
Belangrijkste kenmerken van gedecentraliseerde opslag van enterprise-niveau
In 2026 worden bedrijven geconfronteerd met een enorme toename van de vraag naar data, aangewakkerd door AI-agenten die gigantische bestandsvolumes verwerken en een wereldwijde data-creatie die 230-240 zettabytes bereikt. Gecentraliseerde opslagsystemen hebben moeite om dit bij te benen vanwege stijgende kosten, beveiligingsrisico's en schaalbaarheidsproblemen. Gedecentraliseerde opslag biedt een oplossing door gebruik te maken van blockchain masternode hosting, gedistribueerde architectuur en kostenefficiënte prijsmodellen. Dit maakt het uniek:
- Veerkrachtige architectuurDe gegevens worden opgesplitst in fragmenten en verdeeld over knooppunten, waardoor single points of failure worden geëlimineerd en de beschikbaarheid wordt gewaarborgd, zelfs tijdens storingen.
- Kostenbesparingen: Geen kosten voor uitgaand dataverkeer en lagere opslagkosten verlagen de uitgaven met wel 90% in vergelijking met gecentraliseerde providers zoals AWS.
- Verbeterde beveiligingClient-side encryptie, onveranderlijke auditlogboeken en ransomwarebestendige functies beschermen gegevens in elke fase.
- NalevingTools voor het beheren van de locatie van gegevens en fraudebestendige auditsporen vereenvoudigen de naleving van regelgeving zoals de AVG.
- PrestatiesParallelle gegevensopvraging en edge caching verbeteren de snelheid en schaalbaarheid voor veeleisende workloads.
- Eenvoudige migratieS3-compatibele API's maken naadloze integratie met bestaande systemen mogelijk zonder de workflows te verstoren.
Gedecentraliseerde opslag combineert beveiliging, betaalbaarheid en schaalbaarheid, waardoor het een sterke keuze is voor bedrijven die de enorme datagroei van vandaag de dag beheren.
EEA-oproep voor onderwijs: Hoe werkt gedecentraliseerde opslag en hoe zal deze worden gebruikt in het bedrijfsleven en de handel?
sbb-itb-59e1987
Gedistribueerde architectuur en dataveerkracht
Gedecentraliseerde opslag vervangt de traditionele opstelling met één server door een peer-to-peer-netwerk dat verspreid is over verschillende locaties. In plaats van uw volledige bestand in één datacenter op te slaan, verdeelt het systeem het in kleinere stukken, shards genaamd, en verdeelt deze over meerdere knooppunten. Dit ontwerp zorgt ervoor dat geen enkel knooppunt het complete bestand bevat, waardoor het risico op gegevensverlies als gevolg van hardwarestoringen of andere problemen wordt verkleind. serviceonderbrekingen.
Om nog een extra beveiligingslaag toe te voegen, wordt erasure coding ingezet. Deze methode splitst bestanden op in redundante fragmenten, waardoor het mogelijk is om gegevens te herstellen, zelfs als sommige knooppunten offline gaan. Platforms zoals Storj bewaken deze fragmenten bijvoorbeeld continu. Als de beschikbaarheid van fragmenten te laag wordt, repareert en herverdeelt het systeem ze automatisch. Door gegevens over meerdere knooppunten te verspreiden, creëert dit systeem een fouttolerant en veilig opslagnetwerk.
""Gedecentraliseerde opslagsystemen bestaan uit een peer-to-peer netwerk van gebruikers-beheerders die een deel van de totale data beheren, waardoor een robuust systeem voor het delen van bestandsopslag ontstaat." – ethereum.org
Het elimineren van enkelvoudige faalpunten
Gecentraliseerde opslagsystemen hebben een groot nadeel: als de server van de provider uitvalt of een datacenter offline is, kunnen uw gegevens ontoegankelijk worden. Gedecentraliseerde systemen lossen dit probleem op door datafragmenten te verspreiden over honderden – of zelfs duizenden – knooppunten wereldwijd. Deze opzet zorgt ervoor dat gegevens kunnen worden opgevraagd vanaf elk actief knooppunt in het netwerk, waardoor vertragingen tijdens piekbelastingen of regionale storingen worden voorkomen. Doordat de datafragmenten op meerdere locaties zijn opgeslagen, wordt het risico van een single point of failure effectief weggenomen.
Blockchain voor coördinatie zonder vertrouwen
Gedecentraliseerde opslag vertrouwt niet alleen op redundantie, maar maakt ook gebruik van blockchaintechnologie voor coördinatie. Dit houdt vaak in dat... sewa server masternodes Om de stabiliteit en veiligheid van het netwerk te waarborgen. Door middel van cryptografische uitdagingen en on-chain hash-opslag zorgt blockchain ervoor dat nodes gegevens correct bewaren en beheren, waardoor een systeem zonder vertrouwen ontstaat. Nodes worden regelmatig getest en nodes die deze tests niet doorstaan, krijgen sancties of verliezen hun beloningen.
""De auditdienst is een zeer schaalbare en performante tegenhanger van het consensusmechanisme, doorgaans een gedistribueerd grootboek, dat wordt gebruikt in andere gedecentraliseerde opslagdiensten." – Storj Docs
Sommige geavanceerde systemen maken nu gebruik van tweedimensionale foutcorrectiecodering, waardoor zelfherstellend vermogen mogelijk is. Dit betekent dat nieuwe knooppunten ontbrekende gegevens kunnen herstellen met een bandbreedte die evenredig is aan de hoeveelheid verloren gegevens. Door de wisseling van knooppunten efficiënt af te handelen, behouden deze netwerken de data-integriteit en zorgen ze ervoor dat de werking soepel blijft verlopen, zelfs wanneer knooppunten uitvallen of defect raken.
