
How Active-Active Replication Ensures High Availability
Active-active replication keeps systems running with no downtime, even during failures. By having multiple servers handle traffic simultaneously, this setup ensures continuous service, reduces recovery time to zero, and improves performance. Here’s what you need to know:
- What it is: All servers are live, sharing the workload and staying synchronized.
- Why it matters: Downtime costs businesses money and trust. Active-active systems maintain near-perfect uptime (99.999%), translating to just 5.26 minutes of downtime annually.
- How it works: Combines load balancing, real-time data syncing, and automatic failover for uninterrupted operations.
- Key benefits: Reduced downtime, global scalability, and maintenance without disruptions.
- Challenges: Managing data consistency, operational complexity, and higher costs.
This architecture is ideal for industries like e-commerce, finance, and healthcare, where every second of uptime counts. While it requires careful planning and resources, the payoff is uninterrupted service and customer satisfaction.
Multi-Data Center Replication: Active-Passive vs Active-Active Architecture Explained
sbb-itb-59e1987
How Active-Active Replication Works
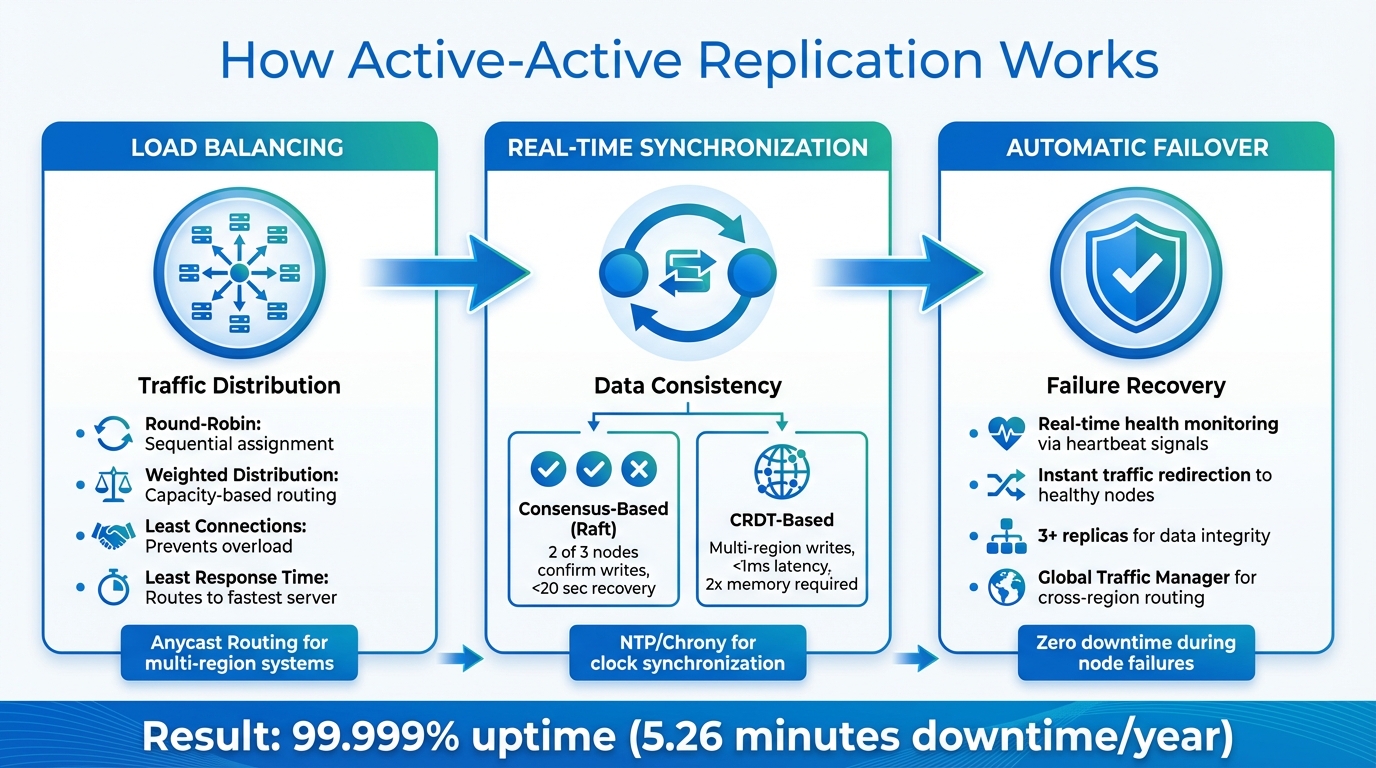
How Active-Active Replication Works: Three Core Mechanisms
Active-active replication is all about ensuring high availability by combining load balancing, real-time synchronization, and automatic failover. Together, these mechanisms create a system that keeps running smoothly, even when faced with unexpected hiccups.
