
Beste werkwijzen voor frameworks voor het observeren van containers
Containerobservatie helpt je te begrijpen Waarom en hoe Problemen doen zich voor in containersystemen, waarbij gebruik wordt gemaakt van metrics, logs en traces. Omdat containers vluchtig en complex zijn, schiet traditionele monitoring vaak tekort. Dit is wat u moet weten:
- Metrieken: Houd de prestaties van de container bij (bijv. CPU- en geheugengebruik).
- Logboeken: Verzamel containerlogs centraal voor eenvoudigere probleemoplossing.
- Sporen: Volg verzoeken via microservices om knelpunten te vinden.
Om succes te behalen, standaardiseer je je observatie-instellingen met tools zoals OpenTelemetry, beheer je data efficiënt om de kosten te beheersen en integreer je beveiligingsmaatregelen zoals imagescanning en runtime-monitoring. Deze stappen zorgen voor een snellere probleemoplossing en een betere systeem betrouwbaarheid.
Stroomstoringen kunnen tot wel $500.000 per uur, Investeren in observeerbaarheid is cruciaal voor zowel de technische als de financiële gezondheid.
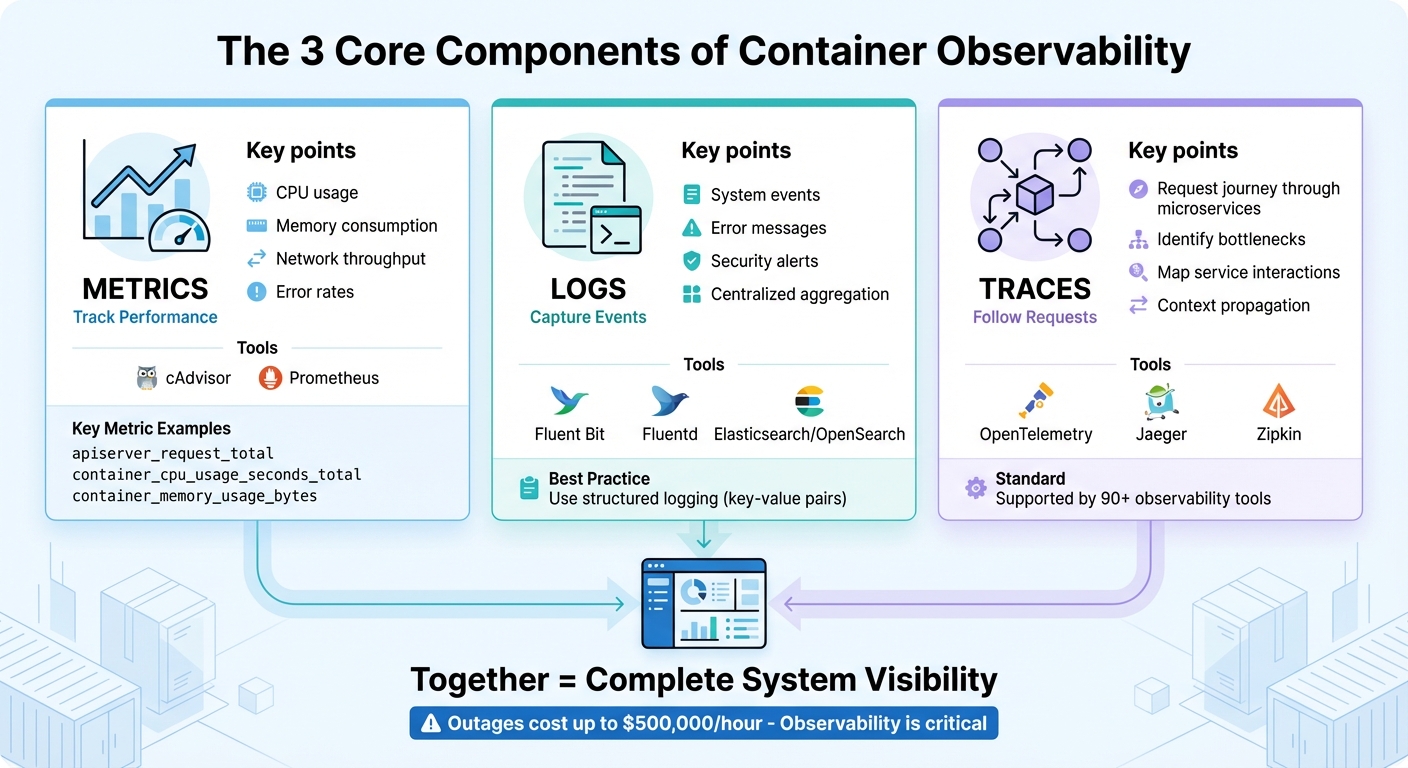
De 3 kerncomponenten van containerobservatie: statistieken, logboeken en traceringen.
