
Incidentrespons voor AI: belangrijke meetgegevens om bij te houden
AI-systemen falen op een andere manier dan traditionele IT-systemen – problemen zoals een afname van de nauwkeurigheid, vooringenomenheid of datalekken blijven vaak dagenlang onopgemerkt. Tussen 2023 en 2024 nam het aantal incidenten met betrekking tot AI sterk toe. 56.4%, waarbij de detectietijden worden gemiddeld 4,5 dagen. Deze vertraging brengt risico's met zich mee, vooral omdat regelgeving zoals de EU AI-wet de melding van ernstige incidenten binnen een bepaalde termijn verplicht stelt. 15 dagen.
Om AI-storingen effectief te beheren, moet u statistieken bijhouden die de detectie, respons en het herstel meten. Belangrijke statistieken zijn onder andere:
- Gemiddelde tijd tot detectie (MTTD): Meet hoe snel incidenten worden geïdentificeerd.
- Detectiepercentage: Houdt bij hoeveel incidenten correct zijn gemeld.
- Gemiddelde reactietijd (MTTR): Evalueert hoe snel teams reageren na detectie.
- Vals-positieve/vals-negatieve percentages: Zorgt voor een balans tussen nauwkeurigheid van de waarschuwingen en het voorkomen van gemiste bedreigingen of onnodige ruis.
- Kosten per incident: Kwantificeert de financiële impact van vertragingen en gebrekkige reacties.
- Rendement op beveiligingsinvestering (ROSI)Laat zien hoe beveiligingstools geld besparen en risico's verminderen.
Storingen in AI vereisen proactieve monitoring en op maat gemaakte reactiestrategieën. Dergelijke meetgegevens zorgen ervoor dat uw systemen niet alleen functioneel, maar ook veilig en betrouwbaar zijn.
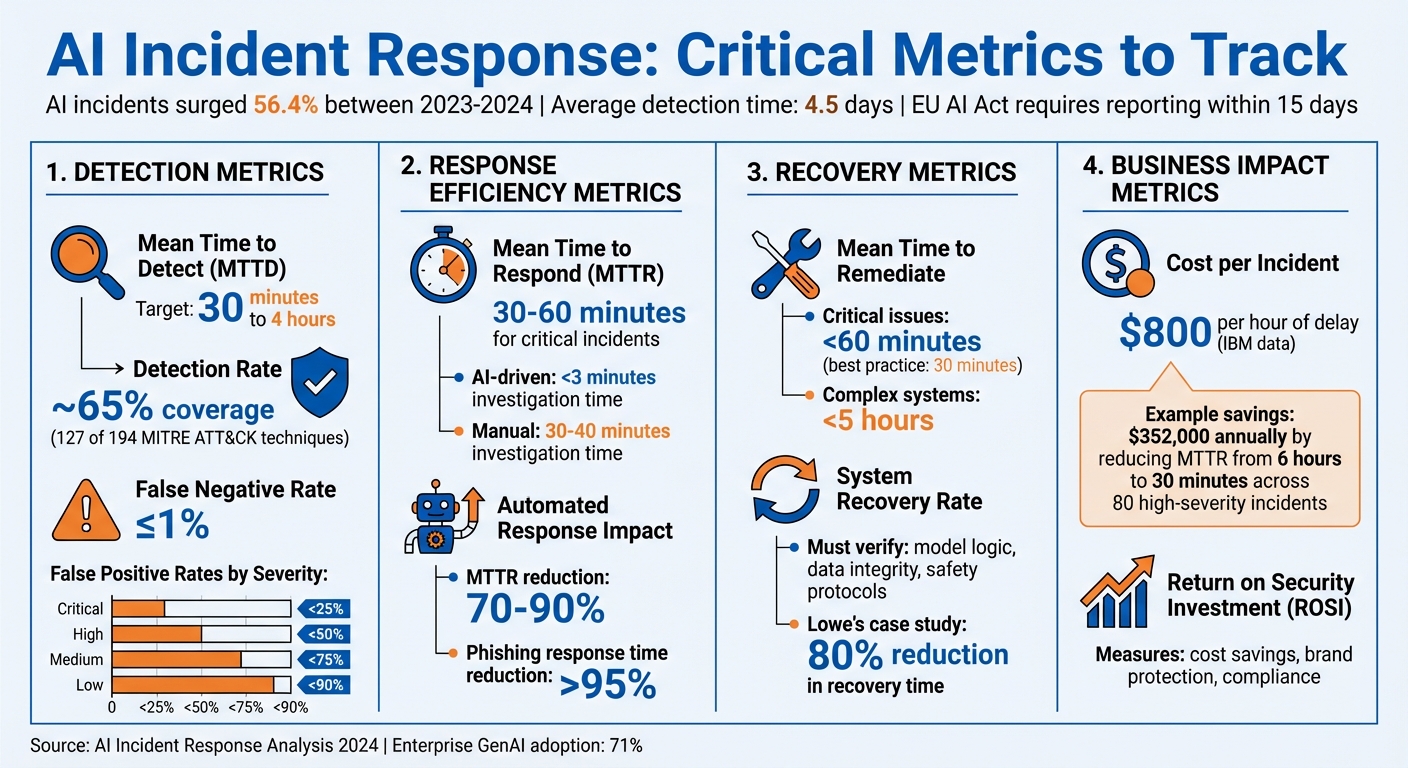
Belangrijke meetwaarden en benchmarks voor incidentrespons met betrekking tot AI
Incidentresponsplanning in het AI-tijdperk.