Load Balancing for Traffic Distribution
At the heart of traffic management is the load balancer, which distributes incoming requests across all active nodes. Several methods are commonly used:
- Round-Robin: Assigns requests sequentially to nodes. While simple, it doesn’t account for the actual workload on each server.
- Weighted Distribution: Sends more traffic to virtual private servers with higher capacity, making it ideal for systems with varying hardware specifications.
- Least Connections: Directs traffic to the server handling the fewest active sessions, preventing overload during uneven workloads.
- Least Response Time: Routes requests to the fastest server, which is crucial for applications where low latency is key.
For systems spread across multiple regions, Anycast Routing is a game-changer. It allows servers in different locations to share a single IP address. This way, traffic is automatically routed to the nearest healthy node. If a regional data center goes offline, traffic seamlessly shifts to other locations without interruption.
With load balancing in place, the next step is to ensure that all nodes stay synchronized.
Real-Time Data Synchronization
Keeping data consistent across nodes is essential, and this is achieved through continuous replication. Different systems tackle this challenge in unique ways:
- Consensus-Based Systems: Tools like CockroachDB use algorithms such as Raft to ensure consistency. A write is only confirmed after a majority (often 2 out of 3 nodes) acknowledges it. This approach avoids conflicts and can recover from network partitions in under 20 seconds.
- CRDT-Based Systems: Redis employs Conflict-free Replicated Data Types (CRDTs) to handle simultaneous multi-region writes. While local data might briefly differ, it eventually converges to a single consistent state. A dedicated synchronization process manages changes, using partial syncs for routine updates and full syncs for recovering lost replicas.
"Active-Active databases only use conflict-free replicated data types (CRDTs). These data types provide a predictable conflict resolution and don’t require any additional work from the application or client side." – Redis Software
Systems leveraging CRDTs can achieve lightning-fast read and write latency – often under 1 millisecond. However, this level of performance requires up to twice the memory of standard replication to handle metadata and synchronization backlogs. Tools like NTP or Chrony are critical for keeping node clocks synchronized, ensuring smooth communication across the cluster.
This synchronization ensures the data remains consistent and reliable, even in complex, distributed setups.
Automatic Failover During Node Failures
When nodes fail, active-active replication steps in to keep things running. Thanks to load balancing and synchronized data, the system can instantly adapt. Here’s how it works:
- Real-Time Detection: Load balancers and Global Traffic Managers (GTM) monitor node health through heartbeat signals and lag-aware availability checks. If a node goes down, traffic is immediately redirected to healthy nodes.
- Redis Replica HA: In setups like Redis, replica shards are automatically reassigned to other nodes, ensuring no single point of failure disrupts operations.
- Consensus-Based Systems: These systems send replication requests to multiple replicas (at least 3) to maintain data integrity, even if one node becomes unavailable.
For cross-region setups, a Global Traffic Manager ensures users are routed to the nearest operational region. Lag-aware health checks help avoid stale data during failover, while Redis implementations can use Pub/Sub mechanisms to monitor replication streams more effectively than simple dataset reads.
Benefits of Active-Active Replication
Active-active replication is a game-changer for minimizing downtime, scaling systems efficiently, and ensuring uninterrupted maintenance. By combining load balancing, real-time synchronization, and automated failover, it delivers high availability like no other. Serverion‘s infrastructure takes full advantage of these features to keep systems running smoothly and efficiently.
Reduced Downtime
One of the standout advantages of active-active replication is its ability to reduce downtime to near-zero levels. Since all nodes are active and processing requests simultaneously, there’s no delay waiting for a backup system to activate if one node fails. The workload is instantly distributed among the remaining nodes, ensuring zero noticeable disruption.
"For a server to be considered ‘highly available’, it needs to achieve 99.999% network uptime." – Microsoft Network Developer Glossary
Achieving "five nines" uptime – 99.999% – means only about 5.26 minutes of downtime per year. Active-active architectures eliminate single points of failure, ensuring that hardware issues, software crashes, or network problems don’t bring the system down.