De 3 kerncomponenten van observeerbaarheid
Het verzamelen van meetgegevens
Metrieken bieden een momentopname van de gezondheid en prestaties van containers, met gegevens over onder andere CPU-gebruik, geheugenverbruik, netwerkdoorvoer en foutpercentages. In Kubernetes-omgevingen stellen componenten zoals de kube-apiserver en kubelet al metrieken beschikbaar in Prometheus-formaat. /statistieken eindpunten, waardoor ze gemakkelijk te verzamelen zijn.
Voor containerspecifieke statistieken zoals CPU-, geheugen- en netwerkgebruik is cAdvisor een onmisbaar hulpmiddel. Het biedt gegevens via de /metrics/cadvisor Een eindpunt dat tools zoals Prometheus regelmatig kunnen uitlezen. Prometheus slaat deze tijdreeksgegevens op voor analyse en waarschuwingen. Om de prestaties te optimaliseren, kunt u opnameregels gebruiken om complexe query's vooraf te berekenen en zo de benodigde resources te minimaliseren.
Het is essentieel om labels te beperken tot kritieke dimensies – zoals namespace, podnaam en servicetype – om problemen met een hoge cardinaliteit te voorkomen die uw systeem kunnen overbelasten. Belangrijke meetwaarden om te monitoren zijn onder andere: apiserver_request_total voor de belasting van de API-server, container_cpu_gebruik_seconden_totaal voor CPU-gebruik, en container_memory_usage_bytes om geheugenlekken op te sporen voordat ze escaleren tot storingen.
Zodra je de meetgegevens onder controle hebt, is de volgende stap het centraliseren van je logbestanden voor een completer beeld.
Gecentraliseerde logging
Gecentraliseerde logbestanden leggen systeemgebeurtenissen, fouten en beveiligingswaarschuwingen op één plek vast. Omdat containerlogbestanden van nature tijdelijk zijn, is het essentieel om ze op een centrale locatie te verzamelen.
Om dit te bereiken, kunt u logagents zoals Fluent Bit (lichtgewicht) of Fluentd (met geavanceerde routeringsmogelijkheden) inzetten. Deze agents kunnen logs van logbestanden volgen. /var/log en ze doorsturen naar platforms zoals Elasticsearch, OpenSearch of CloudWatch voor indexering en zoekopdrachten.
Gebruik makend van gestructureerde logboekregistratie – waarbij logelementen worden opgemaakt als sleutel-waardeparen – maakt het veel gemakkelijker om logs te parseren, filteren en visualiseren in vergelijking met platte tekst. Schakel bovendien altijd de optie in. logrotatie voor /var/log Om te voorkomen dat de schijfruimte onverwacht vol raakt, een veelvoorkomend probleem dat nodes kan laten crashen. Goed logbeheer versnelt niet alleen de reactie op incidenten, maar helpt ook de gemiddelde hersteltijd (MTTR) te verlagen.
Om de drie pijlers van observeerbaarheid compleet te maken, integreer je gedistribueerde tracering om in kaart te brengen hoe verzoeken door je systeem stromen.
Gedistribueerde tracering
Traces stellen je in staat om het traject van een verzoek door je microservices te volgen. Terwijl metrics problemen zoals hoge responstijden aan het licht brengen en logs specifieke fouten tonen, lokaliseert tracing de exacte bottleneck in je gedistribueerde systeem. Elke "span" in een trace vertegenwoordigt een bewerking en samen vormen ze een gedetailleerde kaart van de interacties tussen services.
OpenTelemetrie is nu de standaard voor gedistribueerde tracing en wordt ondersteund door meer dan 90 observability-tools. Vanaf Kubernetes 1.35 kunnen spans rechtstreeks worden geëxporteerd met behulp van het OpenTelemetry Protocol (OTLP) via ingebouwde gRPC-exporteurs. Tools zoals Jaeger en Zipkin kunnen deze traces verwerken, waardoor u latentiepatronen kunt visualiseren en inefficiënties kunt identificeren, zoals trage databasequery's of slecht geoptimaliseerde API-aanroepen.
