
Hoe actieve-actieve replicatie zorgt voor hoge beschikbaarheid
Actieve-actieve replicatie zorgt ervoor dat systemen blijven draaien zonder uitval, zelfs tijdens storingen. Door meerdere servers tegelijkertijd het verkeer te laten verwerken, zorgt deze configuratie voor een continue dienstverlening, wordt de hersteltijd tot nul gereduceerd en worden de prestaties verbeterd. Dit is wat u moet weten:
- Wat het is: Alle servers zijn actief, delen de werklast en blijven gesynchroniseerd.
- Waarom het belangrijk is: Uitval kost bedrijven geld en vertrouwen. Actieve-actieve systemen behouden een bijna perfecte uptime (99,999%), wat neerkomt op slechts 5,26 minuten uitvaltijd per jaar.
- Hoe het werkt: Combineert taakverdeling, realtime gegevenssynchronisatie en automatische failover voor ononderbroken werking.
- Belangrijkste voordelen: Minder uitvaltijd, wereldwijde schaalbaarheid en onderhoud zonder onderbrekingen.
- Uitdagingen: Het beheren van dataconsistentie, operationele complexiteit en hogere kosten.
Deze architectuur is ideaal voor sectoren zoals e-commerce, financiën en gezondheidszorg, waar elke seconde uptime telt. Hoewel het zorgvuldige planning en middelen vereist, levert het ononderbroken service en klanttevredenheid op.
Replicatie tussen meerdere datacenters: uitleg over actieve-passieve versus actieve-actieve architectuur
sbb-itb-59e1987
Hoe werkt actieve-actieve replicatie?
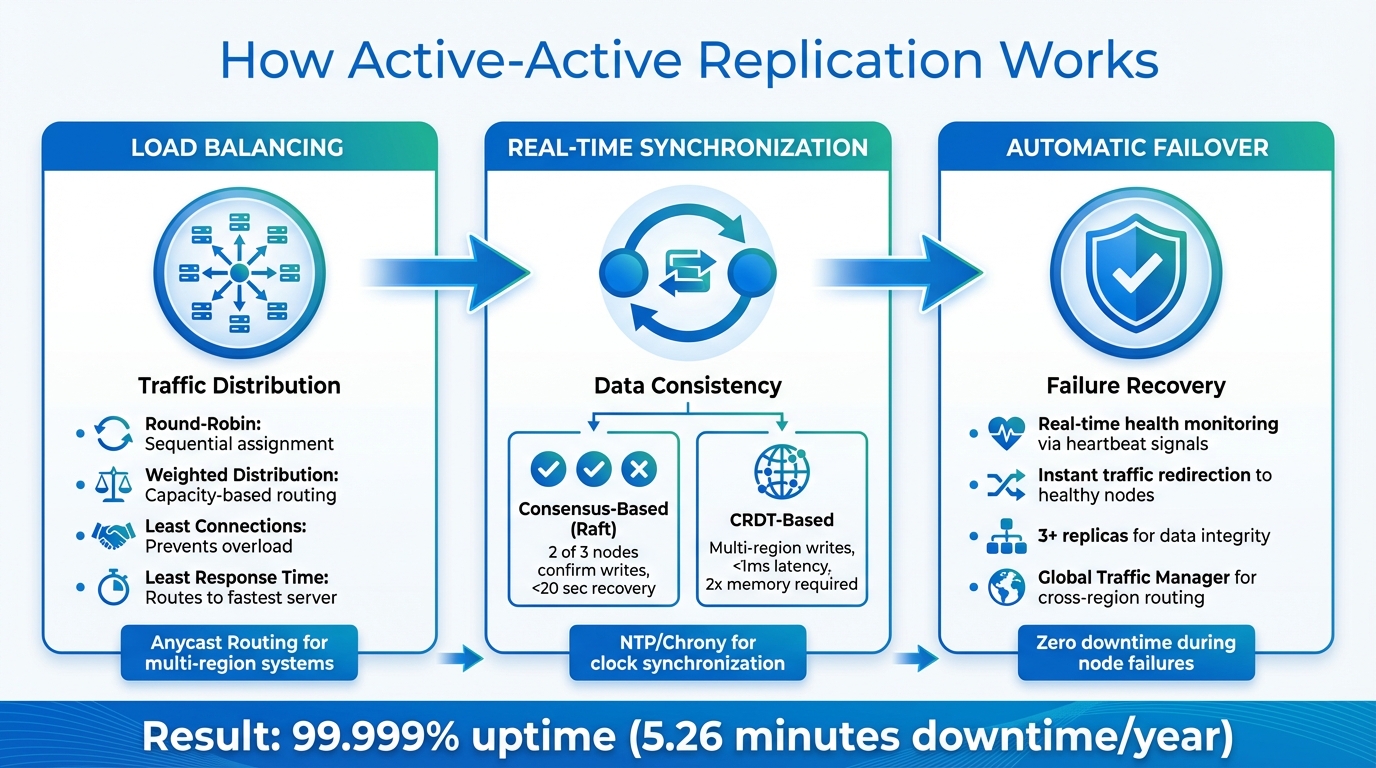
Hoe actieve-actieve replicatie werkt: drie kernmechanismen
Bij actieve-actieve replicatie draait alles om het garanderen van hoge beschikbaarheid door het combineren van verschillende technieken. lastverdeling, realtime synchronisatie, En automatische failover. Gezamenlijk vormen deze mechanismen een systeem dat soepel blijft functioneren, zelfs bij onverwachte problemen.
Taakverdeling voor verkeersdistributie
