
Hoe u patchbeheer voor servers kunt automatiseren
Patchbeheer voor servers is een cruciale taak om ervoor te zorgen dat uw systemen veilig en operationeel blijven. Handmatig patchen kan uw servers wekenlang kwetsbaar maken, terwijl automatisering deze periode verkort tot slechts enkele dagen. Zo kunt u het proces stroomlijnen:
- Inventarisatie en kwetsbaarheidsanalyseGebruik tools zoals Puppet, Chef of Ansible om servers te ontdekken, te catalogiseren en te monitoren. Koppel deze inventaris aan kwetsbaarheidsscanners voor realtime prioritering van patches.
- BeleidsvormingOntwikkel een duidelijk patchbeheerbeleid waarin verantwoordelijkheden, patchcategorieën en tijdlijnen voor updates zijn vastgelegd (bijvoorbeeld: kritieke patches binnen 48 uur).
- AutomatiseringstoolsKies tools die geschikt zijn voor uw omgeving, zoals WSUS voor Windows, Ansible voor platformonafhankelijke omgevingen of AWS Patch Manager voor cloudomgevingen.
- Patches testenTest updates altijd eerst in geïsoleerde omgevingen voordat u ze implementeert om verstoringen te voorkomen.
- Geautomatiseerde implementatieGebruik gefaseerde uitrol, onderhoudsvensters en slimme herstartstrategieën om patches veilig te implementeren. Zorg altijd voor terugdraaiplannen.
- Continue bewaking: Houd de naleving van patches, faalpercentages en de tijd tot patchimplementatie bij. Genereer rapporten voor audits en prestatiebeoordelingen.
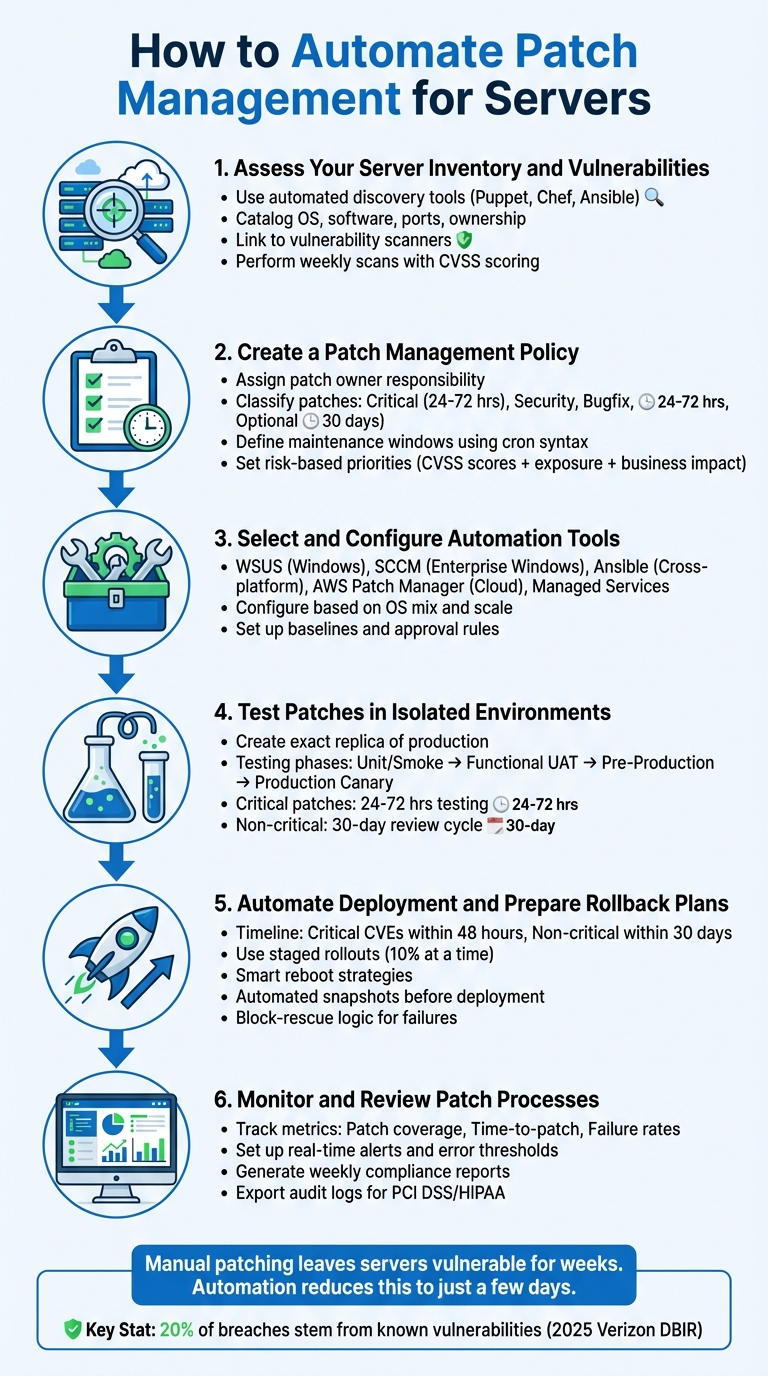
Automatiseringsproces voor serverpatchbeheer in 6 stappen
Stap 1: Beoordeel uw serverinventaris en kwetsbaarheden
Identificeer en catalogiseer uw servers
Begin met het identificeren van al uw servers met behulp van geautomatiseerde detectietools. Voor gedetailleerde, continue monitoring zijn agentgebaseerde tools zoals Puppet of Chef uitstekende keuzes. Als u de serverbelasting wilt minimaliseren, overweeg dan agentloze methoden zoals het op SSH gebaseerde Ansible.