Kostenbesparing en geen uitrijkosten
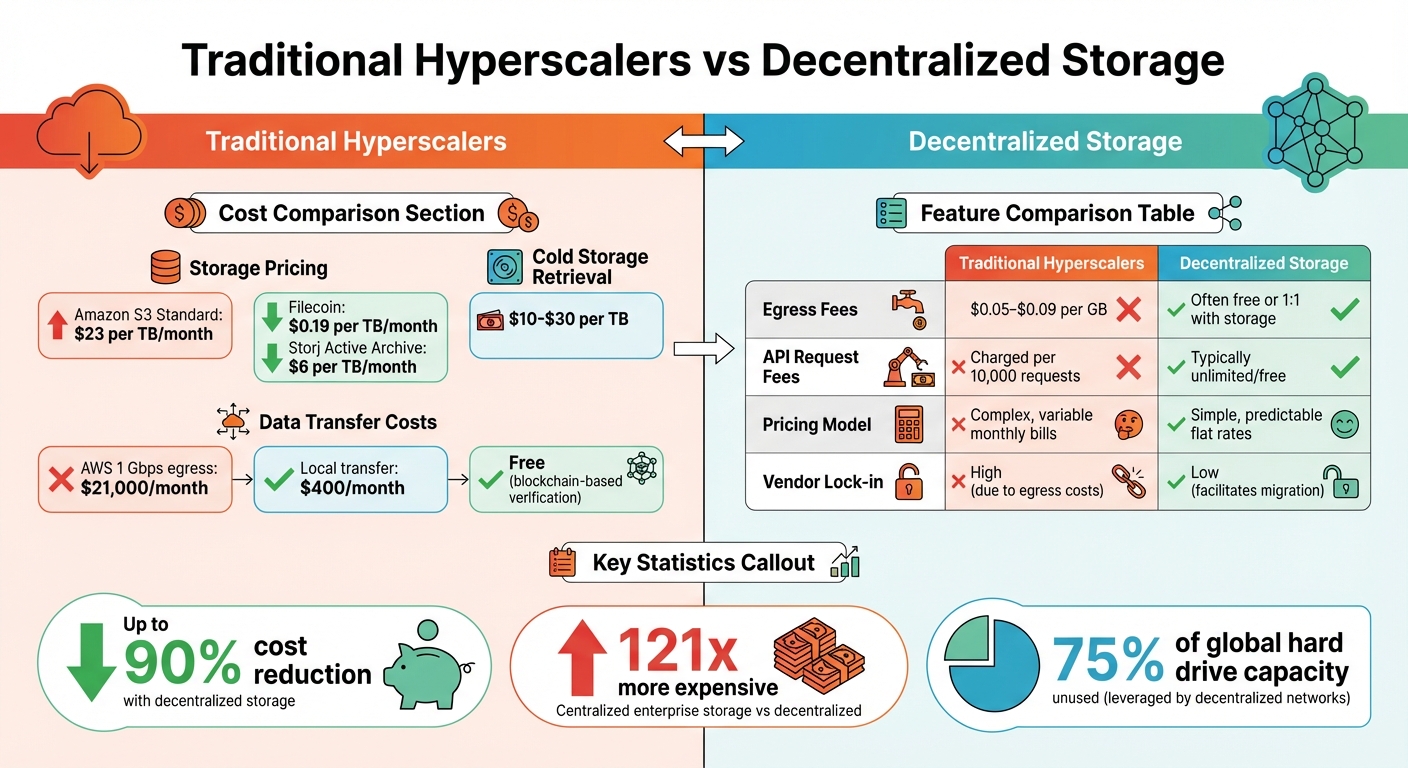
Gedecentraliseerde versus traditionele cloudopslag: kosten- en functievergelijking
Traditionele cloudproviders vertrouwen vaak op 'datagravitatie' om klanten aan zich te binden. Het concept is simpel: zodra je data bij hen is opgeslagen, wordt het verplaatsen ervan naar een andere locatie onbetaalbaar vanwege de hoge kosten voor uitgaand dataverkeer. Christine Ackley van Storj verwoordt het treffend: "In feite zijn dit exorbitante cloudcomputingbelastingen vermomd als kosten voor uitgaand dataverkeer." Om het in perspectief te plaatsen: het overdragen van slechts 1 Gbps aan data vanuit AWS kan ongeveer ... kosten. $21.000 per maand, vergeleken met ongeveer $400 per maand voor lokale overdrachten. Deze hoge kosten zetten bedrijven ertoe aan om te zoeken naar opslagoplossingen die zowel de zichtbare als de verborgen kosten verlagen.
Gedecentraliseerde opslag biedt een verfrissend alternatief door gebruik te maken van de 75% aan wereldwijde harde schijfcapaciteit die doorgaans ongebruikt blijft. In plaats van enorme, energieverslindende datacenters te bouwen en die kosten door te berekenen aan klanten, maken gedecentraliseerde netwerken gebruik van bestaande, ongebruikte opslagruimte aan de rand van het netwerk. Dit model is niet alleen efficiënter, maar kan de kosten ook met wel tot wel verlagen. 90% vergeleken met traditionele hyperscalers. Sterker nog, sommige gecentraliseerde virtuele privéservers van bedrijfsniveau kan net zoveel zijn als 121 keer duurder dan gedecentraliseerde opties.