sbb-itb-59e1987
Detectiemetrieken
Detectiemetrieken helpen bij het meten van hoe snel en nauwkeurig uw systeem incidenten met betrekking tot AI identificeert, zoals afwijkingen, vooringenomenheid of hallucinaties. Deze metrieken vormen uw eerste verdedigingslinie tegen mogelijke schade.
Gemiddelde tijd tot detectie (MTTD)
MTTD berekent de gemiddelde tijd die nodig is om een incident te detecteren vanaf het moment dat het zich voordoet. Voor AI-systemen is deze metriek cruciaal omdat problemen zoals aanvallen of systeemstoringen snel kunnen escaleren.
Toonaangevende beveiligingsteams streven naar een MTTD (Mean Time To Detection) van 30 minuten tot 4 uur. Vertragingen buiten dit tijdsbestek verhogen het risico aanzienlijk. Neem bijvoorbeeld de Microsoft Midnight Blizzard-aanval in november 2023. Deze werd pas op 12 januari 2024 ontdekt, wat resulteerde in een MTTD van twee maanden. Deze lange detectietijd veranderde wat een kleine inbreuk had kunnen zijn in een grote inbreuk.
""Een kortere MTTD (Mean Time To Detection) duidt er over het algemeen op dat een organisatie beveiligingsincidenten sneller kan detecteren en er effectiever op kan reageren." – Katie Bykowski, Swimlane
Om de MTTD te verbeteren, breidt u uw telemetrie uit met onder andere: AI-specifiek en cloud-native aanvalspatronen. Controleer na elk incident de logbestanden om uw detectiepunten te verfijnen en uw logica bij te werken. Houd rekening met Ransomware-operatoren kunnen hun doelstellingen binnen 24 uur bereiken., Snelle detectie is essentieel om mogelijke schade te beperken.
Detectiepercentage
Snelheid is niet de enige factor; nauwkeurigheid is ook belangrijk. De detectiesnelheid meet het percentage daadwerkelijke incidenten dat uw monitoringsystemen succesvol identificeren.
Je kunt de detectiedekking berekenen door het aantal actieve, geteste detecties te delen door het totale aantal technieken in een framework zoals MITRE ATT&CK, dat 194 technieken bevat. Hoewel perfecte dekking niet haalbaar is, merken de meeste organisaties dat een goede dekking voldoende is. ~65%-dekking (ongeveer 127 technieken) is voldoende om veelvoorkomende dreigingsgedragingen aan te pakken. De focus moet liggen op het in kaart brengen van uw detectiemogelijkheden aan de hand van frameworks en het identificeren van hiaten in de dekking.
""Vroeger duurde het dagen voordat we problemen met een nieuwe release ontdekten. Nu kunnen we een probleem dezelfde dag nog opsporen en oplossen, zodat klanten probleemloos bestellingen kunnen plaatsen." – Willie James, directeur Resiliency Services, Papa Johns
Historische datalekken laten zien wat de kosten zijn van een lage detectiegraad. Zo bleef het datalek bij Equifax in 2017 bijvoorbeeld onopgemerkt. meer dan 70 dagen, en de SolarWinds-aanval van 2019 bleef ongeveer die tijd verborgen. zes maanden. Voor AI-systemen schieten traditionele meetmethoden vaak tekort bij het opsporen van stille fouten zoals modeldrift, die de prestaties kunnen ondermijnen zonder alarmen te activeren. Gedragsmonitoring, en niet alleen nauwkeurigheidscontroles, is essentieel voor het behouden van een hoge detectiegraad.
