
Casestudy: Multiregionale vraagsturing met taakverdeling
Stilstand kan bedrijven duizenden dollars per uur kosten. Deze casestudy laat zien hoe een e-commercebedrijf dergelijke verliezen heeft voorkomen door een multiregionale rampenherstelstrategie (DR-strategie) te implementeren. Nadat een storing in één regio in oktober 2025 meer dan $40.000 aan omzetverlies had veroorzaakt, implementeerde het bedrijf een dual-regionale configuratie met behulp van Serverion‘infrastructuur van. De oplossing omvatte:
- Hersteltijddoelstelling (RTO): 2-5 minuten
- Herstelpuntdoelstelling (RPO): Minder dan 30 seconden
- Geografische DNS-routering en load balancing voor automatische failover
- Kosteneffectieve architectuur gebruikmakend van een warm standby-model
De uitdaging: Infrastructuurrisico's in één regio
Kwetsbaarheden met een enkelvoudig storingspunt
Vertrouwen op een één oostelijk datacentrum voor alle kritische componenten – zoals dedicated servers, De afhankelijkheid van één enkele regio voor de systemen, databases en opslag, creëerde een groot zwak punt voor het bedrijf. Deze opzet maakte hen kwetsbaar voor regionale verstoringen die alles tot stilstand konden brengen. Een stroomstoring, netwerkuitval of natuurramp kon het hele systeem platleggen, en er was geen back-uplocatie om de dienstverlening te garanderen. Deze kwetsbare architectuur leidde uiteindelijk tot een kostbare storing, wat de gevaren van afhankelijkheid van één enkele regio benadrukte.
Impact van downtime op bedrijfsactiviteiten
In oktober 2025 legde een storing in US-EAST-1 hun e-commerceplatform bijna een hele dag plat. De financiële klap was enorm. Met een omzet van $10.000 per uur, leidde zelfs een storing van vier uur al tot een verlies van $40.000. De langere downtime verergerde dit verlies, waardoor de financiële en operationele impact nog groter werd. Naast het directe omzetverlies raakten ook cruciale interne processen lamgelegd.
""Elke minuut downtime vertaalt zich in verloren inkomsten... Een enkele langdurige storing kan jarenlang opgebouwd vertrouwen tenietdoen." – Rahul Vala, technologieanalist