Het verlagen van de operationele kosten
De kostenbesparingen worden nog duidelijker wanneer je de daadwerkelijke prijzen vergelijkt. Amazon S3 Standard-opslag kost bijvoorbeeld ongeveer $23 per TB per maand, terwijl gedecentraliseerde opties zoals Filecoin beginnen bij $0,19 per TB, En Storj's Active Archive-laag biedt direct toegankelijke opslag voor slechts $6 per TB per maand. Voor bedrijven die terabytes – of zelfs petabytes – aan data beheren, lopen deze besparingen snel op, vooral omdat de wereldwijde data naar verwachting zal toenemen. 221.000 exabytes in 2026.
Aanbieders van gecentraliseerde opslag verhogen de kosten vaak met extra kosten voor het ophalen van gegevens en API-toegang. Voor bedrijven die jaarlijks de integriteit van hun archief moeten verifiëren (een veelvoorkomende compliance-vereiste), kunnen deze kosten snel oplopen. De traditionele kosten voor het ophalen van gegevens uit cold storage variëren van... $10 tot $30 per TB, waardoor dergelijk onderhoud kostbaar wordt. Gedecentraliseerde opslagnetwerken omzeilen dit probleem door middel van op blockchain gebaseerde geautomatiseerde controles die de data-integriteit continu verifiëren – zonder extra kosten.
Het vermijden van onverwachte kosten en verborgen toeslagen
Naast lagere basiskosten elimineert gedecentraliseerde opslag veel verborgen kosten die traditionele aanbieders in hun prijzen verwerken. Platforms zoals Züs bieden bijvoorbeeld... Vrije toegang tot internet en onbeperkte API-aanvragen, terwijl Storj een 1:1 verhouding tussen opslagruimte en vrije gegevensoverdracht in hun wereldwijde en regionale prijsniveaus. Dit eenvoudige prijsmodel voorkomt de onaangename verrassingen die vaak voorkomen bij gecentraliseerde clouddiensten.
Hier volgt een korte vergelijking tussen gedecentraliseerde opslag en traditionele hyperscalers:
| Functie | Traditionele hyperscalers | Gedecentraliseerde opslag |
|---|---|---|
| Uitgangskosten | $0.05–$0.09 per GB | Vaak gratis of inclusief 1x de opslagcapaciteit. |
| API-aanvraagkosten | Kosten per 10.000 aanvragen | Doorgaans onbeperkt/gratis |
| Prijsmodel | Complexe, variabele maandelijkse rekeningen | Eenvoudige, voorspelbare vaste tarieven |
| Leverancierslock-in | Hoog (vanwege evacuatiekosten) | Laag (vergemakkelijkt migratie) |
Voor data-intensieve taken zoals AI-training, big data-analyse of IoT, waarbij frequente toegang tot en updates van data de norm zijn, is de afwezigheid van kosten voor data-uitvoer een gamechanger. Gedecentraliseerde opslag houdt niet alleen de kosten beheersbaar, maar stelt bedrijven ook in staat flexibel te blijven en data vrij te verplaatsen naarmate hun behoeften veranderen – zonder vast te zitten aan dure, beperkende systemen.
Beveiliging en gegevensversleuteling
Wanneer bedrijven overstappen op gedecentraliseerde opslag, wordt beveiliging een topprioriteit – vooral omdat data verspreid is over duizenden knooppunten. Gedecentraliseerde systemen zijn ontworpen om te werken met onbetrouwbare knooppunten, wat de behoefte aan strengere beveiligingsmaatregelen met zich meebrengt in vergelijking met gecentraliseerde systemen.
Een hoeksteen van dit beveiligingsmodel is client-side encryptie. Met deze methode worden uw gegevens op uw apparaat versleuteld. voordat Het verlaat uw netwerk. Dit zorgt ervoor dat de provider geen toegang heeft tot uw onversleutelde gegevens of versleutelingssleutels. Het resultaat? End-to-end bescherming die uw gegevens beveiligt tijdens het uploaden (onderweg), tijdens de opslag op gedistribueerde knooppunten (in rust) en tijdens het downloaden. Versleutelingsmethoden zoals AES-256-GCM of Geheime doos (Salsa20 en Poly1305) worden veel gebruikt en bieden vertrouwelijkheid en detectie van manipulatie. Als iemand de versleutelde gegevens wijzigt, zal uw client dit tijdens het decoderen detecteren.
Gedecentraliseerde netwerken maken ook gebruik van hiërarchische sleutelafleiding Om de beveiliging verder te verbeteren. Deze methode genereert unieke sleutels voor elk datasegment op basis van een root-sleutel. Dit betekent dat een inbreuk op één segment geen gevolgen heeft voor andere segmenten. Bovendien worden bestandspaden en metadata op uw apparaat versleuteld, waardoor aanvallers geen inzicht krijgen in uw datastructuur.
Deze gelaagde aanpak garandeert robuuste beveiliging in elke fase – of uw gegevens nu onderweg zijn, opgeslagen worden of aan audits worden onderworpen.