Het vinden van een balans tussen detectiedekking en precisie brengt ons bij het belang van het beheersen van vals-positieve en vals-negatieve resultaten.
Vals-positieve en vals-negatieve percentages
Valse positieven treden op wanneer normaal systeemgedrag ten onrechte als een probleem wordt aangemerkt. Valse negatieven daarentegen zijn reële bedreigingen die onopgemerkt blijven en ernstige risico's met zich meebrengen doordat ze stilletjes schade aanrichten.
Een overdaad aan valse positieven kan teams overspoelen met onnodige waarschuwingen, terwijl te strenge drempelwaarden kunnen leiden tot gevaarlijke valse negatieven.
""Het enige dat nog erger is dan een vals positief resultaat, is een vals negatief resultaat waarbij een serieuze bedreiging over het hoofd wordt gezien omdat een meetinstrument te ver is afgesteld." – Katie Bykowski, Swimlane
Hoogpresterende beveiligingsteams streven naar een laag percentage valse negatieven. op of onder 1%. Het percentage vals-positieve resultaten varieert echter afhankelijk van de ernst van de waarschuwingen:
| Ernst van de waarschuwing | Doelstelling vals-positief percentage |
|---|---|
| Kritisch | < 25% |
| Hoog | < 50% |
| Medium | < 75% |
| Laag | < 90% |
AI-incidenten voegen een extra laag complexiteit toe. Stille fouten, zoals hallucinaties – outputs die aantoonbaar onjuist zijn – worden mogelijk niet geregistreerd in foutenlogboeken. Om dit aan te pakken, is het belangrijk om feedbackloops in uw incidentbeheerproces in te bouwen om drempelwaarden continu aan te passen. Monitor regelmatig de inputverdeling om data-afwijkingen vroegtijdig te detecteren en zo de betrouwbaarheid en effectiviteit van uw AI-systemen te waarborgen. Deze proactieve aanpak draagt bij aan zowel de systeemintegriteit als de operationele stabiliteit.
Responsefficiëntiemetrieken
Wanneer zich een AI-incident voordoet, is snel handelen cruciaal. Door voort te bouwen op detectiestatistieken en de reactietijden te verkorten – gemeten aan de hand van statistieken zoals MTTR en MTTA – kunnen de risico's die gepaard gaan met AI-storingen aanzienlijk worden verminderd. Deze statistieken evalueren hoe snel uw team van het identificeren van een probleem naar het nemen van actie overgaat, wat direct van invloed is op de potentiële impact van een incident.
Gemiddelde reactietijd (MTTR)
MTTR meet de gemiddelde tijd die nodig is om systemen na een incident te detecteren, op te lossen en te herstellen. Voor AI-systemen is dit尤其 belangrijk, omdat bedreigingen zich razendsnel kunnen verspreiden. Wat een aanvaller seconden kost, kan een responsteam veel langer kosten om in te dammen.
AI-tools kunnen de reactietijden aanzienlijk verbeteren. Bijvoorbeeld:, AI-gestuurde processen Dit kan de onderzoekstijd verkorten tot minder dan 3 minuten, vergeleken met de 30-40 minuten die vaak nodig zijn voor handmatige methoden.
In kritieke situaties moeten organisaties streven naar een MTTR (Mean Time to Repair) van minder dan 30-60 minuten. Snellere reacties betekenen minder uitvaltijd en lagere kosten.
""Wanneer AI-systemen binnen een minuut meldingen kunnen onderzoeken en rapporten kunnen leveren die direct tot een beslissing leiden, begint de traditionele MTTR-klok (Mean Time to Resolution) anders te lopen." – Ajmal Kohgadai, Director of Product Marketing, Prophet Security
Om een kortere MTTR te bereiken, kunt u overwegen gebruik te maken van Beveiligingsorkestratie, -automatisering en -respons (SOAR) Platformen voor het afhandelen van repetitieve taken, zoals het verrijken van waarschuwingen en het informeren van belangrijke belanghebbenden. Geïntegreerde SIEM/XDR-platformen kunnen ook de zichtbaarheid centraliseren, waardoor essentiële gegevens gemakkelijker toegankelijk worden en er sneller gereageerd kan worden.
