruikspatronen analyseren om automatisch te anticiperen op de benodigde resources voor het schalen van on-premise en cloudresources." – Red Hat
Als uw modellen bijvoorbeeld consistente pieken in het CPU-gebruik op specifieke tijdstippen detecteren, kunnen ze aanbevelen om de resources vooraf op te schalen. Combineer deze inzichten met geautomatiseerde resourceallocatie om workloads dynamisch te verdelen over de meest kostenefficiënte omgevingen in uw hybride configuratie.
Voordat u zich verdiept in AI-gestuurde capaciteitsplanning, is het belangrijk om eventuele technische achterstanden in uw infrastructuur aan te pakken. Verouderde systemen en afhankelijkheden kunnen knelpunten veroorzaken bij de introductie van AI-workloads. Overweeg voor nieuwe implementaties om helemaal opnieuw te beginnen met een gemoderniseerde infrastructuur die schaalbaarheid op lange termijn ondersteunt.
""AI-gestuurde tools voor voorspellende analyses leren voortdurend. Dit betekent dat ze hun voorspellingen in de loop der tijd aanpassen en verfijnen, zodat ze altijd actueel zijn." – DataBank
Om de kosten beheersbaar te houden tijdens schaalvergroting, stemt u uw capaciteitsplanning af op de principes van FinOps. Voorspellende analyses kunnen helpen bij het automatiseren van governancebeslissingen, zodat u uw cloudinvesteringen optimaliseert, zelfs bij de implementatie van resource-intensieve AI-workloads.
Evalueer en actualiseer uw monitoringstrategie.
AI en voorspellende tools zijn geen oplossing die je instelt en vervolgens vergeet. Naarmate je hybride omgeving evolueert – of je nu de infrastructuur opschaalt, services toevoegt of workloads verschuift – moet je monitoringstrategie gelijke tred houden.
Controleer regelmatig uw methoden voor gegevensverzameling. Stop met het verzamelen van onnodige gegevens en pas de bewaartermijnen aan om kosten te besparen zonder afbreuk te doen aan de naleving van regelgeving of de mogelijkheden voor oorzaakanalyse. Optimaliseer de routering van waarschuwingen om ervoor te zorgen dat kritieke meldingen de juiste teams bereiken en dat de ernstniveaus aansluiten bij uw huidige operationele prioriteiten.
""Naarmate uw omgevingen groeien, moeten deze procedures voortdurend worden verfijnd, zodat uw team problemen snel kan oplossen en nauwkeurig kan troubleshooten." – Casey Wopat, Senior Product Marketing Manager, NetApp
Iteratief testen is essentieel. Controleer of uw monitoringgegevens en waarschuwingsdrempels overeenkomen met de daadwerkelijke prestatiedoelen. Naarmate uw bedrijfsbehoeften veranderen, kunnen er nieuwe lacunes in de monitoring ontstaan. Regelmatige evaluaties helpen u deze lacunes te identificeren en aan te pakken voordat ze gebruikers beïnvloeden. Werk de prestatiebaselines bij om de nieuwste operationele patronen te weerspiegelen, zodat AI-modellen blijven leren van nauwkeurige, actuele gegevens.
Conclusie
Deze handleiding heeft het belang benadrukt van uniforme zichtbaarheid, grondige metrische tracking, slimme automatisering en AI-gestuurde tools bij het optimaliseren van hybride cloudomgevingen. Een gecentraliseerd monitoringsysteem overbrugt de kloof tussen on-premises en cloudomgevingen, waardoor de detectie- en oplostijden worden verkort. Neem bijvoorbeeld Pine Labs: zij hebben al een verbetering van 151 TP3T–201 TP3T op deze gebieden gezien dankzij uniforme observability, met projecties die zullen oplopen tot 401 TP3T–501 TP3T naarmate hun systemen geavanceerder worden [1].
Het is cruciaal om te focussen op kernstatistieken zoals rekenkracht, opslag en netwerk, aangezien deze direct van invloed zijn op de gebruikerservaring. Het is ook essentieel om netwerkgrenzen te bewaken, waar problemen zoals latentie en pakketverlies zich vaker voordoen tijdens overgangen tussen omgevingen.
Metingen alleen zijn echter niet voldoende – proactieve maatregelen zijn cruciaal. Automatisering kan de downtime aanzienlijk verminderen en resources optimaliseren. Zo heeft de regering van de Falklandeilanden de downtime van haar website met 99% teruggebracht en haar cloudkosten met 30% verlaagd dankzij geautomatiseerde waarschuwingen en resourcebeheer. Op vergelijkbare wijze heeft Nodecraft de snelheid van het oplossen van problemen zes keer zo snel verbeterd, waardoor de gemiddelde tijd tot oplossing is teruggebracht van drie minuten naar slechts 30 seconden, dankzij inzicht in de statistieken per seconde [2].