Zodra een server is gevonden, catalogiseer je deze door het besturingssysteem, de geïnstalleerde software, de open poorten en de eigendomsgegevens vast te leggen. Gebruik dynamische inventarisatie-plug-ins en tags om servers te classificeren op basis van belangrijke factoren zoals besturingssysteem, omgeving en onderhoudsschema's. Deze organisatie maakt het eenvoudiger om gerichte playbooks te implementeren. Als je platforms gebruikt zoals Serverion Of het nu gaat om VPS- of dedicated servers, zorg ervoor dat u deze integreert in uw gecentraliseerde beheersysteem om te voorkomen dat u belangrijke gegevens over het hoofd ziet.
""Serverpatchbeheer begint met weten wat je hebt. Een betrouwbare inventarisatie van je assets – inclusief OS-versie, "Geïnstalleerde pakketten, open poorten en bedrijfseigenaar maken nauwkeurige kwetsbaarheidsanalyse mogelijk." – Jack Williams, WordPress Server beheer Specialist, Moss.sh
Vervolgens koppelt u uw database met assets aan kwetsbaarheidsscanners. Deze koppeling stelt u in staat om automatisch een prioriteitslijst voor herstelwerkzaamheden te genereren en te controleren op "statusafwijkingen", waarmee u servers kunt identificeren die niet langer aan de compliance-eisen voldoen. Met een uitgebreide inventarisatie kunt u direct overgaan tot het scannen op kwetsbaarheden en het prioriteren van patches.
Voer een kwetsbaarheidsscan uit.
Nadat je je servers in kaart hebt gebracht, is de volgende stap het scannen op kwetsbaarheden. Nauwkeurige inventarisgegevens maken dit proces soepeler en effectiever. Gebruik tools zoals AWS Systems Manager Patch Manager, Tenable Nessus of besturingssysteemspecifieke opties zoals... yum-plugin-security Voor Red Hat/CentOS. Deze tools identificeren ontbrekende patches en kennen ernstniveaus toe op basis van CVSS-scores.
Om prioriteit te geven aan het patchen, moet u zich richten op de impact op de bedrijfsvoering, de blootstelling en de exploiteerbaarheid van kwetsbaarheden. Updates met een hoge prioriteit of kritieke updates moeten binnen een bepaalde tijd worden toegepast. 48 uur van release. Voor problemen van gemiddelde of lage ernst geldt een tijdschema van maximaal 30 dagen is over het algemeen acceptabel. Een publiekelijk toegankelijke webserver met een CVSS 8.8-kwetsbaarheid voor het uitvoeren van code op afstand vereist bijvoorbeeld onmiddellijke actie, terwijl een interne back-upserver Bij een minder ernstig probleem kan het wachten.
Plan wekelijkse scans in en stel realtime meldingen in voor kritieke kwetsbaarheden. Begin met scanbewerkingen om rapporten te genereren zonder de productiesystemen te verstoren. Integreer vervolgens uw scanners met patchbeheertools om een dynamische, geautomatiseerde workflow te creëren die aansluit bij de risicotolerantie en nalevingsnormen van uw organisatie.
Patchbeheer met Ansible
Stap 2: Een patchbeheerbeleid maken
Zodra je kwetsbaarheden hebt geïdentificeerd, is het tijd om je aanpak te formaliseren met een goed gestructureerd patchbeheerbeleid.
Begin met het definiëren van uw patchbeheerbeleid. Volgens NIST SP 800-40 Rev. 4 omvat patchbeheer "het identificeren, prioriteren, verkrijgen, installeren en verifiëren van de installatie van patches, updates en upgrades binnen een organisatie". Zonder een duidelijk beleid bieden zelfs de beste automatiseringstools niet de richting of verantwoording die u nodig hebt.
Verantwoordelijkheid toewijzen: Wijs een patchverantwoordelijke aan om de updates binnen de verschillende teams te coördineren. Deze persoon zorgt ervoor dat patches tijdig worden toegepast en dat alle procedures worden gevolgd.
Patches classificeren: Deel patches in categorieën in, zoals kritiek, beveiliging, bugfixes of optioneel. Stel kortere deadlines in voor kritieke updates (bijvoorbeeld 24-72 uur) dan voor niet-kritieke updates, waarvoor een ruimere termijn geldt, zoals 30 dagen. Zorg voor een noodplan voor zero-day-kwetsbaarheden, zodat binnen 24 uur actie kan worden ondernomen en de normale goedkeuringsprocedures indien nodig kunnen worden omzeild.