Versleuteling in rust en tijdens transport
In traditionele systemen worden encryptiesleutels doorgaans aan de serverzijde beheerd, waardoor providers er controle over hebben. Gedecentraliseerde opslag draait dit model om, waardoor u zelf de controle over uw encryptiesleutels krijgt. nul-kennis Deze configuratie zorgt ervoor dat zelfs als een opslagknooppunt wordt gecompromitteerd, aanvallers alleen toegang krijgen tot versleutelde datafragmenten, die zonder de sleutels nutteloos zijn.
Het versleutelingsproces is meerlaags. Eerst worden uw gegevens versleuteld en vervolgens opgesplitst in kleinere fragmenten voor redundantie en herstel. Deze versleutelde fragmenten worden verdeeld over duizenden knooppunten wereldwijd. Omdat geen enkel knooppunt een compleet bestand opslaat of de decryptiesleutels bezit, is het vrijwel onmogelijk om uw gegevens zonder toestemming te reconstrueren. De beveiliging wordt verder versterkt door Toegangssubsidies – door de client beheerde beveiligingsenveloppen met beperkte API-sleutels en padgebaseerde versleutelingssleutels. Met deze machtigingen kunt u nauwkeurige toegangscontroles afdwingen zonder uw directorystructuur of rootgeheim bloot te leggen.
Onveranderlijke auditlogboeken en gegevensverificatie
Om de dataintegriteit te waarborgen, vertrouwen gedecentraliseerde systemen op continue cryptografische controles. Dossiercontroles Regelmatig worden willekeurige gegevensfragmenten gecontroleerd om te bevestigen dat ze kunnen worden opgehaald van opslagknooppunten, vergelijkbaar met consensusmechanismen. Wanneer u uw gegevens downloadt, verifiëren geauthenticeerde encryptiealgoritmen dat er niet mee is geknoeid. Als het aantal beschikbare gegevensfragmenten onder een kritiek niveau daalt, herstelt en herverdeelt het systeem de gegevens automatisch om de duurzaamheid te waarborgen.
Ransomwarebeveiliging met Object Lock
Ransomware-aanvallen blijven een ernstige bedreiging, maar gedecentraliseerde opslag biedt sterke bescherming. Functies zoals S3-compatibel objectvergrendeling Zorg voor de onveranderlijkheid van gegevens door te voorkomen dat aangewezen bestanden worden overschreven of verwijderd totdat een ingestelde bewaartermijn is verstreken. Deze aanpak, ondersteund door branchecertificeringen, maakt het een ideale oplossing voor back-upbeveiliging.
Het koppelen van objectvergrendeling met objectversiebeheer Dit voegt een extra verdedigingslaag toe. Als ransomware uw meest recente bestanden versleutelt of als belangrijke gegevens per ongeluk worden verwijderd, kunt u eenvoudig eerdere versies herstellen. Het gedistribueerde karakter van gedecentraliseerde opslag versterkt de bescherming verder. Versleutelde fragmenten zijn verspreid over duizenden knooppunten, wat betekent dat een aanvaller meerdere knooppunten zou moeten infiltreren. en Het verkrijgen van de encryptiesleutels aan de clientzijde is een bijna onmogelijke taak. Dit maakt gedecentraliseerde opslag veel beter bestand tegen ransomware en gerichte aanvallen dan gecentraliseerde systemen.
Deze uitgebreide beveiligingsmaatregelen, gecombineerd met gedecentraliseerde strategieën van bedrijfsniveau, bieden een sterke bescherming voor uw gegevens.
| Functie | Traditionele gecentraliseerde opslag | Gedecentraliseerde opslag van enterprise-niveau |
|---|---|---|
| Eigendom van de versleutelingssleutel | Beheerd door de provider (serverzijde) | Gecontroleerd door de klant (zero-knowledge) |
| Gegevensdistributie | Opgeslagen in centrale datacenters | Opgedeeld in versleutelde fragmenten en wereldwijd verspreid. |
| Sabotagedetectie | Is afhankelijk van providerlogboeken. | Cryptografisch geverifieerd tijdens decryptie. |
| Ransomware-verdediging | Gericht op perimeterbeveiliging en back-ups. | Maakt gebruik van Immutable Object Lock en gedecentraliseerde redundantie. |
Wettelijke naleving en gegevenssoevereiniteit
Gedecentraliseerde opslag maakt het veel gemakkelijker om te voldoen aan regelgeving zoals de AVG en de CCPA. Het ontwerp geeft je directe controle over waar je gegevens worden opgeslagen en wie er toegang toe heeft. Dit niveau van controle kan een doorslaggevende factor zijn voor bedrijven en het vertrouwen in hun bedrijfsvoering vergroten. Bovendien bouwt het voort op de transparantie- en beveiligingsfuncties die al ingebouwd zijn in gedecentraliseerde opslag, zoals eerder besproken.
Een ander groot voordeel vloeit voort uit de blockchain-architectuur: fraudebestendige audit trails. Elke actie – of het nu een gegevenstransactie, een toegangsverzoek of een wijziging betreft – wordt vastgelegd in een onveranderlijk register. Dit zorgt voor duidelijk, verifieerbaar bewijs voor audits. Het ondersteunt ook de naleving van regels zoals het 'recht op verwijdering', waardoor u toegangsrechten kunt beheren en gegevensfragmenten in het netwerk kunt verwijderen zonder dat een centrale autoriteit nodig is.