Het verbeteren van de MTTR legt ook de basis voor snellere bevestigingen van meldingen, zoals gemeten door de MTTA.
Gemiddelde tijd tot bevestiging (MTTA)
MTTA meet de tijd tussen het moment dat een melding wordt gegenereerd en het moment dat deze wordt bevestigd, hetzij door een persoon, hetzij door een geautomatiseerd systeem. Deze metriek kan inzicht geven in de vraag of uw team overweldigd wordt door te veel meldingen of dat er op bepaalde momenten hiaten in de dekking zijn.
AI-systemen kunnen direct beginnen met het onderzoeken van meldingen, waardoor de MTTA (Mean Time To Act) vaak tot bijna nul wordt gereduceerd. Dit is cruciaal voor bedrijfs-SOC's (Security Operations Centers), die dagelijks meer dan 10.000 meldingen verwerken – een onbeheersbaar volume voor handmatige processen alleen.
""MTTA (Mean Time to Acknowledge) meet de tijd die verstrijkt voordat een analist een melding begint te onderzoeken... In sterk geïntegreerde omgevingen starten AI SOC-analisten direct met onderzoeken, waardoor MTTA in veel gevallen effectief wordt geëlimineerd." – Prophet Security
Naarmate AI de eerste triage overneemt, verschuift de focus naar de "gemiddelde tijd tot menselijke beslissing" (Mean Time to Human Decision, MTTA). Dit meet de tijd die verstrijkt tussen het moment dat een AI zijn rapport voltooit en het moment dat een menselijke analist de beslissing goedkeurt of doorstuurt. Dit helpt te bepalen of de output van de AI duidelijk en bruikbaar is. Om de MTTA te verbeteren, kunt u terugkerende meldingen instellen om de dienstdoende medewerkers direct op de hoogte te stellen en de MTTA-gegevens gebruiken om de personeelsbezetting aan te passen tijdens perioden met een hoge alertheid.
Geautomatiseerde responsfrequentie
Het versnellen van de eerste reacties is slechts het begin. Het automatiseren van de afhandeling tilt de efficiëntie naar een hoger niveau door de gemiddelde tijd tot het oplossen van incidenten (MTTR) te verkorten van uren of dagen tot slechts seconden of minuten. De geautomatiseerde responsratio meet hoeveel incidenten worden opgelost zonder menselijke tussenkomst, waardoor de algehele effectiviteit van de respons verbetert.
Zo implementeerde een digitale verzekeringsmaatschappij met bijna 2 miljoen klanten in 2025 bijvoorbeeld AI-gestuurde SOC-analisten om de enorme hoeveelheid meldingen te verwerken. Het resultaat? Continue 24/7-monitoring, geen gemiste meldingen, minder valse positieven en aanzienlijke kostenbesparingen doordat er geen extra personeel hoefde te worden aangenomen. Het menselijke team kon zich vervolgens richten op prioritaire beveiligingsproblemen in plaats van op repetitieve taken.
""Dropzone bespaart jou en je team enorm veel tijd door overbodige taken te vermijden die niemand wil doen... Het stelt je in staat om cruciale problemen op te lossen waar jij en je team anders de capaciteit niet voor hebben." – Lid van het beveiligingsteam, digitale verzekeringsmaatschappij
AI-SOC-systemen kunnen de MTTR (Mean Time to Resolution) met 701 tot 901 TP3T (Time To Repair) verkorten. Bij incidenten met een hoog volume, zoals phishing, kan automatisering de responstijd met meer dan 951 TP3T verkorten. Om de efficiëntie te maximaliseren, identificeer je voorspelbare, frequente incidenten – zoals wachtwoordresets of de afhandeling van bekende malware – als de belangrijkste kandidaten voor automatisering. Gebruik een betrouwbaarheidsscore om te bepalen welke incidenten volledig geautomatiseerd kunnen worden en welke menselijke tussenkomst vereisen. Integreer ten slotte je automatiseringstools met alle detectiesystemen om datasilo's te elimineren die de respons vertragen.
| Reactietype | Snelheid | Schaalbaarheid | Samenhang |
|---|---|---|---|
| Handmatig antwoord | Minuten tot uren | Beperkt door het aantal medewerkers | Verschilt per ervaring |
| Geautomatiseerde reactie | Seconden tot minuten | Vrijwel onbeperkt | Gestandaardiseerde uitvoering |
Het verfijnen van deze prestatiemaatstaven voor responsefficiëntie verbetert de vroegtijdige detectie en versterkt uw algehele aanpak van incidentbeheer.