Een van de krachtigste aspecten van tracering is contextpropagatie – een methode die ervoor zorgt dat elke aanvraag, ongeacht de service, een unieke identificatiecode krijgt. Dit koppelt statistieken, logboeken en traceringen aan elkaar in een samenhangend systeem, waardoor het gemakkelijker wordt om snel de oorzaak van problemen te achterhalen. Door deze observatiecomponenten te verbinden, kunt u de MTTR (Mean Time to Resolution) aanzienlijk verkorten en de afhandeling van incidenten stroomlijnen.
AWS re:Invent 2023 – Best practices voor containerobservability (COP319)
Uw observatiekader standaardiseren
Nadat je de kerncomponenten van observability hebt ingesteld, is de volgende stap het standaardiseren van je werkwijzen. Dit zorgt ervoor dat je data consistent en gemakkelijk te interpreteren blijft in je gehele containeromgeving.
Gebruikmakend van OpenTelemetry-standaarden
OpenTelemetry (OTel) is uitgegroeid tot de standaard voor het observeren van containers en wordt ondersteund door meer dan 90 leveranciers. Het biedt een uniform, leveranciersneutraal framework voor het genereren, verzamelen en exporteren van traces, metrics en logs. Dit elimineert de noodzaak voor meerdere propriëtaire agents en zorgt ervoor dat u eigenaar blijft van uw gegevens.
""U bent eigenaar van de data die u genereert. Er is geen sprake van vendor lock-in." – OpenTelemetry-documentatie
De kracht van OpenTelemetry ligt in de semantische conventies, die zorgen voor uniformiteit in naamgevingsconventies in verschillende codebases en op verschillende platforms. Zo kunnen containermetrieken zoals container.uptime (in seconden), container.cpu.usage (als een fractie van de toewijsbare CPU's), en container.memory.working_set Ze volgen voorspelbare patronen. Deze meetwaarden kunnen naadloos worden geïntegreerd met backends zoals Prometheus, Jaeger of andere commerciële platforms.
Om OpenTelemetry optimaal te benutten, initialiseer je het aan het begin van je applicatie. Dit zorgt ervoor dat alle volgende bibliotheekaanroepen correct worden geïnstrumenteerd. Bovendien kun je met een gecentraliseerde OpenTelemetry Collector telemetriegegevens bundelen, comprimeren en transformeren voordat je ze naar je backend stuurt. Deze aanpak vermindert niet alleen de systeembelasting, maar biedt ook de flexibiliteit om van observatieplatform te wisselen zonder de instrumentatie van je applicatie aan te passen.
Consistente tagging en metadata
Het standaardiseren van metadata is essentieel om ruwe telemetriegegevens om te zetten in bruikbare inzichten. Het gebruik van consistente labels zoals traceID, pod_name, knooppuntnaam, En naamruimte Hiermee kunt u verschillende telemetrietypen aan elkaar koppelen. Als u bijvoorbeeld een piek in de latentie opmerkt, kunt u met deze labels het probleem herleiden naar een specifieke container en bepalen of deze de resourcelimieten overschrijdt.
Het overnemen van Prometheus-naamgevingsconventies, zoals operator_naam_entiteit_metrische_naam – kan de consistentie tussen verschillende bronnen verder verbeteren. Houd echter rekening met de cardinaliteit van labels. Vermijd dimensies met een hoge cardinaliteit, zoals gebruikers-ID's of e-mailadressen, omdat deze de opslagkosten kunnen verhogen en uw systeem kunnen overbelasten met een overdaad aan unieke tijdreeksen.
Door al vroeg de semantische conventies van OpenTelemetry te volgen, zorgt u ervoor dat uw gegevens duidelijk en doorzoekbaar blijven, waardoor verwarring tijdens het oplossen van problemen of incidentafhandeling wordt verminderd. Zodra uw telemetrie is gestandaardiseerd, bent u klaar om een betrouwbare hostinginfrastructuur te implementeren.
Gebruik makend van Serverion Hostingoplossingen

Met uw observatiekader op zijn plaats bieden de VPS- en dedicated servers van Serverion de betrouwbaarheid die nodig is om OpenTelemetry Collectors op grote schaal te hosten. Voor nodespecifieke telemetrie implementeert u Collectors met behulp van een "Daemonset"-patroon op Serverion VPS-instances. Als u gegevens over een heel cluster aggregeert, gebruikt u een "Deployment"-patroon op dedicated servers om de verwerking te centraliseren en duplicatie te voorkomen.