Dit incident legde een schrijnend probleem met hun herstelstrategie bloot. Hun hersteltijd was gericht op herstel binnen enkele minuten, maar de storing duurde veel langer, wat tot frustratie bij klanten leidde. Foutpagina's en verlaten winkelwagens gaven een duidelijk beeld van de schade. Het bedrijf realiseerde zich al snel dat zonder realtime replicatie naar een secundaire regio, Ze zetten elke dag zowel hun inkomsten als hun reputatie op het spel.
sbb-itb-59e1987
AWS Route 53 Failover | Rampenherstel in meerdere regio's met HTTPS
De oplossing: Multi-regio DR met Serverion Load Balancing

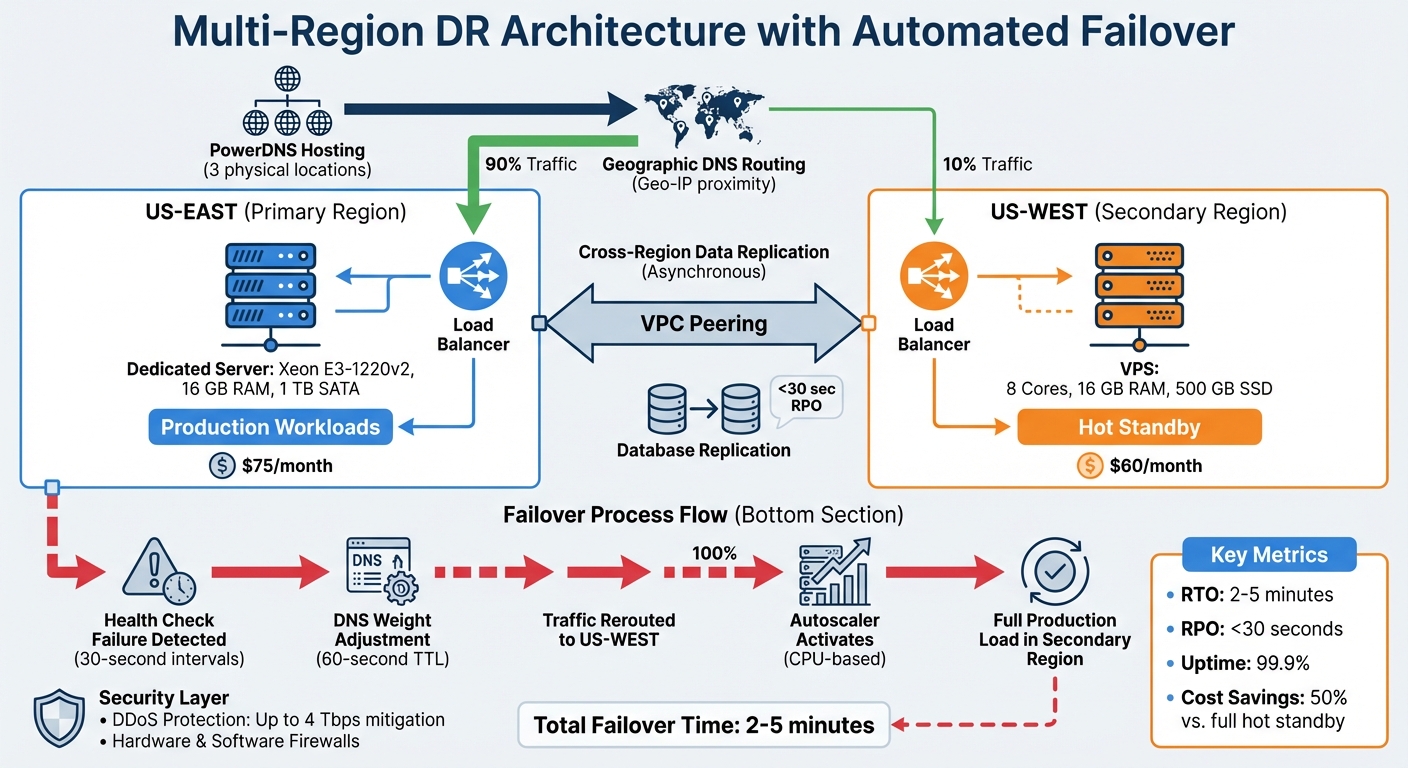
Architectuur voor noodherstel in meerdere regio's en failoverproces
De multi-regio-architectuur van Serverion
Het bedrijf heeft zijn infrastructuur vernieuwd door gebruik te maken van Het wereldwijde netwerk van Serverion omvat 37 datacenters., Het opzetten van een primaire locatie in US-EAST en een secundaire locatie voor noodherstel in US-WEST. Deze actieve/passieve configuratie zorgt voor een actieve back-up in US-WEST, waardoor vertragingen bij de activering van resources tijdens noodsituaties worden voorkomen.
Het systeem maakt gebruik van data replicatie tussen verschillende regio's In de asynchrone commit-modus worden de prestaties behouden. Binnen de primaire regio werken twee instanties in de synchrone commit-modus, verspreid over verschillende zones, waardoor het risico op gegevensverlies bij een storing op zoneniveau wordt verkleind. Geautomatiseerde back-ups dragen bovendien bij aan een lage Recovery Point Objective (RPO). Geografische DNS-routering – mogelijk gemaakt door Serverion's PowerDNS-hosting op drie wereldwijde locaties – stuurt verkeer naar de dichtstbijzijnde load balancer op basis van geografische IP-locatie. Deze aanpak verhelpt de kwetsbaarheid van configuraties met één regio en zorgt voor een betrouwbaardere beschikbaarheid van de service.
Taakverdeling voor hoge beschikbaarheid
Als aanvulling op de configuratie met meerdere regio's speelt geïntegreerde load balancing een cruciale rol in het effectief beheren van verkeer. Geografische load balancing vermindert de latentie en zorgt voor automatische failover. Drie onafhankelijke health check probes bewaken continu elke load balancer. In geval van een storing passen DNS-routeringsbeleidsregels dynamisch de recordgewichten aan, waardoor verkeer van de primaire regio naar de secundaire regio wordt verplaatst.