De eisen ten aanzien van dataopslaglocaties worden steeds strenger. Niet-naleving van de AVG kan bijvoorbeeld leiden tot boetes van wel € 20 miljoen of 41.000.300.000 euro aan wereldwijde omzet. Tegen 2024 zullen de wereldwijde boetes naar verwachting al de 1.000.400.1,2 miljard euro overschrijden. Landen zoals India, Indonesië, Vietnam en Saoedi-Arabië hanteren ook lokale verplichtingen voor dataopslag. Gedecentraliseerde netwerken helpen u aan deze verplichtingen te voldoen door u de mogelijkheid te bieden opslaglocaties te kiezen, waardoor uw data binnen de vereiste jurisdicties, zoals de EU, blijft.
Jurisdictionele gegevens over woonplaats
Gedecentraliseerde opslagplatformen gebruiken tools zoals hostfiltering en -selectie om te voldoen aan locatiegebonden wetgeving inzake gegevensopslag. Dit betekent dat u opslagproviders kunt selecteren op basis van hun geografische locatie, samen met factoren zoals kosten en betrouwbaarheid. Technieken zoals geofencing zorgen ervoor dat gegevens de geautoriseerde regio's niet verlaten.
Versleutelingssleutels blijven ook binnen hun aangewezen locaties. Zo blijven EU-sleutels bijvoorbeeld binnen de EU. Slimme routering en geo-IP-detectie verbeteren de naleving verder door authenticatie- en opslagverzoeken naar het juiste regionale cluster te sturen op basis van de locatie van de gebruiker. Voor gevoelige gegevens kan een hybride aanpak worden gebruikt: persoonsgegevens worden opgeslagen op regionale locaties, terwijl niet-gevoelige processen gecentraliseerd blijven. Dit brengt echter extra kosten met zich mee: een implementatie in drie regio's kost ongeveer 3,2 keer zoveel als een implementatie in één regio, en in vijf regio's kan dat ongeveer 5,8 keer zoveel kosten.
Onveranderlijke bewaarbeleidsregels
In sectoren met strenge compliance-eisen, zoals de gezondheidszorg, de financiële sector en de juridische dienstverlening, zijn vaak beleidsregels voor gegevensbewaring vereist die ervoor zorgen dat informatie niet voortijdig kan worden gewijzigd of verwijderd. Gedecentraliseerde opslag handhaaft deze regels op protocolniveau. Zodra gegevens over meerdere knooppunten zijn verdeeld, wordt elke wijziging detecteerbaar.
Slimme contracten stroomlijnen de naleving van regelgeving verder door workflows voor toestemmingsbeheer, gegevensverzoeken en het afdwingen van principes voor gegevensminimalisatie te automatiseren. Functies zoals versiebeheer stellen u in staat historische gegevens op te halen en verschillende bestandsversies te beheren, wat cruciaal is tijdens audits door regelgevende instanties. Zoals Züs Network benadrukt:
""Elke transactie en elk toegangsverzoek wordt op een fraudebestendige manier vastgelegd op de blockchain, waardoor auditors en belanghebbenden de geschiedenis van gegevensinteracties kunnen traceren.""
Deze op blockchain gebaseerde gegevens bieden de traceerbaarheid die regelgeving zoals de AVG vereist. Tegelijkertijd zorgen regelmatige cryptografische controles ervoor dat datafragmenten intact en ongewijzigd blijven. Samen versterken deze compliance-tools de argumenten voor gedecentraliseerde opslag en dragen ze bij aan de kostenefficiëntie en de beveiligingsvoordelen voor bedrijven.
Prestaties en schaalbaarheid
Gedecentraliseerde opslag biedt niet alleen voordelen op het gebied van beveiliging en kosten, maar ook prestaties en schaalbaarheid die voldoen aan de eisen van veeleisende bedrijfsapplicaties. De unieke architectuur verandert de manier waarop data door een netwerk wordt verplaatst en biedt snelheden en schaalbaarheid die traditionele gecentraliseerde systemen vaak niet kunnen evenaren.
Lage latentie en hoge doorvoer
Een van de opvallende kenmerken van gedecentraliseerde opslag is het vermogen om hoge snelheden te leveren door middel van parallelle gegevensopvraging. In plaats van te vertrouwen op één server om een volledig bestand op te halen, verdeelt het systeem bestanden in kleinere fragmenten (of shards) en verdeelt deze over meerdere knooppunten. Wanneer u een bestand opvraagt, worden deze fragmenten gelijktijdig van verschillende knooppunten opgehaald, waardoor het proces wordt versneld. Zoals Kanga University uitlegt, versnelt deze methode van downloaden van meerdere bronnen het ophalen van bestanden aanzienlijk.
Geografische nabijheid speelt een cruciale rol bij het verminderen van latentie. Dataknooppunten worden geselecteerd op basis van hun nabijheid tot de gebruiker, waardoor wordt gegarandeerd dat informatie wordt verzonden vanuit nabijgelegen, hoogwaardige bronnen. Daarnaast optimaliseert dynamische load balancing de knooppuntselectie continu op basis van realtime netwerkcondities.