Herstel- en saneringsstatistieken
Snel handelen is essentieel tijdens incidenten, maar het uiteindelijke doel is een volledige en betrouwbare oplossing te garanderen. Herstel- en reparatiestatistieken helpen bevestigen dat incidenten volledig zijn opgelost en dat systemen weer betrouwbaar functioneren.
Gemiddelde tijd tot herstel
De gemiddelde hersteltijd (Mean Time to Remediate, MTTR) volgt het gehele proces van detectie tot oplossing. Deze wordt berekend door de totale tijd die aan herstel is besteed te delen door het aantal opgeloste incidenten. Voor AI-systemen omvat dit de stappen triage, diagnose, reparatie en validatie.
Interessant genoeg, ongeveer 90% van bedrijven Begin pas met het meten van de MTTR nadat een ticket is aangemaakt, wat aanzienlijke vertragingen kan maskeren. De beste werkwijze is echter om de meting te starten op het moment dat het ticket wordt gedetecteerd.
""90% van de bedrijven beginnen pas met het meten van MTTx-resultaten nadat er een ticket is aangemaakt. Door stappen in dit proces over te slaan, manipuleer je echter de MTTR-resultaten." – Brian Amaro, Senior Director Global Solutions, ScienceLogic
Toonaangevende organisaties streven ernaar kritieke problemen met AI-systemen binnen korte tijd op te lossen. 60 minuten, Sommige bedrijven streven naar een oplossing binnen 30 minuten. Voor complexere installaties is een tijd van minder dan vijf uur gebruikelijk.
Om de afhandeling te versnellen, kunt u zich richten op het automatiseren van diagnostiek, het bijhouden van gedetailleerde draaiboeken voor veelvoorkomende problemen en het centraliseren van systeemmonitoring. Evaluaties na incidenten kunnen helpen bij het opsporen van vertragingen die worden veroorzaakt door knelpunten in goedkeuringsprocedures, onvolledige documentatie of coördinatieproblemen.
Systeemherstelpercentage
Zodra de herstelwerkzaamheden zijn voltooid, zorgen herstelstatistieken ervoor dat de oplossingen zowel effectief als volledig zijn.
Het systeemherstelpercentage meet het percentage AI-systemen dat is hersteld. volledige operationele status Na een incident. In tegenstelling tot traditioneel IT-herstel, dat zich richt op de beschikbaarheid van de server, moet bij AI-herstel worden bevestigd dat de modellogica, de gegevensintegriteit en de veiligheidsprotocollen intact zijn – en niet alleen dat het systeem draait.
Het herstel is pas voltooid wanneer het systeem veilig functioneert met geverifieerde oplossingen. Dit omvat het aanpakken van problemen zoals modelafwijkingen of vertekeningen die na een incident kunnen ontstaan. Traditionele herstelmethoden schieten hier vaak tekort, omdat AI-storingen doorgaans onvoorspelbaar en complex zijn.
Aangezien het aantal incidenten met betrekking tot AI naar verwachting zal toenemen... 56,4% in 2024 en de acceptatie van GenAI door bedrijven 71%, Herstelstrategieën moeten zich aanpassen. Effectief herstel omvat het verifiëren van de modellogica, het waarborgen van de data-integriteit en het handhaven van veiligheidsmaatregelen. Het bijhouden van een bibliotheek met gevalideerde modelversies en het gebruik van tools zoals feature gates of kill switches kan helpen bij het beheren van instabiele componenten.
Voor kritieke systemen is het raadzaam om "veilige modi" te implementeren, waarbij de verwerking wordt overgezet naar menselijke bediening als de output van de AI onbetrouwbaar wordt. Tijdens het herstelproces maken gefaseerde uitrolprocedures gecontroleerde tests van oplossingen mogelijk voordat ze volledig worden geïmplementeerd. Het SRE-team van Lowe's demonstreerde de waarde van gestructureerd herstel door hun gemiddelde hersteltijd met een factor van 1 te verkorten. meer dan 80% door middel van gedisciplineerde incidentmanagementpraktijken.