De timing van de failover is zorgvuldig berekend: Duur van de storing = DNS TTL + (Interval voor gezondheidscontrole × Drempelwaarde voor ongezonde status). Met een DNS Time-to-Live van 60 seconden en health check-intervallen van 30 seconden blijft de downtime onder de twee minuten. Deze precieze configuratie voldoet aan de bedrijfsdoelstelling van minimale serviceonderbrekingen. Regionale load balancers werken onafhankelijk van elkaar, waardoor een storing in één regio niet het hele netwerk verstoort.
Serverion hostingoplossingen gebruikt
Om deze robuuste architectuur te realiseren, maakte het bedrijf gebruik van verschillende Serverion-diensten. De oplossing combineerde dedicated servers in US-EAST met SSD-gebaseerde VPS-instances in US-WEST, waardoor een veerkrachtige hot standby-configuratie ontstond.
PowerDNS-hosting Serverion maakte de geografische routering mogelijk die nodig is voor automatische failover. Ultieme DDoS-bescherming, De systemen, die aanvallen tot 4 Tbps aankunnen, beschermden beide regio's tegen kwaadaardige verkeerspieken die valse failover-gebeurtenissen konden veroorzaken. 24/7-monitoring zorgde voor realtime detectie van storingen en geautomatiseerde waarschuwingen, terwijl consistente beveiligingsprotocollen werden gehandhaafd met hardware- en softwarefirewalls in beide regio's. Samen zorgden deze services voor de vereiste uptime van 99,91 TP3T om te voldoen aan de ambitieuze Recovery Time Objective van het bedrijf.
| Dienst | Configuratie | Maandelijkse kosten | Rol |
|---|---|---|---|
| Toegewijde server (primair) | Xeon E3-1220v2, 16 GB RAM, 1 TB SATA | $75 | Productiewerkzaamheden in de regio US-EAST |
| VPS (Secundair) | 8 kernen, 16 GB RAM, 500 GB SSD | $60 | Hot standby in US-WEST |
| PowerDNS Hosting | 3 fysieke locaties | Inclusief | Geografische verkeersroutering |
| DDoS Bescherming | Tot 4 Tbps mitigatie | Inclusief | Preventie van aanvallen in alle regio's |
Implementatie: Implementatie- en failoverproces
Infrastructuurimplementatie in meerdere regio's
Het implementatieproces begon met het opzetten van aparte VPC-netwerken voor de regio's US-EAST en US-WEST. Deze netwerken werden met elkaar verbonden via VPC-peering, waardoor privé en veilige databasereplicatie mogelijk werd zonder dat er verkeer naar het openbare internet werd doorgestuurd. Om de consistentie te waarborgen, gebruikte het team Terravorm Om instantiesjablonen en beheerde instantiegroepen in beide regio's te creëren. Deze automatisering zorgde ervoor dat beveiligingsbeleid, firewallregels en SSL-certificaten naadloos tussen de locaties werden gerepliceerd.
Om potentiële problemen snel te detecteren, werden gezondheidscontroles vanuit meerdere bronnen geïmplementeerd, wat zorgt voor robuuste detectie van afwijkingen in de gehele infrastructuur. Ook werd replicatie van de database tussen regio's opgezet, waardoor de latentie laag bleef en de Recovery Point Objective (RPO) onder de 30 seconden bleef. Deze stappen creëerden een betrouwbare basis voor failover-operaties.
Failover- en failbackprocedures
Na de implementatie zijn failover-mechanismen ontworpen om een ononderbroken dienstverlening te garanderen. Als gezondheidscontroles een regionale storing detecteren, wordt het verkeer automatisch omgeleid. DNS-failoverbeleid. De autoscaler van de back-upregio is geconfigureerd om direct te reageren en resources op te schalen om de productiebelasting aan te kunnen. Door autoscaling te baseren op CPU-gebruik In plaats van verbindingssnelheden voorkomt het systeem dat er tijdens verkeersverschuivingen voortijdig wordt afgeschaald.
Om de secundaire regio te allen tijde operationeel te houden, wordt er continu 10% aan verkeer naartoe geleid – een methode die bekendstaat als Het verkeer kruipt maar door. Dit zorgt ervoor dat de US-WEST-infrastructuur actief en gereed blijft. Wanneer de primaire regio hersteld is, vindt de failback automatisch plaats zodra de statuscontroles de stabiliteit bevestigen. Tijdens de overgang kunnen beide regio's het verkeer gelijktijdig verwerken, waardoor er geen downtime is.