Voor veelgebruikte data biedt edge caching een extra boost. Gedecentraliseerde dataversnellingslagen kunnen een latentie van minder dan een milliseconde per query bereiken en tot 3000 queries per seconde verwerken op één thread. Traditionele cloudopslagoplossingen daarentegen ervaren vaak latenties van honderden milliseconden tot enkele seconden bij het verwerken van petabytes aan data. Door gedistribueerde caching bovenop hyperscale data lakes te plaatsen, hebben sommige organisaties prestatieverbeteringen tot wel 1000x gerapporteerd in vergelijking met het opvragen van Parquet-bestanden die zijn opgeslagen op conventionele cloudobjectopslag zoals AWS S3 Standard. Voor AI- en machine learning-workloads heeft gedecentraliseerde caching ook het GPU-gebruik met 20% verbeterd, waardoor de algehele systeemefficiëntie is geoptimaliseerd.
Deze snelle architectuur met lage latentie legt de basis voor schaalbaarheid in bedrijfsomgevingen.
Schaalbaarheid voor bedrijfsworkloads
Gedecentraliseerde opslagsystemen zijn ontworpen om naadloos op te schalen en te voldoen aan de eisen van grote ondernemingen. In plaats van te vertrouwen op enorme datacenters, maken deze systemen gebruik van contractgebaseerde persistentie met specifieke knooppunten, waardoor ze enorme hoeveelheden data kunnen verwerken – mogelijk tot zettabytes en meer.
Het gebruik van erasure coding en fragmentatie is essentieel voor deze schaalbaarheid. Bestanden worden opgesplitst in kleinere stukken en verspreid over een wereldwijd netwerk, waardoor parallelle data-opvraging en een hogere doorvoer mogelijk zijn. Door gebruik te maken van onderbenutte edge-opslag groeien deze netwerken organisch naarmate er meer knooppunten zich aansluiten, wat hun schaalbaarheid verder verbetert. Ter vergelijking: de Ethereum-blockchain is ongeveer 500 GB tot 1 TB groot; als data op bedrijfsniveau op een vergelijkbare manier zou worden beheerd, zou standaard blockchain-masternodes zou niet effectief kunnen functioneren.
Om de prestaties tijdens piekbelasting te behouden, vermijden gedecentraliseerde opslagsystemen de traditionele beperkingen van blockchain, zoals wereldwijde consensus. Gebruikers kunnen hun bestanden ophalen zonder het hele netwerk te synchroniseren, dankzij het vermijden van coördinatie. Netwerkpartitionering isoleert gebruikers en bestandsoverdrachten, waardoor verkeerspieken van de ene organisatie geen invloed hebben op andere organisaties. Voor bedrijven met extreem hoge doorvoereisen biedt het gebruik van dedicated metadata-managementknooppunten de mogelijkheid om knelpunten in de openbare coördinatie te omzeilen en hun infrastructuur te optimaliseren voor de beste prestaties.
Deze architectuur maakt gedecentraliseerde opslag uitermate geschikt voor dynamische bedrijfsapplicaties, of het nu gaat om het ondersteunen van AI/ML-workloads of het beheren van grootschalige back-upsystemen.
API-compatibiliteit en migratiegemak
API-compatibiliteit speelt een cruciale rol bij een soepele overgang van traditionele cloudopslag naar gedecentraliseerde infrastructuur. Het goede nieuws? U hoeft uw volledige applicatiestack niet te vernieuwen. Dankzij S3-compatibele API's kunnen bedrijven van provider wisselen zonder bestaande workflows te verstoren.
S3-compatibele API's voor eenvoudige integratie
Amazon S3 heeft de standaard gezet voor API's voor objectopslag, en de meeste bedrijfsapplicaties zijn eromheen gebouwd. Gedecentraliseerde opslagplatformen profiteren hiervan door het aanbieden van volledige S3-compatibiliteit, waardoor ze een naadloze vervanging vormen voor traditionele aanbieders.
Wat betekent dit in de praktijk? Migreren is net zo eenvoudig als het bijwerken van uw endpoint-URL en toegangsgegevens. Zoals Bill Thorp van Storj het zegt:
""Door een cloudobjectopslagsysteem compatibel te maken met deze API's, wordt het voor gebruikers veel gemakkelijker om zonder veel moeite naar nieuwe diensten te migreren.""
Als je bijvoorbeeld de AWS CLI gebruikt, hoef je alleen maar de volgende opdracht te geven: --eindpunt-url naar een gedecentraliseerde gateway zoals https://gateway.storjshare.io En voer de nieuwe inloggegevens in. Dat is alles – je tools en workflows blijven hetzelfde.
Deze compatibiliteit beperkt zich niet tot de basisfunctionaliteit. Gedecentraliseerde gateways ondersteunen standaard S3-functies zoals buckets, sleutels, HTTP-werkwoorden (GET, PUT, HEAD), multipart-uploads, objectversiebeheer en zelfs objectvergrendeling. Populaire tools van derden zoals Rclone, FileZilla, Restic en de AWS CLI werken zonder aanpassingen. Zelfs automatiseringsscripts die gebruikmaken van de Python SDK (boto3) worden ondersteund tot versie 1.35.99, wat een naadloze overgang garandeert.
Het minimaliseren van migratie-uitdagingen
Migreren hoeft geen gedoe te zijn. De documentatie van Storj laat zien hoe eenvoudig het proces kan zijn:
""Het enige wat u hoeft te doen, is bestanden naar de nieuwe buckets verwijzen en alle statische gegevens die u wilt behouden, migreren.""