Om uw configuratie te beveiligen, implementeert u op rollen gebaseerd toegangsbeheer (RBAC) om de bevoegdheden van de Collector te beperken tot alleen datgene wat nodig is. Gebruik nauwkeurige machtigingen voor het mounten van volumes en beveilig gevoelige gegevens met robuust configuratiebeheer. Monitor bovendien de status van uw observatie-infrastructuur door de interne telemetrie van de Collector te volgen en waarschuwingen in te stellen voor CPU- en geheugengebruik. Dit helpt de stabiliteit te behouden, zelfs onder zware belasting.
Als een enkele hostinginstantie de limieten van de resources bereikt, kunt u horizontaal schalen door meerdere Collectors in een load-balanced configuratie te implementeren in de wereldwijde datacenters van Serverion. Doordat Serverion het zware werk voor u doet, kan uw observatieframework moeiteloos meegroeien met uw containerapplicaties.
Het opzetten van monitoring- en waarschuwingssystemen
Het opzetten van monitoring- en waarschuwingssystemen is essentieel om potentiële problemen vroegtijdig te signaleren, voordat ze escaleren. Een goed doordachte monitoringopstelling verbindt uw gestandaardiseerde raamwerk met bruikbare inzichten, waardoor uw team problemen efficiënt kan identificeren en oplossen.
Het definiëren van SLO's en SLI's
Service Level Indicators (SLI's) Dit zijn de meetwaarden die je bijhoudt, terwijl Service Level Objectives (SLO's) Dit zijn de doelen die je voor die meetwaarden stelt. Richt je op meetwaarden die direct van invloed zijn op de gebruikerservaring, zoals API-serverlatentie, de gezondheid van de knooppunten en de gereedheid van de pods.
Stel SLO's in met op ernst gebaseerde doelstellingen. Bijvoorbeeld:
- Trekker kritieke waarschuwingen binnen 5 minuten in geval van omstandigheden die tot aanzienlijke verstoringen van de dienstverlening kunnen leiden.
- Trekker waarschuwingsmeldingen Binnen 60 minuten voor minder dringende zaken.
""Gebruik waarschuwingen op kritiek niveau alleen voor situaties die kunnen leiden tot gegevensverlies of het uitvallen van de dienstverlening voor het cluster als geheel." – Best practices voor operatorobservatie
Om grootschalige omgevingen te beheren, kunt u Prometheus-opnameregels gebruiken om veelgebruikte expressies vooraf te berekenen. Dit is vooral handig bij het bijhouden van SLO's in honderden of duizenden containers. Elke waarschuwing die aan een SLO is gekoppeld, moet een runbook_url annotatie, die stapsgewijze oplossingsinstructies biedt en de downtime tijdens incidenten minimaliseert.
Actiegerichte waarschuwingen configureren
Bruikbare waarschuwingen richten zich op symptomen die daadwerkelijk van invloed zijn op uw systeem of gebruikers, in plaats van alleen ongebruikelijke meetwaarden te signaleren. Vermijd bijvoorbeeld het activeren van waarschuwingen voor kleine schommelingen in meetwaarden die de functionaliteit niet beïnvloeden. Geef in plaats daarvan prioriteit aan situaties zoals:
- Aanhoudend hoge latentie
- Herhaaldelijk herstarten van de pod
- Uitputting van hulpbronnen
Maak gebruik van PromQL's voorspellen_lineair Deze functie maakt het mogelijk om dynamische drempelwaarden te creëren, waardoor uw team potentiële problemen kan voorspellen en aanpakken voordat ze escaleren. Statische drempelwaarden schieten vaak tekort, terwijl voorspellende waarschuwingen uw team een voorsprong geven.
Bij het configureren van waarschuwingen kunt u een duur van 15 minuten instellen om tijdelijke problemen eruit te filteren. Vermeld belangrijke details zoals cluster-, namespace- en podinformatie, samen met dashboardlinks voor snelle context.
Monitoring van het gebruik van hulpbronnen
Om een soepele werking te garanderen, dient u het resourcegebruik op de verschillende systeemlagen te monitoren:
- Besturingsvlak: Volg componenten zoals de API-server en etcd.
- ClusterstatusLet op problemen met de node-status en de planning van pods.
- ContainerstatistiekenHoud de CPU, het geheugen en de netwerk-I/O in de gaten.
Bijvoorbeeld, monitor kube_pod_container_status_restarts_total om containers te detecteren die in een crashloop terechtkomen. Een veelgebruikte drempelwaarde is meer dan drie herstarts binnen 15 minuten. Houd ook de grootte van de etcd-database in de gaten (apiserver_storage_db_total_size_in_bytes), aangezien het overschrijden van de limieten het gehele besturingsvlak in gevaar kan brengen.