AI en voorspellende analyses tillen monitoring naar een hoger niveau door prestatiebenchmarks vast te stellen, afwijkingen te identificeren en capaciteitsbehoeften te voorspellen voordat ze problemen worden. Codyas, een technologiebedrijf, slaagde erin zijn monitoringpersoneel met 67% te verminderen en tegelijkertijd de operationele kosten met 46% te verlagen, waarmee bewezen werd hoe efficiënte tools de prestaties kunnen verbeteren zonder de zichtbaarheid in gevaar te brengen [2].
Samengevat: bouw een strategie rondom uniforme zichtbaarheid, focus op statistieken die direct van invloed zijn op gebruikers en benut de kracht van automatisering en AI. Zorg ervoor dat u uw aanpak aanpast naarmate uw infrastructuur evolueert. En voor betrouwbare hosting en serverbeheer kunt u overwegen om... Serverion’diensten van.
[1] SolarWinds Blog, 2025
[2] Casestudies van Netdata, 2023
Veelgestelde vragen
Wat zijn de voordelen van het gebruik van AI voor het monitoren van de prestaties van hybride clouds?
Het gebruik van AI om de prestaties van hybride clouds in de gaten te houden, biedt een aantal grote voordelen. Om te beginnen bieden AI-gestuurde tools... realtime inzichten en voorspellende analyse, Dit helpt IT-teams potentiële problemen op te sporen en op te lossen voordat ze escaleren. Deze vorm van proactieve monitoring minimaliseert downtime en zorgt ervoor dat de bedrijfsvoering soepel blijft verlopen, zelfs in de meest complexe hybride omgevingen.
Een ander groot pluspunt is hoe AI dit aanpakt. gegevenscorrelatie. Door data uit meerdere bronnen te analyseren, krijgen IT-teams een compleet beeld van de systeemstatus. Dit verbetert niet alleen de prestaties, maar helpt ook bij een effectievere toewijzing van resources en ondersteunt slimmere besluitvorming. Bovendien besparen AI-gestuurde tools tijd en verbeteren ze de efficiëntie door routinetaken te automatiseren en afwijkingen snel te signaleren. Daarmee zijn ze een gamechanger voor het beheer van hybride cloudomgevingen.
Hoe kies ik het beste monitoringplatform voor mijn hybride cloudomgeving?
Bij de keuze van een monitoringplatform voor uw hybride cloud is het cruciaal om te focussen op functies die aansluiten bij de vereisten van uw infrastructuur.
Begin met zichtbaarheid. Het platform moet een helder overzicht bieden van uw volledige configuratie, inclusief on-premises systemen en cloudomgevingen. Naadloze integratie met grote cloudproviders zoals AWS, Azure en Google Cloud is een absolute vereiste.
Denk vervolgens aan het bijhouden van statistieken en het detecteren van afwijkingen. Het platform moet belangrijke prestatie-indicatoren in alle lagen van uw infrastructuur bewaken, ongebruikelijk gedrag identificeren en gegevens correleren om het oplossen van problemen te vereenvoudigen.
Flexibiliteit bij de implementatie is een andere belangrijke factor. Of je nu de voorkeur geeft aan een agentgebaseerde of agentloze aanpak, de tool moet zich gemakkelijk kunnen aanpassen aan je bestaande observatiekader.
Zoek ten slotte naar uniforme dashboards. Een gecentraliseerde interface kan het eenvoudiger maken om uw hybride cloudomgeving effectief te bewaken en te beheren.
Door deze factoren af te wegen, bent u beter in staat een monitoringplatform te vinden dat past bij de omvang en complexiteit van uw infrastructuur.
Welke meetwaarden zijn essentieel voor het monitoren van de prestaties van een hybride cloud?
Om uw hybride cloud soepel te laten draaien, is monitoring essentieel. belangrijke meetgegevens die inzicht geven in de prestaties en betrouwbaarheid van uw applicaties en infrastructuur, zowel op lokale systemen als in de cloud.
Enkele van de belangrijkste meetwaarden om in de gaten te houden zijn: beschikbaarheid, latentie, gebruik van hulpbronnen (zoals CPU, geheugen en opslag), foutenpercentages, En reactietijden. Niet over het hoofd zien netwerkprestaties, Vooral de connectiviteit tussen uw omgevingen is belangrijk. Door waarschuwingen in te stellen voor kritieke drempelwaarden kunt u problemen snel opsporen en oplossen voordat ze escaleren.
Om een duidelijker beeld te krijgen, koppelt u meetgegevens van verschillende lagen, zoals applicaties, servers en netwerken. Deze correlatie helpt u knelpunten te identificeren en prestatieproblemen direct aan te pakken. Door deze grondige aanpak blijft uw hybride cloud betrouwbaar en efficiënt.