Plan voor uitzonderingen: Neem terugdraaiprocedures en een formeel uitzonderingsproces op voor systemen die niet direct gepatcht kunnen worden, zoals verouderde systemen. Dit zorgt ervoor dat u de controle behoudt, zelfs wanneer direct patchen geen optie is.
""Beleid voor serverpatchbeheer is succesvol wanneer het duidelijk, pragmatisch en afgestemd is op de bedrijfsrisico's." – Jack Williams, WordPress- en serverbeheerspecialist, Moss.sh
Communiceer duidelijk: Stel communicatiekanalen in – e-mail, statuspagina's of chattools – om belanghebbenden te informeren over onderhoudsperiodes, mogelijke gevolgen en updates over de voltooiing. Koppel patchgoedkeuringen aan uw IT Service Management (ITSM)-systeem om een auditspoor te creëren en ervoor te zorgen dat elke wijziging wordt gedocumenteerd.
Definieer onderhoudsvensters
Plan onderhoudsvensters in om de verstoring van de bedrijfsvoering tijdens het toepassen van patches te minimaliseren. Gebruik cron-syntaxis (bijv., cron(0 2 ? * SAT#3 *)) voor een nauwkeurige en consistente planning. Elk tijdvak moet een duur (totale toegewezen tijd) en een afsnijden (het eindpunt voor het starten van nieuwe taken) om te voorkomen dat de werktijden worden overschreden.
Organiseer servers in groepen, zoals 'Patchgroep' en 'Onderhoudsvenster', om de timing van de implementatie te controleren. Alle servers in de App-Prod-Win De groep moet hetzelfde venster delen om consistentie te garanderen. Geef prioriteit aan internetservers voor de eerste updates, terwijl interne servers zoals back-ups later aan de beurt kunnen komen.
Gebruik een gefaseerde implementatiestrategie Om risico's te beperken, begin je met ontwikkelomgevingen, ga je vervolgens naar testomgevingen en ten slotte naar productie na succesvolle validatie. Beperkingen in het aantal patches, zoals het patchen van twee servers of 10% van je serverpark tegelijk, kunnen de impact van eventuele problemen verder beperken.
Stel prioriteiten op basis van risico's.
Niet alle patches vereisen dezelfde urgentie. Houd rekening met factoren zoals ernst van de kwetsbaarheid (CVSS-scores), blootstelling aan activa (internetgericht versus intern), en impact op het bedrijfsleven (productie versus ontwikkeling) om prioriteiten te stellen. Een publiek toegankelijke server met een CVSS 8.8-kwetsbaarheid en een actieve exploit moet bijvoorbeeld voorrang krijgen boven een interne sandbox-server met een minder ernstig probleem.
Automatiseer beleid voor kritieke en zeer ernstige kwetsbaarheden met behulp van CVE-gegevens. Overweeg in productieomgevingen het volgende: ""patch age" beleid – 7 tot 14 dagen wachten na het uitbrengen van een patch om de stabiliteit te garanderen voordat deze wordt geïmplementeerd. Deze aanpak biedt een evenwicht tussen de noodzaak tot snel handelen en het belang van het vermijden van ongeteste updates.
Houd een risicoregister bij voor systemen die niet gepatcht kunnen worden, documenteer de compenserende maatregelen en controleer deze tijdens elk onderhoudsvenster. Als u infrastructuur beheert op platforms zoals Serverion dedicated servers Of u nu kiest voor een VPS of een andere server, integreer deze systemen in uw gecentraliseerde beleidskader om een consistente prioritering in uw hele netwerk te garanderen.
Zodra uw beleid is vastgesteld, is de volgende stap het selecteren en configureren van automatiseringstools die deze prioriteiten effectief afdwingen.
Stap 3: Automatiseringstools selecteren en configureren
Zodra u een duidelijk beleid voor patchbeheer hebt opgesteld, is de volgende stap het kiezen van automatiseringstools die aansluiten bij uw specifieke behoeften. Bij uw keuze moet u rekening houden met factoren zoals de mix van besturingssystemen, de schaal van uw omgeving en het gewenste niveau van controle.
Evalueer de mogelijkheden van automatiseringstools
Hieronder een overzicht van enkele populaire automatiseringstools, hun sterke punten en hun beperkingen:
Windows Server Update Services (WSUS)
WSUS is standaard inbegrepen bij Windows Server en biedt een gecentraliseerde console voor het beheren van Microsoft-patches. Het is een prima keuze voor kleine tot middelgrote Windows-omgevingen, maar wordt onhandig bij grotere schaal en is beperkt tot Microsoft-producten.
System Center Configuration Manager (SCCM)
SCCM, nu bekend als Microsoft Endpoint Configuration Manager, biedt gedetailleerde controle over grote Windows-implementaties. Het vereist echter een aanzienlijke investering in zowel licentiekosten als beheerresources.