De load balancer vormt de kern van het verkeersbeheer. Deze verdeelt binnenkomende verzoeken over alle actieve knooppunten. Er worden doorgaans verschillende methoden gebruikt:
- Rondetafelgesprek: Wijs verzoeken sequentieel toe aan knooppunten. Hoewel dit eenvoudig is, houdt het geen rekening met de werkelijke werkbelasting op elke server.
- Gewogen verdeling: Stuurt meer verkeer naar virtuele privéservers met een hogere capaciteit, waardoor het ideaal is voor systemen met uiteenlopende hardware specificaties.
- Minste verbindingen: Leidt het verkeer om naar de server met de minste actieve sessies, waardoor overbelasting bij wisselende werkbelastingen wordt voorkomen.
- Kortste reactietijd: Routeert verzoeken naar de snelste server, wat cruciaal is voor applicaties waarbij lage latentie van essentieel belang is.
Voor systemen die over meerdere regio's verspreid zijn, Anycast-routering Dit is een baanbrekende ontwikkeling. Het stelt servers op verschillende locaties in staat om één enkel IP-adres te delen. Op deze manier wordt het verkeer automatisch naar de dichtstbijzijnde operationele server geleid. Als een regionaal datacenter uitvalt, wordt het verkeer naadloos en zonder onderbreking naar andere locaties overgezet.
Nu de load balancing is ingesteld, is de volgende stap ervoor te zorgen dat alle knooppunten gesynchroniseerd blijven.
Realtime gegevenssynchronisatie
Het is essentieel om de consistentie van gegevens over alle knooppunten te waarborgen, en dit wordt bereikt door continue replicatie. Verschillende systemen pakken deze uitdaging op unieke manieren aan:
- Op consensus gebaseerde systemen: Tools zoals CockroachDB gebruiken algoritmes zoals Raft om consistentie te garanderen. Een schrijfbewerking wordt pas bevestigd nadat een meerderheid (vaak 2 van de 3 knooppunten) deze heeft erkend. Deze aanpak voorkomt conflicten en kan binnen 20 seconden herstellen van netwerkonderbrekingen.