Het is niet nodig om uw datamanagementsystemen opnieuw te ontwerpen of teams te trainen in onbekende interfaces. Bedrijven kunnen kiezen uit: gehoste S3-compatibele gateways voor cloud-native applicaties of zelfgehoste gateways Voor hybride of on-premise configuraties die end-to-end-versleuteling vereisen. Beide opties bieden dezelfde functionaliteit als traditionele S3-bestanden, waaronder ondersteuning voor maximaal 10.000 delen per multipart-upload en geen limiet op de totale objectgrootte. Voor bestanden groter dan 5 TB volstaat een eenvoudige aanpassing aan uw S3-client. multipart_chunksize Deze instelling zorgt voor een soepele bediening.
De voordelen gaan verder dan compatibiliteit. Klanten met beperkte bandbreedte ervaren vaak... meer dan 3x snellere toegangssnelheden vergeleken met gecentraliseerde aanbieders. En de kostenbesparingen zijn moeilijk te negeren: opslagkosten kunnen dalen tot $4.00 per TB per maand, met uitreiskosten van ongeveer $7,00 per TB – tot wel 80% lager dan conventionele cloudopslag. Voor bedrijven met specifieke eisen aan de locatie van hun gegevens, bieden de S3 "LocationConstraint"-parameters de mogelijkheid om opslagregio's te specificeren, zoals bijvoorbeeld: regionaal-1 voor gegevens die alleen voor de VS gelden of wereldwijd-1 voor wereldwijde beschikbaarheid.
Transparantie en verificatie op basis van blockchain
Blockchain-technologie bouwt voort op veilige versleutelings- en auditmechanismen en voegt een onveranderlijke laag van transparantie toe. Het waarborgt verantwoording door middel van on-chain, onveranderlijke records. In plaats van afhankelijk te zijn van één enkele aanbieder, kunnen bedrijven de integriteit van gegevens verifiëren met behulp van cryptografische bewijzen die op de blockchain zijn opgeslagen. Dit creëert een permanent, tijdgestempeld auditspoor dat niet kan worden gewijzigd.
Transparante en verifieerbare opslag
Op blockchain gebaseerde opslagsystemen garanderen gegevensbeveiliging door middel van protocollen zoals Bewijs van gegevensbezit (PDP) en Bewijs van replicatie (PoRep). Deze protocollen verifiëren dat opslagproviders daadwerkelijk beschikken over de gegevens die ze beweren op te slaan. Zoals uitgelegd in de documentatie van Filecoin:
""Proof of Data Possession (PDP) is een cryptografisch protocol waarmee een client of smart contract kan verifiëren dat een opslagprovider een dataset nog steeds bezit, zonder deze opnieuw te downloaden.""
Het proces werkt via gerandomiseerde uitdaging-antwoordmechanismen. Aanbieders moeten deze uitdagingen correct beantwoorden om de data-integriteit in realtime te garanderen. De data is gestructureerd in Merkle-bomen, Aanbieders dienen bewijzen van opname in bij de blockchain. Slimme contracten verifiëren deze bewijzen vervolgens automatisch, waardoor de opgeslagen gegevens ongewijzigd blijven. Deze functies, in combinatie met de economische prikkels van blockchain, verbeteren de databetrouwbaarheid en kostenefficiëntie – eigenschappen die essentieel zijn voor moderne ondernemingen.
Naast het veilig bijhouden van gegevens, verbetert blockchain ook de betrouwbaarheid van het netwerk door middel van op tokens gebaseerde incentives.
Gestimuleerde gegevensreplicatie
Blockchainnetwerken creëren algoritmische marktplaatsen waar aanbieders van opslag eigen tokens verdienen voor het aanbieden van betrouwbare opslag. In tegenstelling tot traditionele cryptomining, dat zich richt op het handhaven van blockchainconsensus, beloont dit model aanbieders op basis van de prestaties van de opslagprovider. nuttige opslag Zij leveren het systeem. Protocol Labs beschrijft dit systeem als volgt:
""Het protocol verweeft deze verzamelde resources tot een zelfherstellend opslagnetwerk waarop iedereen ter wereld kan vertrouwen.""
Om de betrouwbaarheid te waarborgen, voeren deze systemen geautomatiseerde audits uit en leggen ze economische sancties op. Een voorbeeld hiervan is Filecoin. WindowPost Het protocol vereist elke 30 minuten een bewijs van beschikbaarheid van de sector. Aanbieders die niet aan deze eisen kunnen voldoen, verliezen hun ingelegde onderpand en hun opslagcapaciteit wordt verminderd. Als de gegevensredundantie onder een veilige drempelwaarde daalt, activeert het netwerk automatisch mechanismen voor gegevensherstel. Dit zorgt ervoor dat uw gegevens toegankelijk blijven, zelfs als individuele knooppunten uitvallen.
Het afronden
Het kiezen van de juiste opslagoplossing is nog nooit zo belangrijk geweest, gezien de eisen op het gebied van prestaties, kostenbeheer, beveiliging, compliance en schaalbaarheid. Zoals Stefaan Vervaet van Akave treffend stelt:
""De architectuur die je in 2026 kiest, biedt je ofwel bewijs, voorspelbaarheid en controle, ofwel maakt het je kwetsbaar.""