Ansible-automatiseringsplatform
Ansible gebruikt een "patching as code"-aanpak en vereist geen agents, omdat het gebruikmaakt van SSH voor Linux en WinRM voor Windows. Hoewel het krachtig is en goed integreert met cloudomgevingen, vereist het wel dat uw team bedreven is in het schrijven van YAML-playbooks.
AWS Systems Manager Patch Manager
Deze tool is ideaal voor cloud-native omgevingen en integreert naadloos met EC2-instances en hybride servers. U kunt patchbaselines definiëren met regels zoals het automatisch goedkeuren van beveiligingspatches na zeven dagen. De implementatie in hybride of on-premises omgevingen kan echter een uitdaging vormen.
Beheerde diensten
Aanbieders zoals Serverion bieden 24/7 monitoring en herstel, waardoor patches consistent worden toegepast, zelfs als uw interne middelen beperkt zijn. Volgens het Verizon Data Breach Investigations Report 2025 was 201 TP3T (Total Property, 3 Biljoen) van de datalekken het gevolg van bekende kwetsbaarheden, en 601 TP3T van de getroffen bedrijven waren zich bewust van hun niet-gepatchte systemen.
| Gereedschapstype | Primair besturingssysteem | Belangrijkste sterke punten | Beperkingen |
|---|---|---|---|
| WSUS | Windows | Gratis bij Windows Server; vermindert het bandbreedtegebruik. | Beperkt tot Microsoft-producten; uitdagend op grote schaal. |
| SCCM | Windows | Gedetailleerde controle; ideaal voor grootschalige implementaties. | Hoge kosten; vereist aanzienlijke administratieve inspanning. |
| Weerhaak | Platformoverschrijdend | Agentloos; integreert met de cloud | Vereist vaardigheden in YAML-scripting. |
| Beheerde diensten | Multi-OS | 24/7-bewaking; vermindert de interne werkdruk. | Hogere doorlopende kosten; minder directe controle |
| AWS Patch Manager | Multi-OS | Cloudintegratie; aanpasbare basisinstellingen | Complex voor hybride/on-premise omgevingen |
Configureer het door u geselecteerde gereedschap.
Zodra je een tool hebt gekozen, is een goede configuratie essentieel om ervoor te zorgen dat deze effectief werkt. Hieronder lees je hoe je aan de slag kunt met enkele van de populairste opties:
WSUS
Installeer WSUS op een Windows Server en configureer de updateclassificaties (bijv. Kritiek, Beveiliging, Definitie-updates). Gebruik groepsbeleidsobjecten (GPO's) om clientservers naar de URL van uw interne WSUS-server te leiden. Schakel clientgerichte targeting in om servers automatisch in groepen te organiseren op basis van hun Active Directory-organisatie-eenheid (OU).
""WSUS maakt gecentraliseerd beheer van updates mogelijk, waardoor alle servers en werkstations de benodigde patches ontvangen en het bandbreedtegebruik wordt verminderd." – Ashwani Paliwal, SecOps Solution
Weerhaak
Begin met het creëren van een gecentraliseerde inventaris met behulp van dynamische plug-ins die verbinding maken met uw infrastructuurproviders, zoals AWS, Azure of VMware. Gebruik de sleutelgroepen Instructie om servers automatisch te groeperen op besturingssysteem, omgevingslabels of functie. Maak taaksjablonen om playbooks te activeren tijdens onderhoudsvensters. Gebruik voor Linux modules zoals ansible.builtin.dnf of ansible.builtin.apt om updates af te handelen, zodat kritieke services indien nodig worden gepauzeerd en opnieuw opgestart. Voor Windows geldt het volgende: win_updates De module kan herstarts beheren en updates filteren op categorie.
""Door Red Hat Ansible Automation Platform te gebruiken voor geautomatiseerd patchbeheer van zowel RHEL als Windows in één workflow, kunt u zorgen voor nog meer consistentie en operationele efficiëntie." – Tricia McConnell, Red Hat
AWS Patch Manager
Gebruik patchbaselines om goedkeuringsregels te definiëren, zoals het zeven dagen uitstellen van de goedkeuring van kritieke updates om feedback vanuit de community te verzamelen. Deze aanpak is met name nuttig voor updates die worden uitgebracht op Microsofts Patch Tuesday. Zorg ervoor dat op alle instanties de SSM Agent (v2.0.834.0+) is geïnstalleerd.
Beheerde diensten
Als u gebruikmaakt van beheerde services zoals Serverion, werk dan samen met uw provider om workflows en escalatieprocedures te definiëren die aansluiten op uw patchbeheerstrategie. Plan bijvoorbeeld regelmatig onderhoudstaken in, zoals het uitvoeren van de WSUS Server Cleanup Wizard om verouderde updates te verwijderen of het controleren van Ansible-playbooks om configuratieafwijkingen te voorkomen.
sbb-itb-59e1987
Stap 4: Test patches in geïsoleerde omgevingen
Het testen van patches in een gecontroleerde omgeving is cruciaal om onverwachte storingen of onderbrekingen te voorkomen. Zelfs kleine updates kunnen leiden tot conflicten, prestatieproblemen of verbroken afhankelijkheden. Door te testen in geïsoleerde omgevingen kunt u deze problemen opsporen voordat ze uw productieomgeving beïnvloeden.