Andere belangrijke aandachtspunten zijn de nog niet voltooide pods en planningsfouten, die vaak wijzen op een tekort aan resources of verkeerd geconfigureerde verzoeken. Wanneer containers worden beëindigd vanwege... OOMKilled Stel tijdens evenementen waarschuwingen op informatieniveau in om overschrijdingen van resourcelimieten vroegtijdig te signaleren en zo wijdverspreide storingen te voorkomen.
Tot slot is het belangrijk om regelmatig de prestaties van uw waarschuwingen te evalueren. Analyseer statistieken zoals de frequentie van waarschuwingen, de oplostijden en het percentage valse positieven. Dit helpt u uw regels te verfijnen, zodat ze effectief blijven naarmate uw omgeving verandert.
sbb-itb-59e1987
Beveiliging toevoegen aan uw observatieframework
Bij het monitoren van gecontaineriseerde applicaties is beveiliging niet zomaar een optie, maar een absolute noodzaak. Door beveiliging direct in je observatie-framework te integreren, kun je dezelfde tools gebruiken die je inzet voor prestatiemonitoring om potentiële bedreigingen te identificeren. Maar dit werkt alleen als alles vanaf het begin correct is ingesteld.
Beeldscanning en kwetsbaarheidsbeheer
Het integreren van imagescanning in je CI/CD-pipeline is een proactieve stap om kwetsbaarheden vroeg in het ontwikkelingsproces op te sporen. Inline scanning zorgt ervoor dat gevoelige gegevens privé blijven door images lokaal te scannen en alleen metadata naar de scantool te sturen. Deze aanpak blokkeert ongeautoriseerde images voordat ze problemen kunnen veroorzaken.
""Beeldscanning is de eerste verdedigingslinie in uw Secure DevOps-workflow." – Sysdig
Breid deze bescherming uit door scans op registerniveau te implementeren om alle images, inclusief images van derden, te verifiëren vóór de implementatie. Gebruik Kubernetes admission controllers om images te blokkeren die niet zijn gescand of niet voldoen aan de compliance-normen. Omdat er constant nieuwe kwetsbaarheden (CVE's) opduiken, is het cruciaal om images in productie regelmatig opnieuw te scannen om bedreigingen vanaf dag één aan te pakken.
Focus op het verhelpen van kwetsbaarheden waarvoor actieve exploits in uw productieomgeving bestaan. Om consistentie te waarborgen, tagt u uw afbeeldingen met onveranderlijke identificatoren zoals SHA256-hashes in plaats van veranderlijke tags zoals :nieuwste.
Runtime-beveiligingsmonitoring
Runtime monitoring voegt een extra beveiligingslaag toe door het gedrag van containers in de gaten te houden. Het monitoren van kernel-systeemoproepen kan bijvoorbeeld helpen bij het detecteren van ongebruikelijke bestandstoegang of netwerkactiviteit. Het vaststellen van basiswaarden maakt het gemakkelijker om afwijkingen snel op te sporen.
Centraliseren standaarduitvoer en stderr Logbestanden van container-runtimes creëren een chronologisch overzicht van beveiligingsgebeurtenissen dat beschikbaar blijft, zelfs nadat een container is afgesloten. Om risico's te minimaliseren, configureert u containers met willekeurige UID's om privilege-escalatie te blokkeren. Pas daarnaast seccomp- of AppArmor-profielen toe, verwijder onnodige Linux-mogelijkheden en stel CPU- en geheugenlimieten in om aanvallen met uitputting van resources te voorkomen.
DDoS-bescherming en logboekregistratie met Serverion
Hoewel runtime-monitoring interne processen beveiligt, is bescherming tegen externe bedreigingen zoals DDoS-aanvallen net zo belangrijk. De hostinginfrastructuur van Serverion biedt ingebouwde DDoS-bescherming via de wereldwijd verspreide datacenters. Deze configuratie absorbeert volumetrische aanvallen voordat ze uw applicaties bereiken. Functies zoals rate limiting en geoblocking voegen een extra verdedigingslaag toe op applicatieniveau.
De logmogelijkheden van Serverion kunnen naadloos worden geïntegreerd met uw observability-framework, waardoor beveiligingsgebeurtenissen in uw gehele stack worden vastgelegd – van cloudconfiguraties tot individuele containers. Door verkeersbaselines vast te stellen, kunt u onderscheid maken tussen legitieme pieken in gebruik en vroege tekenen van door bots uitgevoerde aanvallen. Alleen al vorig jaar waren er wereldwijd bijna 9 miljoen DDoS-aanvallen gericht op kritieke services.