Voor organisaties met strenge soevereiniteitsvereisten is het essentieel om te vertrouwen op cryptografisch bewijs van dataresidentie – contractuele garanties alleen zijn niet voldoende. Naar verwachting zullen in 2028 60% van dergelijke organisaties overstappen naar nieuwe cloudomgevingen om risico's buiten het grondgebied te beperken. Om de migratie te vereenvoudigen en voorspelbare AI-kosten te behouden naarmate de werklast toeneemt, is het raadzaam te focussen op oplossingen met S3-compatibele API's en zonder kosten voor uitgaand dataverkeer.
Beveiliging mag niet in het gedrang komen. Let op functies zoals client-side encryptie en erasure coding. gedistribueerde knooppunten, En onveranderlijke auditlogboeken, ondersteund door blockchainverificatie. Nu cyberaanvallen steeds vaker gebruikmaken van gestolen inloggegevens, is het elimineren van zwakke punten essentieel voor de beveiliging van uw gegevens. Bovendien, naarmate autonome AI-agenten tegen 2026 steeds vaker worden ingezet in diverse functies binnen de G2000, moet uw systeem naadloos kunnen omgaan met lees- en schrijfbewerkingen op machineniveau.
Voordat u een definitieve beslissing neemt, valideer de prestaties in een realistische omgeving. Voer een pilot van een week uit met identieke datasets op ten minste twee oplossingen. Test de duurzaamheid, latentie en kosten om ervoor te zorgen dat deze aansluiten bij uw budget en operationele behoeften. Stem uw persistentiemodel af op de levenscyclus van uw gegevens, of het nu gaat om eenmalige kosten voor permanente archieven, marktconforme contracten voor grootschalige, verifieerbare opslag of vastgezette replica's voor contentdistributie.
Naarmate de wereldwijde datasfeer in 2026 een verbazingwekkende 221.000 exabytes nadert, ontpopt gedecentraliseerde opslag – met zijn gedistribueerde, veilige en schaalbare architectuur – zich als een cruciale strategie voor bedrijven die deze ongekende data-explosie moeten beheren. Uw keuzes van vandaag bepalen uw vermogen om morgen te schalen en u aan te passen.
Veelgestelde vragen
Hoe verbetert gedecentraliseerde opslag de gegevensbeveiliging in vergelijking met traditionele gecentraliseerde systemen?
Gedecentraliseerde opslag verhoogt de gegevensbeveiliging door informatie te verspreiden over talrijke geografisch verspreide knooppunten. Deze opzet minimaliseert de kans op een enkelvoudig storingspunt, waardoor het voor cyberaanvallen, ransomware of datalekken moeilijker wordt om het systeem te compromitteren.
Daarnaast maken veel gedecentraliseerde opslagplatformen gebruik van geavanceerde versleuteling en gelaagde beveiligingsmaatregelen. Deze waarborgen zorgen ervoor dat alleen bevoegde personen toegang hebben tot de opgeslagen gegevens. Voor bedrijven betekent dit een betere controle over gevoelige informatie, terwijl de privacy goed beschermd blijft.
Wat zijn de kostenvoordelen van gedecentraliseerde opslag voor bedrijven?
Gedecentraliseerde opslag biedt bedrijven een duidelijk financieel voordeel, vooral omdat het aanzienlijk goedkoper is dan traditionele, gecentraliseerde oplossingen. De gemiddelde kosten van gedecentraliseerde opslag liggen bijvoorbeeld rond de... $2.11 per terabyte (TB) per maand, terwijl gecentraliseerde aanbieders vaak kosten in rekening brengen $9.88 of meer voor hetzelfde bedrag. Voor bedrijven met uitgebreide opslagbehoeften kan dit prijsverschil leiden tot aanzienlijke kostenbesparingen.
Bovendien elimineert gedecentraliseerde opslag verborgen kosten zoals uitgaande datakosten en vermijdt het de beperkende contracten die veel gecentraliseerde aanbieders opleggen. Dit maakt het een flexibele en budgetvriendelijke keuze voor bedrijven die hun databeheerkosten willen stroomlijnen zonder in te leveren op schaalbaarheid of beveiliging.
Hoe draagt gedecentraliseerde opslag bij aan het voldoen aan wereldwijde regelgeving op het gebied van gegevensprivacy en -beveiliging?
Gedecentraliseerde opslag helpt bedrijven te voldoen aan wereldwijde gegevensregelgeving door gebruik te maken van een gedistribueerde configuratie die de efficiëntie verhoogt. gegevensprivacy, beveiliging, En controle. In plaats van te vertrouwen op één enkele locatie, worden gegevens opgeslagen op meerdere locaties in verschillende regio's. Dit verkleint de kans op een single point of failure en beperkt het risico op ongeautoriseerde toegang. Het stelt bedrijven ook in staat om gegevens in specifieke regio's op te slaan om te voldoen aan wettelijke vereisten zoals de AVG of wetgeving inzake gegevenslokalisatie.
Veel gedecentraliseerde opslagsystemen maken ook gebruik van geavanceerde versleutelingstechnieken, zoals end-to-end-encryptie, Dit zorgt ervoor dat gevoelige informatie alleen toegankelijk is voor geautoriseerde gebruikers. Bovendien bevatten deze systemen vaak transparante audit trails, waarmee organisaties de toegang tot en wijzigingen in gegevens kunnen monitoren – een essentiële functie voor naleving van de regelgeving. Door sterke beveiligingsmaatregelen, duidelijke traceerbaarheid en regionale flexibiliteit te combineren, vereenvoudigt gedecentraliseerde opslag het proces om te voldoen aan internationale normen voor gegevensbescherming.