""Serverpatchbeheer moet grondige tests omvatten om regressies op te sporen en storingen te voorkomen." – Jack Williams, WordPress- en serverbeheerspecialist, Moss.sh
Deze fase zorgt ervoor dat uw automatiseringsscripts naar behoren werken en helpt bij het vaststellen van prestatiebenchmarks, met name voor updates met grote impact, zoals kernel- of databasepatches. Kritieke updates vereisen doorgaans 24 tot 72 uur testen, terwijl niet-kritieke updates een beoordelingscyclus van 30 dagen kunnen volgen. Een testomgeving die uw productieomgeving nauw nabootst, is essentieel voor nauwkeurige resultaten.
Een testomgeving opzetten
Uw testomgeving moet een exacte replica van uw productieomgeving. Dit omvat overeenkomende besturingssysteemversies, pakketconfiguraties, netwerkinstellingen en open poorten. Tools zoals Infrastructure-as-Code kunnen helpen om uw productieomgeving efficiënt te repliceren.
Voordat je patches aanbrengt, Maak momentopnamen van uw virtuele machines of maak een back-up van uw bestandssystemen. Deze back-ups bieden een vangnet voor het geval er iets misgaat. Als je tools zoals Puppet gebruikt, maak dan specifieke knooppuntgroepen aan voor testdoeleinden om onbedoelde overlapping met productiesystemen te voorkomen.
Om interferentie tijdens het testen te voorkomen, configureert u antivirusuitsluitingen voor patchbeheermappen. Voor Windows-servers kan dit paden omvatten zoals: C:\ProgramData\SolarWinds\ of vergelijkbare mappen die door uw automatiseringstools worden gebruikt. Plan bovendien periodes in waarin geautomatiseerde productietaken het testproces verstoren om te voorkomen dat deze processen worden onderbroken.
Valideer de compatibiliteit van de patch.
Zodra uw testomgeving gereed is, kunt u de compatibiliteit en prestaties van de patches valideren aan de hand van gestructureerde teststappen. Begin met eenheids- of rooktesten om de basisfunctionaliteit van de server te controleren, zoals het opstarten en het starten van de kernservices. Vervolg dit met Functionele gebruikersacceptatietests (UAT) Om ervoor te zorgen dat kritieke workflows – zoals databaseconnectiviteit, authenticatie en de gezondheid van webapplicaties – correct functioneren. Ga verder naar een pre-productieomgeving die uw productieomgeving volledig nabootst en, ten slotte, implementeert naar een productie kanarie – een kleine groep actieve servers die de risico's minimaliseert als er zich problemen voordoen.
| Testfase | Objectief | Belangrijkste activiteiten |
|---|---|---|
| Eenheids-/rooktesten | Basisstabiliteit | Controleer of de server correct opstart en of de kernservices correct starten. |
| Functionele UAT | Applicatie-integriteit | Test de gezondheid van de webapplicatie, de databaseverbinding en de authenticatiestromen. |
| Preproductie | Omgevingsspiegeling | Test patches op een volledige replica van de productieomgeving. |
| Productiekanarie | Beperkte uitrol | Implementeer op een klein deel van de productieservers. |
Automatiseer uw validatieprocessen zodat ze direct na het toepassen van patches worden uitgevoerd. Deze scripts moeten de status van service-eindpunten controleren, API-reacties nagaan en ervoor zorgen dat alle onderling verbonden services correct functioneren. Voer bij kernel- of database-updates I/O- en latency-benchmarks uit om eventuele verborgen prestatieproblemen op te sporen.
""Automatisering kan regressies introduceren als er geen voorzorgsmaatregelen worden genomen. Voorkom problemen door gefaseerde pipelines (canaries), geautomatiseerde rooktests, afhankelijkheidscontroles en terugdraaiprocedures te implementeren." – Jack Williams, Moss.sh
Leg uw resultaten vast in een patch-acceptatiematrix – een gecentraliseerde kennisbank die geteste OS-builds, applicatiestacks en eventuele incompatibiliteiten bijhoudt. Deze bron zal toekomstige implementaties begeleiden en teams helpen snel te bepalen welke patches veilig kunnen worden toegepast en welke verder getest moeten worden. Met een efficiënt testproces kunnen geavanceerde tools de implementatietijd van patches verkorten tot slechts 4 uur, terwijl de systeemstabiliteit behouden blijft.
Stap 5: Automatiseer de implementatie en bereid terugdraaiplannen voor.
Zodra de tests zijn afgerond, verschuift de focus naar het veilig en efficiënt uitrollen van patches, en naar de voorbereiding op mogelijke terugdraaiingen voor het geval er iets misgaat.