""De grootste uitdaging is het onderscheiden van legitieme gebruikers en kwaadwillende bots, vooral wanneer beide grote hoeveelheden inkomend verkeer genereren." – SecurityScorecard
Om uw logboekregistratie verder te beveiligen, volgt u het principe van minimale bevoegdheden. Gebruik op rollen gebaseerd toegangsbeheer (RBAC) om observatietools te beperken tot alleen de mappen die ze nodig hebben. Schakel voor serverachtige componenten tokenverificatie of basisverificatie in en beperk de IP-adressen waarop ze werken. Monitor bovendien de prestaties van uw observatietools – zoals CPU-, geheugen- en doorvoersnelheid – om ervoor te zorgen dat ze niet overbelast raken tijdens een aanval.
Omvang en kosten beheersen
Om systemen efficiënt te houden, is het beheren van schaal en kosten net zo belangrijk als het handhaven van robuuste observatie- en beveiligingspraktijken. Naarmate het gebruik van containers toeneemt, neemt ook de hoeveelheid observatiegegevens toe. Het bijhouden van een enkele metriek zoals node_filesystem_avail Verspreid over 10.000 nodes worden ongeveer 100.000 tijdreeksen gegenereerd – beheersbaar voor veel systemen. Maar introduceer een label met een hoge kardinaliteit, zoals gebruikers-ID's, en dat aantal kan oplopen tot 100 miljoen tijdreeksen, wat veel te veel is voor standaard Prometheus-configuraties. De uitdaging ligt in het beheersen van de gegevens. kardinaliteit waarbij cruciale inzichten behouden blijven.
Beheer van gegevens met een hoge kardinaliteit
Hoge cardinaliteit treedt op wanneer meetwaarden labels bevatten met een onbeperkt aantal waarden, zoals gebruikers-ID's, e-mailadressen of dynamische podnamen. Elke unieke combinatie van labels genereert een nieuwe tijdreeks, wat aanzienlijke resources verbruikt.
""Elke labelset is een extra tijdreeks met bijbehorende kosten voor RAM, CPU, schijf en netwerk. Meestal zijn de overheadkosten verwaarloosbaar, maar in scenario's met veel metrics en honderden labelsets verdeeld over honderden servers kunnen deze snel oplopen." – Prometheus-documentatie
Om dit aan te pakken, aggregatie wordt je beste bondgenoot. Opnameregels kunnen complexe query's vooraf berekenen, waardoor nieuwe, minder resource-intensieve tijdreeksen ontstaan. Bijvoorbeeld een regel zoals som zonder(instantie, naamruimte, pod) Verwijdert labels met een hoge kardinaliteit, terwijl betekenisvolle gegevens behouden blijven. Bovendien kunt u tijdens het importeren gebruikmaken van metric_relabel_configs om onnodige labels te laten vallen, zoals voorbeeld of peul – met name handig voor langetermijntrendanalyses. Voor gegevens met een hoog volume of gedistribueerde tracering, innamemonstering Dit is een andere effectieve strategie. Deze methode legt 100% aan kritieke foutsporen vast, maar reduceert het normale spoorvolume tot bijvoorbeeld 1%, waardoor statistische relevantie wordt gewaarborgd zonder uw systeem te overbelasten.
Houd de meeste meetwaarden op een kardinaliteit van 10 of lager. Beperk meetwaarden die dit overschrijden tot slechts een paar in uw gehele omgeving. Vermijd het gebruik van labels voor procedureel gegenereerde waarden en exporteer in plaats daarvan Unix-tijdstempels voor gebeurtenissen in plaats van "tijd sinds"-tellers om constante updates te minimaliseren. Deze werkwijzen helpen bij het behouden van efficiënte observeerbaarheid zonder uw systeem te overbelasten.
Data Retention Policies
Niet alle observatiegegevens hoeven op dezelfde manier te worden opgeslagen. gelaagde opslag Je kunt de kosten in evenwicht houden en tegelijkertijd de juiste gegevens toegankelijk houden. Hier is een veelgebruikte aanpak:
- Hot PathSla realtime data op voor waarschuwingen en live dashboards in systemen zoals Kafka of streamprocessors.
- Warme WegGebruik tijdreeksdatabases zoals Prometheus voor bijna realtime analyses en probleemoplossing.
- Koude PadArchiveer langetermijngegevens over naleving en audits in data lakes of opslagfaciliteiten zoals S3.