- Op CRDT gebaseerde systemen: Redis maakt gebruik van conflictvrije gerepliceerde gegevenstypen (CRDT's) om gelijktijdige schrijfbewerkingen vanuit meerdere regio's af te handelen. Hoewel lokale gegevens kortstondig kunnen verschillen, convergeren ze uiteindelijk naar één consistente staat. Een speciaal synchronisatieproces beheert wijzigingen, waarbij gedeeltelijke synchronisaties worden gebruikt voor routinematige updates en volledige synchronisaties voor het herstellen van verloren replica's.
""Active-Active databases gebruiken alleen conflictvrije gerepliceerde gegevenstypen (CRDT's). Deze gegevenstypen zorgen voor een voorspelbare conflictoplossing en vereisen geen extra werk van de applicatie- of clientzijde." – Redis Software
Systemen die gebruikmaken van CRDT's kunnen een razendsnelle lees- en schrijflatentie bereiken – vaak minder dan 1 milliseconde. Dit prestatieniveau vereist echter tot twee keer zoveel geheugen als standaardreplicatie om metadata en synchronisatieachterstanden te verwerken. Tools zoals NTP of Chrony zijn essentieel om de klokken van de knooppunten gesynchroniseerd te houden en zo een soepele communicatie binnen het cluster te garanderen.
Deze synchronisatie zorgt ervoor dat de gegevens consistent en betrouwbaar blijven, zelfs in complexe, gedistribueerde omgevingen.
Automatische failover bij knooppuntstoringen
Als knooppunten uitvallen, neemt actieve-actieve replicatie het over om de boel draaiende te houden. Dankzij load balancing en gesynchroniseerde data kan het systeem zich direct aanpassen. Zo werkt het:
- Realtime detectie: Loadbalancers en Global Traffic Managers (GTM) bewaken de status van knooppunten via heartbeat-signalen en beschikbaarheidscontroles die rekening houden met vertraging. Als een knooppunt uitvalt, wordt het verkeer onmiddellijk omgeleid naar functionerende knooppunten.
- Redis Replica HA: In configuraties zoals Redis worden replica-shards automatisch opnieuw toegewezen aan andere knooppunten, waardoor wordt voorkomen dat een enkel storingspunt de werking verstoort.
- Op consensus gebaseerde systemen: Deze systemen sturen replicatieverzoeken naar meerdere replica's (minimaal 3) om de gegevensintegriteit te waarborgen, zelfs als een van de knooppunten niet beschikbaar is.
Bij configuraties die meerdere regio's omvatten, zorgt een Global Traffic Manager ervoor dat gebruikers naar de dichtstbijzijnde operationele regio worden geleid. Health checks die rekening houden met vertragingen helpen verouderde gegevens tijdens failover te voorkomen, terwijl Redis-implementaties Pub/Sub-mechanismen kunnen gebruiken om replicatiestromen effectiever te bewaken dan met eenvoudige datasetleesbewerkingen.
Voordelen van actieve-actieve replicatie
Actieve-actieve replicatie is een revolutionaire oplossing voor het minimaliseren van downtime, het efficiënt schalen van systemen en het garanderen van ononderbroken onderhoud. Door load balancing, realtime synchronisatie en geautomatiseerde failover te combineren, biedt het een ongeëvenaarde hoge beschikbaarheid. Serverion‘De infrastructuur maakt optimaal gebruik van deze functies om systemen soepel en efficiënt te laten draaien.
Minder uitvaltijd
Een van de grootste voordelen van actieve-actieve replicatie is de mogelijkheid om downtime tot bijna nul te reduceren. Omdat alle knooppunten actief zijn en gelijktijdig verzoeken verwerken, is er geen vertraging in de activering van een back-upsysteem als een knooppunt uitvalt. De werklast wordt direct verdeeld over de resterende knooppunten, waardoor er geen merkbare verstoring optreedt.