Het automatiseren van de implementatie is essentieel om fouten te minimaliseren en de systeemstabiliteit te waarborgen. Streef ernaar om kritieke CVE's binnen 48 uur en niet-kritieke CVE's binnen 30 dagen aan te pakken. Deze termijnen zijn haalbaar met goed ontworpen geautomatiseerde scripts die beveiligingsmaatregelen bevatten. Zonder dergelijke maatregelen kan één enkele mislukte patch uw gehele infrastructuur ontregelen.
""Een proactief patchprogramma zorgt voor een balans tussen snelheid en stabiliteit, waardoor de periode tussen het ontdekken en verhelpen van kwetsbaarheden wordt verkort en downtime als gevolg van ongeteste updates wordt voorkomen." – Moss.sh
Automatiseer implementatiescripts
Begin met gefaseerde uitrol, Het uitrollen van patches gebeurt in fasen in plaats van allemaal tegelijk. Begin met een kleine testgroep (canary group), monitor deze 24 uur en ga vervolgens verder met de rest van het systeem. Deze aanpak minimaliseert de impact van eventuele problemen en houdt de gevolgen beheersbaar. Stel limieten in voor het aantal servers dat tegelijkertijd wordt bijgewerkt (bijvoorbeeld 10% tegelijk) en definieer foutdrempels om het proces automatisch te stoppen als er te veel fouten optreden.
Plan updates tijdens onderhoudsvensters Wanneer het verkeer laag is, gebruik dan tools zoals cron-expressies of op frequentie gebaseerde planning om de verstoring tot een minimum te beperken. Voor clusters met hoge beschikbaarheid kunt u servers één voor één patchen om de uptime te garanderen. Vermijd bovendien automatisch patchen tijdens kritieke bedrijfsperioden, zoals de eindejaarsverwerking, door zogenaamde 'blackout windows' in te stellen.
Integreer lifecycle hooks om kritieke services netjes te stoppen vóór het patchen en implementeer slimme herstartlogica. Dit zorgt ervoor dat systemen alleen opnieuw opstarten wanneer dat nodig is, waardoor onnodige downtime wordt voorkomen. Tools zoals Ansible kunnen bijvoorbeeld het patchen beheren met modules zoals... ansible.builtin.dnf voor Linux of win-updates voor Windows.
| Herstartstrategie | Beschrijving | Beste gebruiksscenario |
|---|---|---|
| Slim | Het systeem start alleen opnieuw op als het besturingssysteem aangeeft dat een herstart nodig is. | Vermindert stilstandtijd en verbetert de efficiëntie. |
| Opgelost | Het apparaat start pas opnieuw op na een succesvolle patch-toepassing. | Standaard voor de meeste geautomatiseerde workflows |
| Altijd | Dwingt een herstart af, ongeacht de patchstatus. | Ideaal voor kernelupdates die een schone specificatie vereisen. |
| Nooit | Voorkomt herstarten; vereist handmatige tussenkomst. | Geschikt voor oudere systemen die handmatig toezicht vereisen. |
Zodra de implementatiebeveiligingen zijn getroffen, kunt u zich richten op het opstellen van betrouwbare terugdraaiplannen om eventuele problemen snel aan te pakken.
Implementeer terugdraaiprocedures
Geautomatiseerde momentopnamen zouden onderdeel moeten zijn van elk implementatiescript. Maak voor virtuele machines snapshots op VM-niveau. Gebruik op Linux-systemen Logical Volume Manager (LVM) snapshots voor snel lokaal herstel. Met deze back-ups kunt u systemen terugzetten naar een stabiele staat als een patch onverwachte problemen veroorzaakt.
Voeg logica voor het herstellen van patches toe aan uw scripts, zodat herstelacties automatisch worden geactiveerd wanneer een patch mislukt. U kunt bijvoorbeeld sjablonen ontwerpen voor taken zoals "Patchback-up herstellen" die wijzigingen terugdraaien en eerdere configuraties opnieuw laden wanneer validatiecontroles mislukken.
""Neem terugdraaiplannen op: maak snapshots van virtuele machines, maak back-ups van het bestandssysteem of gebruik blauw/groen- en canary-implementatiepatronen om de impact te beperken." – Moss.sh
Na het implementeren van de patches, voer je het volgende commando uit: geautomatiseerde validatiecontroles Om ervoor te zorgen dat alles correct functioneert, moeten deze controles de status van de service verifiëren, API-reacties testen en de databaseverbinding bevestigen. Als er problemen worden gedetecteerd, moeten uw scripts automatisch het terugdraaiproces starten. In omgevingen met onveranderlijke infrastructuur betekent terugdraaien het beëindigen van problematische instanties en het opnieuw implementeren van de vorige Amazon Machine Image (AMI) of containerversie. Zorg ervoor dat er vooraf goedgekeurde noodprocedures voor wijzigingen aanwezig zijn, zodat u snel kunt handelen bij zero-day-kwetsbaarheden.