Het meten van het herstel zorgt ervoor dat systemen niet alleen operationeel, maar ook veilig en betrouwbaar zijn.
Eerste reparatiepercentage
Een hoog percentage succesvolle oplossingen bij de eerste poging is cruciaal om terugkerende problemen te voorkomen en om op lange termijn veerkracht op te bouwen.
Deze meetwaarde geeft het percentage weer van incidenten die bij de eerste poging succesvol zijn opgelost. Voor AI-systemen is dit met name belangrijk, omdat storingen vaak probabilistisch zijn in plaats van eenduidig – snelle oplossingen kunnen dieperliggende problemen zoals datadrift of modelbias over het hoofd zien.
Herhaalde mislukkingen kunnen het vertrouwen snel ondermijnen, vooral omdat beslissingen van AI vaak directe gevolgen hebben voor de veiligheid of de financiën.
Om het percentage eerste-pogingsoplossingen te verhogen, categoriseer je veelvoorkomende fouten en deel je deze met ontwikkelteams voor oorzaakanalyse tijdens evaluaties na incidenten. Bouw een gecentraliseerde kennisbank op met oplossingen voor eerdere AI-problemen en details over modelspecifieke nuances. Dit voorkomt dat medewerkers tijd verspillen aan het opnieuw ontdekken van oplossingen voor bekende problemen. SOAR-platforms kunnen hierbij ook helpen door gestandaardiseerde herstelstappen te automatiseren, waardoor menselijke fouten worden verminderd en de consistentie wordt verbeterd.
Wijs vooraf duidelijke verantwoordelijkheidsrollen toe, zoals 'modelbeheerder' of 'databeheerder', om ervoor te zorgen dat de juiste expertise beschikbaar is tijdens incidenten. Regelmatige simulaties en oefeningen – waarbij procedures zoals het terugdraaien van modellen of het activeren van noodstops worden geoefend – kunnen teams voorbereiden om incidenten in één keer effectief af te handelen.
""Bij incidentrespons voor AI gaat het niet om het elimineren van fouten, maar om het minimaliseren van de schade wanneer er een fout optreedt." – Timnit Gebru, Distributed AI Research Institute
Bedrijfsimpactstatistieken
Metingen van de impact op de bedrijfsvoering werpen licht op de financiële gevolgen van incidenten met betrekking tot AI. Ze leggen een direct verband tussen hoe goed incidenten worden beheerd en de financiële resultaten, waardoor het gemakkelijker wordt om uitgaven aan beveiligingsmaatregelen te rechtvaardigen en de voordelen van een goede voorbereiding aan te tonen.
Incidentbeheersingspercentage
De incidentbeheersingsgraad evalueert hoe effectief u kunt voorkomen dat AI-incidenten escaleren, gemeten aan de hand van de gemiddelde tijd tot beheersing (MTTC) – de tijd die verstrijkt tussen het detecteren van een probleem en het isoleren van de getroffen resources.
Voor AI-systemen is beheersing complexer dan bij traditionele IT. Het gaat niet alleen om het uitschakelen van gecompromitteerde inloggegevens of het afsluiten van een server. Het kan betekenen dat er wordt teruggegaan naar een eerdere modelversie, dat er gebruik wordt gemaakt van feature gates om bepaalde AI-functionaliteiten uit te schakelen, of dat er wordt overgeschakeld naar handmatige terugvalmodi wanneer geautomatiseerde systemen uitvallen.
""Een lagere MTTC betekent dat je inperkingsplannen en automatisering werken – en dat je de impact beperkt voordat aanvallers zich op hun gemak voelen." – Wiz
Mislukkingen in AI brengen vaak unieke uitdagingen met zich mee, omdat ze kunnen niet-deterministisch. Bijvoorbeeld, problemen zoals indirecte promptinjectie zijn dubbelzinnig en technisch lastig, waardoor het moeilijk is om te bepalen wanneer een incident volledig is ingedamd. Daarom is het belangrijk om inperkingscriteria te definiëren voor specifieke soorten AI-falen – zoals datalekken versus modelvergiftiging – voordat problemen zich voordoen.