Testen en validatie
Elk kwartaal worden er oefeningen voor noodherstel uitgevoerd om storingen in de primaire regio te simuleren. Deze oefeningen kunnen inhouden dat instanties naar nul worden teruggebracht of dat firewall-tags tijdelijk worden verwijderd. Het doel is om te controleren of het verkeer binnen twee minuten wordt omgeleid, terwijl de secundaire regio naar behoefte opschaalt. Geautomatiseerde controles valideren de servicestatus, de connectiviteit van kritieke poorten en de gegevensintegriteit voordat de failover als succesvol wordt verklaard. Regelmatige tests, beheerd via Terraform, tonen consistent aan dat de architectuur voldoet aan de strenge hersteldoelstellingen van het bedrijf in al zijn Amerikaanse datacenters.
Resultaten en belangrijkste conclusies
Behaalde veerkrachtindicatoren
De opzet met meerdere regio's leverde indrukwekkende veerkrachtcijfers op en behaalde een RTO (Recovery Time Objective) van 2-5 minuten en een RPO (Recovery Point Objective) onder de 30 seconden. Gezondheidscontroles bevestigden de ononderbroken beschikbaarheid van het datapad, terwijl failover via het netwerk de vertragingen als gevolg van DNS-propagatie elimineerde.
Voor eindgebruikers betekende dit aanzienlijk minder downtime in vergelijking met de vorige configuratie met één regio. Geografische routering verbeterde de ervaring verder door klanten naar de dichtstbijzijnde goed functionerende implementatie te leiden, wat niet alleen de latentie verminderde, maar ook de applicatieprestaties verbeterde. Tijdens de kwartaaltests schaalde de secundaire regio succesvol op van minimale capaciteit naar volledige belasting, allemaal binnen de beoogde RTO-termijn.
Kosten-batenanalyse
Naast het behalen van technische doelstellingen bleek de nieuwe architectuur ook een slimme financiële zet. Het warm standby-model bood een kostenefficiënt alternatief voor een volledig actieve-actieve configuratie. Door minimale resources actief te houden in de regio US-WEST en gebruik te maken van Serverion's VPS-oplossingen met autoscaling, vermeed het bedrijf de kosten van het 24/7 inactief houden van capaciteit. Gereserveerde instanties voor basisresources droegen bovendien bij aan lagere maandelijkse onderhoudskosten.
Het resultaat? De opzet met meerdere regio's was ongeveer 50% goedkoper Dit is beter dan een volledig hot standby-model, en dat alles met hersteltijden van minuten in plaats van uren. Bovendien minimaliseerde het automatiseren van implementaties met Infrastructure as Code-tools zoals Terraform de handmatige inspanning en zorgde het voor consistente configuraties in alle regio's.
Geleerde lessen en beste praktijken
Het project bracht verschillende belangrijke lessen aan het licht voor het verfijnen van strategieën voor rampenherstel (DR). Een opvallende conclusie was de effectiviteit van VPC-peering voor databasereplicatie. Deze aanpak waarborgde de beveiliging en hield de replicatievertraging onder de 30 seconden – een aanzienlijke verbetering ten opzichte van openbare internetroutering. Een andere belangrijke conclusie was de beslissing om gebruik te maken van netwerkgebaseerde failover via load balancing in plaats van te vertrouwen op DNS-gebaseerde distributie, waardoor problemen veroorzaakt door caching aan de clientzijde werden vermeden.
""Een rampenherstelstrategie is slechts zo goed als de uitvoering ervan. Regelmatig testen en verfijnen zorgen ervoor dat het plan relevant en effectief blijft." – Rahul Vala, DevOps Engineer
Regelmatige oefeningen voor noodherstel bleken ook essentieel. Deze oefeningen hielpen bij het opsporen van kleine configuratieproblemen die tijdens echte incidenten hadden kunnen escaleren. De consistente tests bevestigden een cruciaal punt: de enige manier om ervoor te zorgen dat een noodherstelplan werkt wanneer het het meest nodig is, is door regelmatige validatie. Deze bevindingen hebben sindsdien richting gegeven aan bredere inspanningen om de veerkracht in meerdere regio's voor alle kritieke infrastructuren te versterken.