""Om een server als 'zeer beschikbaar' te beschouwen, moet deze een netwerkbeschikbaarheid van 99,999% behalen." – Microsoft Netwerkontwikkelaarswoordenlijst
Een uptime van "vijf negens" – 99,999% – betekent slechts ongeveer 5,26 minuten downtime per jaar. Actieve-actieve architecturen elimineren single points of failure, waardoor hardwareproblemen, softwarecrashes of netwerkproblemen het systeem niet platleggen.
Maar minder downtime is nog maar het begin. Actieve-actieve replicatie blinkt ook uit bij wereldwijde schaalvergroting.
Schaalbaarheid en ondersteuning voor meerdere regio's
Actieve-actieve omgevingen maken schalen eenvoudig. Het toevoegen van nieuwe knooppunten verhoogt de systeemdoorvoer direct, omdat elk knooppunt zowel lees- als schrijfbewerkingen kan uitvoeren. Deze horizontale schaling zorgt ervoor dat de prestaties lineair toenemen met elk extra knooppunt.
Geografische spreiding gaat nog een stap verder. Door knooppunten over verschillende regio's te verspreiden – bijvoorbeeld één in Virginia, een in Californië en een in Ierland – worden gebruikers verbonden met het dichtstbijzijnde knooppunt. Deze opzet zorgt voor razendsnelle reactietijden, vaak minder dan 1 milliseconde, voor zowel het lezen als schrijven van gegevens. Bovendien wordt, als een datacenter uitvalt door een storing of ramp, het verkeer automatisch omgeleid naar andere knooppunten zonder serviceonderbreking.
Onderhoud zonder serviceonderbreking
Routinematig onderhoud vereist geen downtime of voorafgaande waarschuwingen aan klanten. Dezelfde realtime synchronisatie die knooppuntstoringen afhandelt, ondersteunt ook naadloos onderhoud. Wanneer een knooppunt updates, beveiligingspatches of hardwarevervangingen nodig heeft, kan het offline worden gehaald terwijl de andere knooppunten al het inkomende verkeer blijven verwerken.
""Oracle GoldenGate biedt deze actieve-actieve oplossingen voor zowel hoge beschikbaarheid als upgrades en migratieprojecten zonder downtime." – Oracle
Zodra het onderhoud is voltooid, synchroniseert het offline knooppunt automatisch opnieuw met alle updates die het heeft gemist. Deze aanpak zorgt ervoor dat systemen veilig en up-to-date blijven zonder gebruikers of bedrijfsactiviteiten te verstoren.
Uitdagingen bij actieve-actieve implementaties
Actieve-actieve replicatie biedt onmiskenbare voordelen, maar brengt organisaties ook een aantal technische uitdagingen met zich mee. Een succesvolle implementatie van deze configuratie vereist zorgvuldig beheer van coördinatie, consistentie en kosten in gedistribueerde systemen.
Het waarborgen van dataconsistentie
Realtime synchronisatie vormt de ruggengraat van de betrouwbaarheid in actieve-actieve implementaties, maar brengt ook aanzienlijke uitdagingen met zich mee. Een van de lastigste problemen is het gelijktijdig verwerken van gegevensschrijfbewerkingen op verschillende knooppunten. Als bijvoorbeeld twee gebruikers tegelijkertijd hetzelfde record bijwerken op verschillende servers, moet het systeem bepalen welke wijziging behouden blijft. Gangbare strategieën om deze conflicten op te lossen zijn onder andere "laatste schrijfbewerking wint", het toewijzen van prioriteit aan specifieke knooppunten of het gebruik van aangepaste samenvoegingslogica.
""Multi-master elimineert geen conflicten, het verplaatst ze alleen. In deze situaties zullen er conflicten ontstaan, sommige door vertraging, andere om andere redenen. De oplossingslogica wordt dan cruciaal.""