Stap 6: Patchprocessen bewaken en evalueren
Het toepassen van patches is slechts het begin. Continue monitoring zorgt ervoor dat uw automatisering soepel verloopt en helpt u problemen op te sporen voordat ze uit de hand lopen. Houd belangrijke statistieken in de gaten, zoals patch dekking (hoeveel van uw systeem up-to-date is), tijd om te patchen (de snelheid waarmee kritieke kwetsbaarheden worden aangepakt), en patch-faalpercentages. Deze meetwaarden helpen u te beoordelen of uw automatisering de beoogde beveiligingsdoelen bereikt of juist risico's introduceert, zoals configuratieafwijkingen. Consistent toezicht zorgt ervoor dat geautomatiseerde implementaties leiden tot systeemstabiliteit op de lange termijn.
Realtime monitoring en waarschuwingen instellen
Gebruik CLI- of API-opdrachten om de patchstatus continu te volgen en gezondheidscontroles uit te voeren wanneer nodig. Bijvoorbeeld opdrachten zoals beschrijf-patch-groep-status Kan realtime gegevens over beheerde knooppunten leveren, zoals of patches zijn geïnstalleerd, ontbreken of zijn mislukt. Toon deze informatie op dashboards voor een snel overzicht van uw gehele systeem.
Stel foutdrempels in die implementaties pauzeren en uw team direct via e-mail of chat op de hoogte stellen wanneer het aantal patchfouten de acceptabele limieten overschrijdt. Om waarschuwingen te centraliseren, integreert u uw patchbeheertools met platforms zoals AWS Security Hub of CloudWatch. Definieer bovendien periodes waarin updates niet worden verzonden – bijvoorbeeld tijdens de eindejaarsverwerking of grote lanceringen – om onnodige waarschuwingen te voorkomen en risico's tijdens kritieke momenten te minimaliseren.
Rapporten genereren en analyseren
Realtime waarschuwingen zijn essentieel, maar geplande rapporten bieden een breder overzicht van de naleving en prestaties. Exporteer regelmatig geautomatiseerde rapporten over patchnaleving in CSV-formaat naar opslagsystemen zoals Amazon S3. Wekelijkse rapporten zijn nuttig voor routinecontroles, terwijl frequentere rapportage nodig kan zijn tijdens risicovolle perioden. Neem statistieken op zoals patchdekking, tijd tot patch voor kritieke kwetsbaarheden, faalpercentages en systemen die opnieuw opgestart moeten worden.
""Serverpatchbeheerprogramma's vereisen meetbare indicatoren om de effectiviteit aan te tonen." – Jack Williams, Specialist, Moss.sh
Houd zowel absolute aantallen als percentages bij naarmate uw infrastructuur groeit. Het patchen van 1200 servers klinkt bijvoorbeeld indrukwekkend, maar als dat slechts 60% van uw vloot betreft, is er nog steeds een aanzienlijk tekort. Bereken de effectiviteit van de updates (geïnstalleerde versus vereiste updates) om de naleving per systeem te meten.
Gebruik deze rapporten om de onderliggende oorzaken van mislukte implementaties te achterhalen. Als bepaalde pakketten herhaaldelijk falen op specifieke besturingssysteemversies, verfijn dan uw tests en compatibiliteitscontroles. Analyseer incidenten met betrekking tot wijzigingen, terugdraaipercentages en de tijd die nodig is om van fouten te herstellen om inefficiënties op te sporen. Zorg er voor compliance-frameworks zoals PCI DSS of HIPAA voor dat u bewijs van patchimplementaties, testresultaten en goedgekeurde uitzonderingen kunt exporteren naar fraudebestendige logboeken voor audits.
Conclusie
Het automatiseren van patchbeheer is een gamechanger voor serverbeveiliging. Door de zes stappen te volgen die in deze handleiding worden beschreven – Het inventariseren van uw gegevens, het opstellen van een beleid, het configureren van automatiseringstools, het testen in testomgevingen, het implementeren met terugdraaiplannen en het continu monitoren. – u kunt kwetsbaarheden snel en effectief aanpakken. Deze aanpak beschermt niet alleen kritieke gegevens tegen exploits en zero-day-aanvallen, maar helpt ook de uptime en systeemstabiliteit te behouden.
Maar de voordelen gaan verder dan alleen beveiliging. Automatisering vermindert repetitieve taken voor IT-teams, waardoor ze zich kunnen concentreren op strategische projecten. Het zorgt er ook voor dat... consistentie in verschillende omgevingen, Of u nu on-premise, cloud- of hybride infrastructuren beheert, u profiteert van geautomatiseerd patchbeheer, terwijl u tegelijkertijd het risico op menselijke fouten aanzienlijk verlaagt. Nu de wereldwijde uitgaven aan informatiebeveiliging naar verwachting in 2025 1 TP4 T212 miljard zullen bereiken (een stijging van 15,11 TP3 Tb ten opzichte van 2024), positioneren organisaties die geautomatiseerd patchbeheer omarmen zich voorop.