Conclusie: Het bouwen van veerkrachtige infrastructuur met Serverion
In de snel veranderende wereld van vandaag is noodherstel over meerdere regio's meer dan alleen een vangnet – het is een cruciaal onderdeel van bedrijfscontinuïteit. Door een actieve-actieve architectuur over meerdere regio's te implementeren, kunnen bedrijven snel herstellen met minimale verstoring. De wereldwijde infrastructuur van Serverion, verspreid over 37 datacenters, maakt gebruik van geografische spreiding om essentiële systemen te beschermen tegen regionale storingen.
Deze robuuste configuratie biedt meer dan alleen veerkracht. Met dynamische load balancing garandeert Serverion te allen tijde optimale prestaties. Actieve load balancing, gecombineerd met Anycast-routing, maakt vrijwel onmiddellijke failover mogelijk – vaak binnen enkele seconden. Dit betekent dat servers altijd actief verkeer beheren, downtime voorkomen en een uptime van 99,991 TP3T garanderen. Voor bedrijven waar elke seconde telt, transformeert deze architectuur disaster recovery in een prestatiegerichte strategie.
De oplossingen van Serverion voorzien in een breed scala aan behoeften, van instap-VPS tot krachtige dedicated servers. AI GPU-oplossingen. Het platform vereenvoudigt de complexiteit van disaster recovery door load balancing op zowel Layer 4 als Layer 7 te beheren, geautomatiseerde health checks uit te voeren en verkeer in realtime te verdelen. Dankzij vooraf geconfigureerde instellingen en deskundige ondersteuning kunnen bedrijven van elke omvang een bedrijfsbrede veerkracht bereiken zonder dat ze gespecialiseerde interne teams nodig hebben. Serverion maakt het eenvoudiger dan ooit om een betrouwbare, krachtige infrastructuur te bouwen.
Veelgestelde vragen
Wat zijn de voordelen van een rampenherstelstrategie die meerdere regio's omvat?
A rampenherstel in meerdere regio's (DR) Deze strategie versterkt de bedrijfsvoering door middelen over verschillende geografische gebieden te spreiden. Deze opzet verkleint de kans op een single point of failure, waardoor bedrijven soepel kunnen blijven functioneren, zelfs als één regio uitvalt. Het zorgt ervoor dat cruciale gegevens beschermd blijven, downtime tot een minimum wordt beperkt en het klantvertrouwen behouden blijft dankzij een naadloze failover tussen regio's.
Naast veerkracht verbetert deze strategie ook de prestaties en het aanpassingsvermogen. Door de werklast over verschillende regio's te verdelen, kunnen bedrijven de latentie voor gebruikers op verschillende locaties verlagen en voorkomen dat ze te afhankelijk worden van één datacenter. Het biedt ook bescherming tegen regionale verstoringen zoals natuurrampen, waardoor essentiële diensten toegankelijk blijven. Het implementeren van deze aanpak is cruciaal voor het creëren van een betrouwbaar en schaalbaar IT-raamwerk.
Hoe verbetert geografische DNS-routering de betrouwbaarheid van een systeem?
Geografische DNS-routering verhoogt de betrouwbaarheid van het systeem door gebruikersverkeer naar de best mogelijke server te leiden op basis van factoren zoals de locatie van de gebruiker, de status van de server of de huidige netwerkcondities. Deze configuratie leidt tot snellere reactietijden, een lagere latentie en een kleinere kans op serviceonderbrekingen.
Als een server uitvalt, leidt het systeem het verkeer automatisch om naar een andere, functionerende server, waardoor gebruikers ononderbroken toegang behouden. Deze methode verbetert beide aspecten. beschikbaarheid van de dienst en prestatie, waardoor het een essentiële oplossing is voor bedrijven die afhankelijk zijn van het leveren van consistente, hoogwaardige service.
Wat zijn de kostenvoordelen van een warm standby-model ten opzichte van een actief-actief-configuratie?
A warm standby-model Het biedt een budgetvriendelijker alternatief voor een actieve-actieve configuratie door een gedeeltelijk actieve omgeving te gebruiken. Tijdens normale werkzaamheden worden de resources teruggeschroefd, waardoor de kosten laag blijven. Deze resources worden pas volledig geactiveerd in geval van een calamiteit, zodat het systeem snel kan herstellen wanneer dat nodig is.
Deze aanpak biedt een evenwicht tussen kostenbesparing en paraatheid, waardoor bedrijven een betrouwbare optie voor noodherstel krijgen zonder de hoge kosten van een volledig actief systeem dat 24 uur per dag operationeel is.