- Jan Wieremjewicz, Senior Product Manager, Percona
De geografische afstand tussen knooppunten voegt een extra laag complexiteit toe. Netwerklatentie tussen de VS en Australië kan bijvoorbeeld een retourvertraging van 150-200 ms veroorzaken, waardoor knooppunten mogelijk tijdelijk verouderde gegevens leveren of recente updates missen tijdens een failover. Dit probleem wordt verergerd door problemen met kloksynchronisatie; als de serverklokken afwijken, kan conflictoplossing op basis van tijdstempels onbetrouwbaar worden, wat de consistentie verder bemoeilijkt.
Operationele complexiteit
Het beheren van een actief-actief systeem is allesbehalve eenvoudig. Deze omgevingen vereisen specialistische kennis en voortdurend toezicht. Routinetaken, zoals schema-updates of implementaties, brengen een groter risico met zich mee op verstoring van de replicatie en vereisen nauwgezette planning om downtime te voorkomen.
""Actief-actief is niet de snelle oplossing die het vaak lijkt te zijn. Het is niet simpelweg 'HA, maar dan beter'. Het vertegenwoordigt een fundamentele verandering in het systeemontwerp met aanzienlijke, doorlopende kosten voor engineering, operations en productmanagement."‘
- Jan Wieremjewicz, Senior Product Manager, Percona
Operationele monitoring wordt aanzienlijk veeleisender in actieve-actieve configuraties. Teams moeten de replicatievertraging, de status van de knooppunten, consistentiecontroles en transactietracering over meerdere beschrijfbare knooppunten nauwlettend in de gaten houden. Bovendien vereisen deze systemen vaak meer geheugen – soms wel twee keer zoveel als standaard replicatieconfiguraties – om metadata en synchronisatieachterstanden te beheren. In sommige gevallen kunnen verwijderingsbeleidsregels worden geactiveerd wanneer het geheugengebruik 80% bereikt om een soepele verspreiding over clusters te garanderen.
Kostenimplicaties
Actieve-actieve implementaties brengen een flink prijskaartje met zich mee. Ze vereisen meer hardware, een hogere netwerkbandbreedte en hooggekwalificeerd personeel om het systeem te beheren. Bovendien gaan actieve-actieve oplossingen op bedrijfsniveau vaak gepaard met hoge licentiekosten in vergelijking met standaardconfiguraties. Voordat organisaties zich vastleggen op een dergelijke architectuur, moeten ze zorgvuldig overwegen of eenvoudigere opties – zoals regionale leesreplica's, sharding of actieve-passieve configuraties – aan hun behoeften kunnen voldoen tegen lagere kosten. Hoewel deze uitdagingen aanzienlijk zijn, is het essentieel om ze aan te pakken om de hoge beschikbaarheid te bereiken die actieve-actieve architecturen beogen te leveren.
Veelvoorkomende actieve-actieve implementatiepatronen
Organisaties gebruiken verschillende beproefde patronen voor de implementatie van actieve-actieve replicatie, elk afgestemd op specifieke operationele behoeften. Deze benaderingen bouwen voort op de kernmechanismen van actieve-actieve systemen en passen deze toe in verschillende implementatiescenario's. De keuze voor het juiste patroon hangt af van de vereisten en beperkingen van uw systeem.
Databaseclusters met meerdere regio's
Een van de meest populaire patronen is het distribueren van databaseclusters over meerdere geografische regio's. Bij deze opzet worden onafhankelijke databaseclusters geplaatst op locaties zoals de oostkust van de VS, Europa en Azië, waarbij elk cluster lokale lees- en schrijfbewerkingen beheert. Gebruikers maken verbinding met het dichtstbijzijnde cluster, waardoor de continuïteit gewaarborgd wordt. latentie van minder dan een milliseconde voor lokale verzoeken. Het synchroniseren van gegevens tussen regio's brengt echter vertragingen met zich mee vanwege de fysieke afstanden.