Met 71% Hoewel veel bedrijven GenAI gebruiken, is minder dan één op de zeven volledig voorbereid op de beveiligingsrisico's van AI. Snelheid en effectiviteit van de inperking zijn daarom cruciaal. Aanvallers kunnen zich binnen enkele minuten lateraal verplaatsen tussen cloudservices. Het identificeren van risicovolle routes in uw AI-configuratie en het implementeren van kill switches voor snelle handmatige inperking kan daarom een wereld van verschil maken.
Deze beheersingsstrategieën leggen de basis voor het meten van de financiële impact van incidenten.
Kosten per incident
Elke uur dat een incident met betrekking tot AI onopgelost blijft, verhoogt de financiële kosten. Volgens IBM kost elk uur vertraging tijdens een beveiligingslek ongeveer $800. Voor AI-systemen verstoren deze incidenten de beschikbaarheid, brengen ze de data-integriteit in gevaar en ondermijnen ze het klantvertrouwen, wat allemaal de kosten verhoogt.
U kunt uw kosten per incident berekenen met behulp van deze formule: (Totaal aantal onderzoeken per jaar) × (%-percentage ernstige incidenten) × (Uren vertraging) × (Uurkosten van een inbreuk). Focus op incidenten met een hoge ernstgraad, die doorgaans ongeveer het grootste deel uitmaken. 1% van alle waarschuwingen, omdat ze de grootste financiële impact hebben.
Het stroomlijnen van de incidentrespons met behulp van AI kan deze kosten aanzienlijk verlagen. Zo kan autonoom onderzoek van waarschuwingen de gemiddelde reactietijd in ernstige gevallen verkorten van zes uur naar slechts dertig minuten. Het verkorten van de reactietijd met 5,5 uur bij 80 ernstige incidenten zou aanzienlijke besparingen kunnen opleveren. $352,000 jaarlijks.
Bij het berekenen van de kosten dient u zowel directe uitgaven, zoals operationele verstoringen en herstelwerkzaamheden, als indirecte gevolgen, zoals datalekken en laterale verplaatsing, mee te nemen. Als uw organisatie AI-workloads uitvoert op gespecialiseerde infrastructuur, houd dan ook rekening met de kosten voor het beheer van AI GPU-servers tijdens het herstel. Diensten zoals Serverion’Het AI GPU-serverbeheer van 's kan de downtime minimaliseren en de operationele kosten verlagen door een betrouwbare infrastructuur te bieden met ingebouwde monitoring en ondersteuning.
Het bijhouden van statistieken zoals 'kosten per ernstige vertraging' en 'gemiddelde analysetijd per melding' kan helpen uw berekeningen te verfijnen en gebieden te identificeren waar automatisering de meeste kostenbesparingen kan opleveren.
Rendement op beveiligingsinvestering (ROSI)
Voortbouwend op gegevens over incidentkosten, kwantificeert Return on Security Investment (ROSI) de financiële voordelen van investeringen in krachtige responsinstrumenten. Het benadrukt de waarde van beveiligingsinvesteringen door kostenbesparingen aan te tonen, uw merk te beschermen en te voldoen aan compliance-vereisten. Voor incidentrespons met AI rechtvaardigt ROSI de uitgaven aan tools en infrastructuur die de impact van incidenten beperken.
Fouten in AI, zoals data-drift of hallucinaties, blijven vaak onopgemerkt, maar kunnen op de lange termijn financiële schade veroorzaken. Traditionele uptime-statistieken laten mogelijk zien dat systemen probleemloos draaien, terwijl gebrekkige outputs stilletjes resources uitputten of de bedrijfsvoering schaden.
""Organisaties moeten AI-incidenten beschouwen als sociaal-technische gebeurtenissen, niet zomaar als technische fouten." – Kate Crawford, AI Now Institute
Om de ROSI (Return on Investment) voor incidentrespons met betrekking tot AI te berekenen, koppelt u technische impacten – zoals gecompromitteerde identiteiten, getroffen resources of datalekken – aan bedrijfskritieke services. Houd statistieken bij zoals het aantal getroffen identiteiten en de laterale verspreiding van incidenten over regio's om de potentiële kosten te schatten. Efficiëntiestatistieken zoals "incidenten per persoonsuur" kunnen ook de waarde aantonen van het inzetten van extra analisten of het automatiseren van responsprocessen.