But reduced downtime is just the beginning. Active-active replication also shines when it comes to scaling globally.
Scalability and Multi-Region Support
Active-active environments make scaling simple. Adding new nodes increases system throughput immediately since every node can handle both reads and writes. This horizontal scaling allows performance to grow linearly with each additional node.
Geographic distribution takes things a step further. By spreading nodes across regions – for example, one in Virginia, another in California, and a third in Ireland – users are connected to the nearest node. This setup delivers lightning-fast response times, often under 1 millisecond, for both data reads and writes. Plus, if a data center goes offline due to an outage or disaster, traffic is automatically rerouted to other nodes without any service interruption.
Maintenance Without Service Disruption
Routine maintenance no longer requires downtime or advance warnings to customers. The same real-time synchronization that handles node failures also supports seamless maintenance. When a node needs updates, security patches, or hardware replacements, it can be taken offline while the other nodes continue managing all incoming traffic.
"Oracle GoldenGate provides these active-active solutions for both High Availability as well as Zero-Downtime upgrades and migration projects." – Oracle
Once maintenance is complete, the offline node automatically re-synchronizes with any updates it missed. This approach ensures systems stay secure and up-to-date without ever disrupting users or business operations.
Challenges in Active-Active Deployments
Active-active replication offers undeniable advantages, but it also presents organizations with a series of technical challenges. Successfully implementing this setup requires careful management of coordination, consistency, and costs in distributed systems.
Managing Data Consistency
Real-time synchronization is the backbone of reliability in active-active deployments, but it also brings significant challenges. One of the toughest issues is handling simultaneous data writes across different nodes. For example, if two users update the same record at the same time on separate servers, the system must decide which change to keep. Common strategies to resolve these conflicts include "Last Write Wins", assigning priority to specific nodes, or employing custom merge logic.
"Multi-master does not eliminate contention, it just moves it. In these situations you will have conflicts, some due to lag, some for other reasons. Resolution logic becomes critical."
- Jan Wieremjewicz, Senior Product Manager, Percona
Geographic distance between nodes adds another layer of complexity. For instance, network latency between the US and Australia can introduce round-trip delays of 150–200 ms, potentially causing nodes to serve stale data temporarily or miss recent updates during a failover. This issue is compounded by clock synchronization problems; if server clocks drift, timestamp-based conflict resolution can become unreliable, further complicating consistency.
Operational Complexity
Running an active-active system is far from straightforward. These environments demand specialized knowledge and constant oversight. Routine tasks, such as schema updates or deployments, carry a higher risk of disrupting replication and require meticulous planning to avoid downtime.
"Active-active is not the shortcut it often appears to be. It’s not simply ‘HA but better.’ It represents a fundamental system design change with significant, ongoing costs across engineering, operations, and product management."
- Jan Wieremjewicz, Senior Product Manager, Percona
Operational monitoring becomes significantly more demanding in active-active setups. Teams need to keep a close eye on replication lag, node health, consistency checks, and transaction tracing across multiple writable nodes. Additionally, these systems often require more memory – sometimes twice as much as standard replication setups – to manage metadata and synchronization backlogs. In some cases, eviction policies may activate when memory usage hits 80% to ensure smooth propagation across clusters.
Cost Implications
Active-active deployments come with a hefty price tag. They require more hardware resources, higher network bandwidth, and highly skilled personnel to manage the system. On top of that, enterprise-grade active-active solutions often come with steep licensing costs compared to standard configurations. Before committing to such an architecture, organizations should carefully consider whether simpler options – like regional read replicas, sharding, or active-passive setups – could meet their needs at a lower cost. While these challenges are substantial, addressing them is essential for achieving the high availability that active-active architectures aim to deliver.
Common Active-Active Deployment Patterns
Organizations use several well-established patterns to implement active-active replication, each tailored to meet specific operational needs. These approaches build on the core mechanisms of active-active systems, applying them in different deployment scenarios. Picking the right pattern depends on your system’s requirements and constraints.
Multi-Region Database Clusters
One of the most popular patterns is distributing database clusters across multiple geographic regions. This setup places independent database clusters in locations like the US East Coast, Europe, and Asia, with each cluster managing local read and write operations. Users connect to the nearest cluster, ensuring sub-millisecond latency for local requests. However, synchronizing data across regions introduces delays due to the physical distances involved.