Standaard Istio-configuraties gebruiken bijvoorbeeld een bewaartermijn van 6 uur voor lokale Prometheus-instanties om de opslaglast van labels met een hoge kardinaliteit te verminderen. Data met een hoge resolutie kunnen worden bewaard voor onmiddellijke probleemoplossing, terwijl geaggregeerde data met een lage kardinaliteit worden opgeslagen voor historische analyses. Deze strategie verlaagt niet alleen de opslagkosten met maximaal 401 TP3T, maar verbetert ook de queryprestaties. Budgetten voor observability vertegenwoordigen vaak ongeveer 31 TP3T van de totale infrastructuurkosten, dus het optimaliseren van bewaarbeleid kan een directe impact hebben op de financiële efficiëntie.
Schalen met eBPF-tools
Voor nog betere optimalisatie kunt u overwegen om monitoring op kernelniveau te gebruiken. eBPF-gebaseerde tools Net als bodembedekkers verzamelen deze tools gegevens rechtstreeks uit de Linux-kernel en bieden ze gedetailleerd inzicht in netwerkverkeer, schijf-I/O en interprocescommunicatie – en dat alles met minimaal resourcegebruik. Het beste eraan? Ze werken transparant en vereisen geen wijzigingen in uw applicatiecode.
In tegenstelling tot traditionele instrumentatie, waarbij bibliotheken moeten worden geïntegreerd en er extra overhead kan ontstaan, werkt eBPF op kernelniveau, waardoor de overhead van systeemaanroepen laag blijft. Dit maakt het ideaal voor productieomgevingen waar elke CPU-cyclus telt. Om het resourceverbruik verder te verminderen, kunnen tools zoals de OpenTelemetry batchprocessor gegevens groeperen in brokken – bijvoorbeeld 500 items of elke 30 seconden – voordat ze worden verzonden. Deze aanpak minimaliseert het aantal netwerkaanroepen, waardoor de belasting van uw observatieframework wordt verlicht en de efficiëntie wordt gemaximaliseerd.
Conclusie
Samenvatting van beste praktijken
Het opzetten van een robuust framework voor het observeren van containers is essentieel voor het behoud van soepele applicatieprestaties. Dit framework is gebaseerd op drie kerncomponenten: meetwaarden, logboeken, En sporen – samenwerken om een compleet beeld te geven van de interne werking van uw cluster.
Het implementeren van standaarden zoals OpenTelemetry en het instellen van intelligente waarschuwingen helpt teams zich te concentreren op wat er echt toe doet. Kritieke waarschuwingen moeten binnen ongeveer 5 minuten worden geactiveerd en vereisen alleen onmiddellijke aandacht bij grote incidenten. Op het gebied van beveiliging moet uw observatiekader mislukte inlogpogingen, ongeautoriseerde wijzigingen en ongebruikelijke netwerkactiviteit registreren, naast traditionele prestatiegegevens. Om de kosten effectief te beheren, zijn strategieën zoals dataretentiebeleid, cardinaliteitscontrole en tools zoals eBPF essentieel. Aangezien storingen mogelijk tot wel ... euro's kunnen kosten. $500.000 per uur, Deze werkwijzen beschermen zowel uw bedrijfsvoering als uw financiën.
""Net als beveiliging mag observability geen bijzaak zijn bij uw ontwikkeling of beheer. De beste werkwijze is om observability al vroeg in uw planning te betrekken." – AWS Best Practices voor Observability
Deze beste werkwijzen komen natuurlijk het best tot hun recht op een stabiel en betrouwbaar hostingplatform.
Hoe Serverion Observability ondersteunt
Serverion verbetert observability-inspanningen door betrouwbare en veilige hostingoplossingen aan te bieden. Om optimaal gebruik te maken van deze best practices, hebben uw observability-tools een sterke infrastructuur nodig. De hostingdiensten van Serverion vormen de ruggengraat voor tools zoals Prometheus scrapers en Fluent Bit aggregators, en leveren tegelijkertijd de benodigde functionaliteit. DDoS-beveiliging en beveiligde login om topprestaties te behouden.
Met toegang tot cruciale gastheersignalen en dagboek Dankzij logbestanden wordt het debuggen van clusterproblemen sneller en efficiënter. De ingebouwde DDoS-bescherming en gedetailleerde logging zorgen voor een extra beveiligingslaag, waardoor realtime correlatie tussen netwerkaanvallen en applicatieprestaties mogelijk is. Of u nu gebruikmaakt van VPS, dedicated servers of AI GPU-infrastructuur, de wereldwijde datacenters van Serverion garanderen dat uw monitoringtools operationeel blijven – zelfs bij systeemstoringen. Hoogbeschikbare hosting vormt immers de basis voor optimale prestaties van observatietools.