Sterke incidentresponsmogelijkheden besparen niet alleen kosten, maar bouwen ook vertrouwen op. Snellere hersteltijden en een betere paraatheid geven organisaties een concurrentievoordeel. Wanneer u kunt aantonen dat uw beveiligingsinvesteringen jaarlijks honderdduizenden dollars besparen, wordt het veel gemakkelijker om verdere of verhoogde financiering te rechtvaardigen.
Conclusie
Door de juiste statistieken bij te houden, wordt de respons op AI-incidenten een goed gestructureerd, datagestuurd proces. Statistieken zoals Gemiddelde tijd tot detectie (MTTD), Gemiddelde reactietijd (MTTR), Kosten per incident, En Rendement op beveiligingsinvestering (ROSI) Leg de basis voor het identificeren van operationele zwakke punten, het aanpakken van risicovolle meldingen en het effectiever beheren van middelen.
Fouten in AI sluipen er vaak in door problemen zoals data-drift of modelverwarring. Omdat deze fouten probabilistisch zijn, vereisen ze continue monitoring – snelle oplossingen en traditionele meetmethoden zoals uptime volstaan niet.
""Bij incidentrespons voor AI gaat het niet om het elimineren van fouten, maar om het minimaliseren van de schade wanneer er een fout optreedt." – Timnit Gebru, Distributed AI Research Institute
Door meerdere meetwaarden te combineren – ook wel triangulatie genoemd – krijgt u een duidelijker beeld van de volwassenheid van uw incidentrespons. Het uitsplitsen van gegevens naar ernst zorgt ervoor dat kritieke problemen de aandacht krijgen die ze nodig hebben. Tegelijkertijd kunt u kwaliteitsindicatoren zoals de Heropeningspercentage Dit kan aantonen of oplossingen zich richten op de kernproblemen of slechts op de symptomen. Een uitgebalanceerde meetstrategie versterkt zowel de detectie als de respons en vergroot tegelijkertijd de veerkracht van de infrastructuur. Voor organisaties die afhankelijk zijn van gespecialiseerde AI-infrastructuur is het evalueren van operationele kosten en herstelmogelijkheden eveneens van groot belang. Betrouwbare hostingopties, zoals die van Serverion, kunnen helpen de downtime te verminderen en de continuïteit te waarborgen.
Op de lange termijn leidt deze aanpak tot kostenbesparingen, sterkere relaties met toezichthouders en klanten, en een beter geïnformeerd team. Nu het aantal incidenten toeneemt, is de echte uitdaging niet om storingen volledig te voorkomen, maar om ervoor te zorgen dat uw reactie snel en effectief is.
Veelgestelde vragen
Wat zijn de eerste 3 incidentstatistieken met betrekking tot AI om bij te houden?
De drie belangrijkste meetwaarden om in de gaten te houden bij AI-incidenten zijn: detectietijd, reactietijd, En systeemherstelpercentages. Deze meetwaarden helpen inschatten hoe snel problemen worden opgemerkt, aangepakt en opgelost, wat cruciaal is voor de betrouwbaarheid en veiligheid van uw AI-systemen.
Hoe kunnen we modelafwijkingen en hallucinaties sneller opsporen?
Om modelafwijkingen en hallucinaties snel te detecteren, is het belangrijk om de prestaties van het model, de kwaliteit van de verwerkte data en de consistentie van de voorspellingen nauwlettend in de gaten te houden. Hulpmiddelen zoals realtime anomaliedetectie en gedragsmonitoring Kan problemen signaleren zodra ze zich voordoen. Bovendien biedt het realtime bijhouden van systeemstatistieken een extra laag inzicht, waardoor het gemakkelijker wordt om onverwachte resultaten of afwijkingen te herkennen voordat ze escaleren.
Hoe berekenen we de kosten per AI-incident en ROSI?
Om erachter te komen kosten per AI-incident, Neem de gemiddelde kosten van een ernstig incident (bijvoorbeeld $800 per uur) en vermenigvuldig deze met de responstijd, ook wel MTTR (Mean Time to Respond) genoemd. Berekening ROSI (Return on Security Investment) houdt in dat zowel de risicoreductie als de financiële besparingen worden beoordeeld. Het verkorten van de MTTR (Mean Time to Reconciliation) kan bijvoorbeeld leiden tot aanzienlijke jaarlijkse besparingen – mogelijk duizenden dollars – door snellere detectie en respons mogelijk te maken.