Als een gebruiker bijvoorbeeld zijn profiel in New York bijwerkt, kan het even duren voordat de wijziging in Europa of Azië zichtbaar is. Systemen zoals CockroachDB lossen dit op door middel van consensusgebaseerde replicatie, waarbij een meerderheid van de replica's (meestal drie) een schrijfbewerking moet bevestigen voordat deze wordt doorgevoerd. Dit garandeert een sterke consistentie over alle knooppunten.
""Multi-active availability biedt voordelen die vergelijkbaar zijn met traditionele concepten van hoge beschikbaarheid, maar stelt u ook in staat om vanaf elk knooppunt in uw cluster te lezen en te schrijven zonder conflicten te veroorzaken." – CockroachDB
Dit patroon is zeer geschikt voor wereldwijde applicaties die moeten voldoen aan wetgeving inzake gegevensopslaglocatie, of voor systemen met veel verkeer zoals e-commerceplatforms en financiële diensten. Het is echter mogelijk niet de beste keuze voor applicaties met complexe transactielogica die geen uiteindelijke consistentie kunnen garanderen.
Sommige implementaties gaan nog een stap verder door replicatielogica direct in de applicatielaag te integreren voor extra veerkracht.
Replicatie op applicatieniveau
Bij dit model is de failover-logica direct in de applicatie ingebouwd, in plaats van volledig afhankelijk te zijn van de database. De applicatie bewaakt actief de status van de databasereplica's en schakelt over naar een andere verbinding wanneer een storing wordt gedetecteerd. Als bijvoorbeeld een lokale Redis-replica offline gaat, kan de applicatie direct overschakelen naar een externe replica in een andere regio.
Een publicatie-/abonnementsmechanisme wordt vaak gebruikt om de betrouwbaarheid te verhogen door de status van replica's bij te houden. Hoewel deze aanpak ontwikkelaars meer controle geeft over de afwegingen tussen consistentie en betrouwbaarheid, brengt het ook uitdagingen met zich mee. Asynchrone replicatie tijdens failover kan leiden tot het missen van schrijfbewerkingen.
""Failover bij een actieve-actieve verbinding kan de beschikbaarheid van gegevens verbeteren, maar kan de consistentie van de gegevens negatief beïnvloeden. Een applicatie die overschakelt naar een andere replica kan schrijfbewerkingen missen." – Redis
Deze methode biedt flexibiliteit, maar vereist een zorgvuldig ontwerp om beschikbaarheid en consistentie in balans te brengen.
Replicatie van virtuele machines en servers
Een andere aanpak omvat het repliceren van virtuele machines (VM's) en servers over verschillende locaties. Hierbij worden vaak "stretch clusters" gebruikt, waarbij hosts op twee fysieke locaties binnen dezelfde gevirtualiseerde omgeving opereren. Synchroon gerepliceerde opslag die toegankelijk en beschrijfbaar is vanaf beide locaties, samen met een Layer 2-netwerkverbinding met lage latentie, is essentieel voor deze configuratie.
Dit model is ideaal voor noodherstel en bedrijfscontinuïteit. Tijdens normale bedrijfsvoering kunnen de werklasten over de twee locaties worden verdeeld. In geval van een storing worden alle werklasten automatisch naar de overgebleven locatie gemigreerd. De implementatie hiervan vereist echter een aanzienlijke infrastructuur, waaronder gedeelde netwerken en gesynchroniseerde opslag, wat de kosten en complexiteit kan verhogen.
Conclusie
Actieve-actieve replicatie speelt een cruciale rol voor bedrijven waar zelfs een moment van downtime onacceptabel is. Door alle knooppunten online te houden en actief het verkeer te laten verwerken, zorgt deze configuratie voor een continue beschikbaarheid van alle knooppunten. Hersteltijddoelstelling (RTO) van nul – Je hoeft niet te wachten tot een back-upserver in werking treedt, want alle servers zijn al actief.