""Serverpatchbeheer is geen eenmalig project, maar een operationele capaciteit die beleid, automatisering, testen, monitoring en menselijke processen combineert." – Jack Williams, WordPress- en serverbeheerspecialist, Moss.sh
Voor bedrijven zonder eigen beveiligingsteams kunnen door experts beheerde services automatisering nog eenvoudiger maken. Neem bijvoorbeeld Serverion. Hun beheerde hostingdiensten Stroomlijn elk aspect van het patchproces – van het identificeren van kwetsbaarheden tot het testen en de implementatie – en bied tegelijkertijd continue monitoring, routinematige back-ups en DDoS-bescherming. Met 37 datacenters wereldwijd garanderen ze een snelle patchlevering, ongeacht de locatie van uw servers.
Waar het op neerkomt? Begin met een duidelijk patchbeheerbeleid, test grondig en monitor consistent. Of u het nu intern afhandelt of samenwerkt met een provider zoals Serverion, het doel is hetzelfde: kwetsbaarheden in een vroeg stadium stoppen en ervoor zorgen dat uw systemen soepel blijven draaien.
Veelgestelde vragen
Wat zijn de voordelen van het automatiseren van serverpatchbeheer?
Het automatiseren van patchbeheer voor servers biedt tal van voordelen die de IT-activiteiten veilig en soepel laten verlopen. Dankzij automatisering worden kwetsbaarheden snel aangepakt, waardoor het risico op cyberaanvallen afneemt en bedrijven kunnen voldoen aan wettelijke vereisten zoals PCI-DSS en HIPAA. Het zorgt er ook voor dat updates plaatsvinden tijdens geplande onderhoudsvensters, waardoor downtime wordt geminimaliseerd en kostbare verstoringen worden voorkomen.
Nog een voordeel? Het elimineert het risico op menselijke fouten en garandeert dat updates consistent en tijdig op alle servers worden toegepast. IT-teams kunnen waardevolle tijd en energie terugwinnen en zich richten op belangrijkere taken in plaats van handmatig patches te installeren. Bovendien schaalt automatisering moeiteloos, of u nu een paar servers beheert of een uitgebreide infrastructuur met on-premises systemen of in de cloud. Deze voordelen sluiten perfect aan op de serverbeheeroplossingen van Serverion, waarmee Amerikaanse bedrijven hun IT-omgevingen eenvoudig kunnen beveiligen en optimaliseren.
Welke stappen kan ik ondernemen om ervoor te zorgen dat mijn geautomatiseerde patchbeheerproces veilig en betrouwbaar is?
Om een veilig en betrouwbaar geautomatiseerd patchbeheerproces op te zetten, begin je met het vaststellen van een duidelijk patchbeleid. Dit beleid moet schema's bevatten voor zowel kritieke als routinematige updates. Test patches altijd in een gecontroleerde omgeving voordat je ze uitrolt naar productiesystemen om onverwachte verstoringen te voorkomen.
Kies betrouwbare automatiseringstools die het volgende bieden: rolgebaseerde toegangscontrole en gebruik versleutelde communicatie Om het proces te beschermen tegen potentiële bedreigingen, plaatst u uw automatiseringsservers dicht bij de systemen die ze beheren. Dit vermindert de latentie en beperkt de beveiligingsrisico's.
Controleer na het implementeren van patches of ze succesvol zijn toegepast. Houd gedetailleerde auditlogboeken bij om te voldoen aan compliance-eisen en om problemen op te lossen. Maak er een gewoonte van om uw automatiseringstools regelmatig bij te werken en blijf alert op nieuwe kwetsbaarheden om ervoor te zorgen dat uw systemen veilig en up-to-date blijven. Deze werkwijzen helpen u een soepele en veilige workflow voor patchbeheer te behouden.
Welke factoren moet ik in overweging nemen bij het kiezen van een tool voor het automatiseren van patchbeheer voor servers?
Bij het kiezen van een tool voor het automatiseren van patchbeheer voor servers is het belangrijk om op een aantal cruciale aspecten te letten. Zorg er allereerst voor dat de tool compatibel is met uw besturingssystemen – of u nu Windows Server, Linux-distributies of beide gebruikt – en met alle software van derden die essentieel is voor uw bedrijfsvoering. Functies zoals aanpasbare beleidsregels, flexibele planning en integratie met monitoring- en notificatiesystemen kunnen het hele proces aanzienlijk soepeler en efficiënter maken.
Als u een groot aantal servers beheert of servers die verspreid zijn over verschillende locaties, wordt schaalbaarheid een topprioriteit. Daarnaast zijn robuuste rapportagemogelijkheden en compliance-tracking essentieel, vooral als u moet voldoen aan beveiligingsnormen zoals PCI DSS of HIPAA. Een tool met krachtige rapportagemogelijkheden kan u helpen om aan deze eisen te voldoen.
Tot slot kan een gebruiksvriendelijke interface of beheersconsole een enorm verschil maken. Het vereenvoudigt zowel de initiële installatie als het doorlopende onderhoud van uw patchbeheerproces. Door met deze factoren rekening te houden, bent u beter in staat een oplossing te kiezen die ervoor zorgt dat uw servers veilig en goed onderhouden blijven.