Veelgestelde vragen
Wat zijn de belangrijkste voordelen van het gebruik van OpenTelemetry voor het monitoren van containers?
OpenTelemetry is een open-source framework dat het observeren van containers vereenvoudigt door de werkwijze te standaardiseren. sporen, meetwaarden, En logboeken worden verzameld. De leveranciersneutrale aanpak betekent dat u niet gebonden bent aan een specifieke provider, waardoor u de vrijheid heeft om zonder gedoe te kiezen tussen verschillende backend-systemen.
Met OpenTelemetry hoeft u uw applicaties slechts één keer te instrumenteren. Vervolgens kunt u de gegevens moeiteloos exporteren naar elk observability-platform. Deze consistentie vereenvoudigt monitoring, stroomlijnt het oplossen van problemen en zorgt ervoor dat uw observability-configuratie zich kan aanpassen aan toekomstige wijzigingen.
Wat zijn de beste manieren om statistieken met een hoge kardinaliteit te beheren voor betere systeemprestaties?
Het beheren van metrics met een hoge cardinaliteit is essentieel om uw framework voor containerobservatie snel en kosteneffectief te houden. Een hoge cardinaliteit ontstaat wanneer metrics labels bevatten met veel unieke waarden (zoals voorbeeld, peul, of naamruimteDit kan opslagsystemen overbelasten, de resourcebehoefte verhogen en de prestaties negatief beïnvloeden – met name in omgevingen zoals Kubernetes of Istio.
Hier volgen enkele praktische manieren om met statistieken met een hoge kardinaliteit om te gaan:
- Beperk het aantal etiketten tot de essentiële zaken.Gebruik alleen labels die essentieel zijn voor het oplossen van problemen. Vermijd labels met een hoge variantie, zoals container-ID's of aanvraag-ID's, omdat deze het aantal unieke meetwaarden snel kunnen laten oplopen.
- Verzamel vroegtijdig geaggregeerde statistiekenTools zoals Prometheus-opnameregels kunnen helpen door statistieken op een hoger niveau vooraf te berekenen. Dit vermindert de hoeveelheid ruwe tijdreeksgegevens die u moet opslaan.
- Vereenvoudig uw statistiekenVerwijder of herschrijf onnodige labels tijdens het importeren. U kunt ook efficiëntere metrische typen gebruiken, zoals tellers of histogrammen met een beperkt aantal buckets.
Door uw meetgegevens te stroomlijnen en te aggregeren, behoudt u een schaalbaar en efficiënt observatiekader. Dit is vooral belangrijk bij het uitvoeren van workloads op robuuste infrastructuren zoals die van Serverion.
Wat zijn de belangrijkste beveiligingsmaatregelen voor een framework voor het observeren van containers?
Om een framework voor containerobservatie veilig te houden, is het belangrijk om telemetriegegevens – zoals metrics, logs en traces – niet alleen te beschouwen als een hulpmiddel om bedreigingen op te sporen, maar ook als een waardevolle bron die bescherming behoeft. Door beveiligingsmaatregelen in uw gehele observatiepipeline te integreren, kunt u afwijkingen vroegtijdig identificeren en tegelijkertijd het systeem dat uw containers monitort, beschermen.
Hieronder volgen enkele belangrijke stappen om te overwegen:
- Gebruik geverifieerde en gescande containerafbeeldingen.Dit helpt om kwetsbaarheden op te sporen vóór de implementatie, waardoor het risico op het introduceren van beveiligingslekken wordt verkleind.
- Containers uitvoeren met beperkte rechten: Vermijd het verlenen van root-toegang en dwing alleen-lezen bestandssystemen af om potentiële schade door inbreuken te minimaliseren.
- Beveilig geheimen zoals API-sleutels en tokens.: Sla gevoelige informatie op in een speciaal daarvoor bestemd hulpmiddel voor geheimbeheer en injecteer deze veilig tijdens de uitvoering om openbaarmaking te voorkomen.
- Versleutel telemetriegegevensGebruik TLS voor gegevens tijdens de overdracht en veilige opslagmethoden voor gegevens in rust om de vertrouwelijkheid te waarborgen.
- Hanteer strikte toegangscontroles.Implementeer op rollen gebaseerde toegangscontrole (RBAC) om te beperken wie observatiegegevens kan bekijken en beheren.
Door deze werkwijzen te volgen, vooral in combinatie met betrouwbare infrastructuren zoals de hostingoplossingen van Serverion, kunt u een veilig en betrouwbaar raamwerk bouwen dat uw containeromgevingen beschermt.