Zoals eerder vermeld, biedt deze architectuur duidelijke operationele voordelen, waaronder een hogere beschikbaarheid en betere prestaties. In tegenstelling tot actieve-passieve systemen, waarbij resources ongebruikt blijven, maken actieve-actieve configuraties optimaal gebruik van de hardware. Failover vindt binnen enkele seconden plaats en moderne ontwerpen garanderen minimale latentie voor lokale verzoeken. Voor sectoren zoals aandelenhandelsplatformen of telecomdiensten, waar elke milliseconde telt, kan dit prestatieniveau een doorslaggevende factor zijn.
""De tolerantie voor dataverlies is in de meeste sectoren vrijwel tot nul gedaald. Waar minuten downtime vroeger nog acceptabel waren, ligt het acceptabele niveau van downtime tegenwoordig ook rond de enkele minuten of zelfs seconden." – Whitepaper van Precisely
Deze betrouwbaarheid brengt echter extra complexiteit met zich mee. Het waarborgen van dataconsistentie over meerdere actieve knooppunten vereist geavanceerde mechanismen voor conflictoplossing, gesynchroniseerde klokken en constante monitoring van replicatievertragingen. Bovendien kan de geheugenbehoefte verdubbelen om metadata en replicatieachterstanden te verwerken. Maar voor organisaties waar uptime direct van invloed is op de omzet en het klantvertrouwen, zijn deze uitdagingen een noodzakelijke afweging.
Of u nu databaseclusters beheert die meerdere regio's beslaan, replicatie op applicatieniveau gebruikt of stretchclusters over datacenters uitrolt, actieve-actieve replicatie maakt hoge beschikbaarheid een praktische realiteit. Het is niet zomaar een ontwerpkeuze, maar een strategische noodzaak voor bedrijven die zich geen onderbrekingen kunnen veroorloven. Met de geavanceerde actieve-actieve replicatieoplossingen van Serverion blijven uw services toegankelijk, ongeacht de obstakels.
Veelgestelde vragen
Wanneer moet ik kiezen voor actief-actief in plaats van actief-passief?
Wanneer uw applicatie dit vereist constante beschikbaarheid, topprestaties tijdens verkeersdrukte, schaalbaarheid, En geografische redundantie, Een actieve-actieve configuratie is de beste oplossing. Hoewel dit hogere infrastructuurkosten en meer complexiteit met zich meebrengt, biedt het een hoge betrouwbaarheid en beschikbaarheid voor systemen die zich geen downtime kunnen veroorloven.
Hoe voorkomen actieve-actieve systemen schrijfconflicten?
Actieve-actieve systemen pakken schrijfconflicten aan door gebruik te maken van conflictvrije gerepliceerde gegevenstypen (CRDT's). Deze zijn ontworpen om te zorgen voor uiteindelijke consistentie Door lees- en schrijfbewerkingen automatisch te synchroniseren over meerdere replica's, lossen CRDT's conflicten zelf op, waardoor handmatige correcties overbodig zijn. Deze methode zorgt voor consistente gegevens en ondersteunt tegelijkertijd een hoge beschikbaarheid in gedistribueerde systemen.
Wat is er nodig om een actieve-actieve configuratie in meerdere regio's te implementeren?
Het uitvoeren van actieve-actieve replicatie over verschillende regio's vereist een wereldwijde verkeersmanagementoplossing om verzoeken effectief te routeren. Dit kan worden bereikt met behulp van tools zoals DNS-gebaseerde verkeersmanagers of loadbalancers. De configuratie vereist ook een infrastructuur die geschikt is voor... synchronisatie van gegevensreplicatie met behoud van consistentie, vaak door middel van benaderingen zoals uiteindelijke consistentie.
Om een veilig en betrouwbaar systeem te garanderen, implementeer TLS-versleuteling voor netwerkbeveiliging. Daarnaast is het cruciaal om rekening te houden met factoren zoals latentie, operationele kosten, en de complexiteit van management. Deze overwegingen zijn essentieel voor het handhaven van een hoge beschikbaarheid en robuuste mogelijkheden voor noodherstel.