For example, if a user updates their profile in New York, it might take some time for the change to appear in Europe or Asia. Systems like CockroachDB address this by using consensus-based replication, which requires a majority of replicas (typically three) to confirm a write before it’s committed. This ensures strong consistency across all nodes.
"Multi-active availability provides benefits similar to traditional notions of high availability, but also lets you read and write from every node in your cluster without generating any conflicts." – CockroachDB
This pattern is well-suited for global applications that require compliance with data residency laws or for high-traffic systems like e-commerce platforms and financial services. However, it may not be the best choice for applications with intricate transaction logic that cannot handle eventual consistency.
Some deployments take this further by incorporating replication logic directly into the application layer for added resilience.
Application-Level Replication
In this pattern, failover logic is built directly into the application, rather than relying solely on the database. The application actively monitors the health of database replicas and switches connections when it detects a failure. For instance, if a local Redis replica goes offline, the application can immediately reroute to a remote replica in another region.
A publish/subscribe mechanism is often used to enhance reliability by keeping track of replica health. While this approach offers developers more control over consistency trade-offs, it comes with challenges. Asynchronous replication during failover can result in missing write operations.
"Active-Active connection failover can improve data availability, but can negatively impact data consistency. An application that fails over to another replica can miss write operations." – Redis
This method provides flexibility but requires careful design to balance availability and consistency.
Virtual Machine and Server Replication
Another approach involves replicating virtual machines (VMs) and servers across different sites. This often uses "stretch clusters", where hosts in two physical locations operate within the same virtualized environment. Synchronously replicated storage that is accessible and writeable from both sites, along with low-latency Layer 2 network connectivity, is essential for this setup.
This pattern is ideal for disaster recovery and business continuity. During normal operations, workloads can be distributed between the two sites. In the event of a failure, all workloads are automatically migrated to the surviving site. However, implementing this requires significant infrastructure, including shared networks and synchronized storage, which can increase both cost and complexity.
Conclusion
Active-active replication plays a critical role for businesses where even a moment of downtime is unacceptable. By keeping all nodes online and actively handling traffic, this setup achieves a Recovery Time Objective (RTO) of zero – there’s no need to wait for a backup server to kick in because every server is already in action.
As mentioned earlier, this architecture offers clear operational benefits, including improved uptime and performance. Unlike active-passive systems that leave resources idle, active-active configurations make full use of the hardware. Failover happens in seconds, and modern designs ensure minimal latency for local requests. For industries like stock trading platforms or telecom services, where every millisecond counts, this level of performance can be a game-changer.
"Tolerance for data loss in most industries has gone towards zero. Where minutes of downtime were once accepted, the tolerable level of downtime today is also moving towards single-digit minutes or even seconds." – Precisely White Paper
However, this reliability comes with added complexity. Ensuring data consistency across multiple active nodes requires advanced conflict-resolution mechanisms, synchronized clocks, and constant monitoring for replication lag. Additionally, memory demands may double to handle metadata and replication backlogs. But for organizations where uptime directly affects revenue and customer trust, these challenges are a necessary trade-off.
Whether you’re managing multi-region database clusters, using application-level replication, or deploying stretch clusters across data centers, active-active replication turns high availability into a practical reality. It’s not just a design choice – it’s a strategic necessity for businesses that can’t afford interruptions. With Serverion’s advanced active-active replication solutions, your services remain accessible, no matter the obstacles.
FAQs
When should I choose active-active over active-passive?
When your application demands constant availability, top performance during traffic surges, scalability, and geographic redundancy, an active-active setup is the way to go. While it does come with increased infrastructure expenses and added complexity, it delivers strong reliability and availability for systems that can’t afford downtime.
How do active-active systems prevent write conflicts?
Active-active systems tackle write conflicts by leveraging conflict-free replicated data types (CRDTs). These are designed to ensure eventual consistency by automatically syncing read and write operations across multiple replicas. CRDTs resolve conflicts on their own, eliminating the need for manual fixes. This method keeps data consistent while supporting high availability in distributed systems.
What is required to run active-active across regions?
Running active-active replication across regions demands a global traffic management solution to handle request routing effectively. This can be achieved using tools like DNS-based traffic managers or load balancers. The setup also requires infrastructure capable of synchronizing data replication while maintaining consistency, often through approaches like eventual consistency.
To ensure a secure and reliable system, implement TLS encryption for network security. Additionally, it’s critical to account for factors such as latency, operational costs, and the complexity of management. These considerations are essential to maintain high availability and robust disaster recovery capabilities.




