
Case Study: Multi-Region DR with Load Balancing
Downtime can cost businesses thousands of dollars per hour. This case study shows how an e-commerce company avoided such losses by implementing a multi-region disaster recovery (DR) strategy. After a single-region outage in October 2025 caused over $40,000 in lost revenue, the company deployed a dual-region setup using Serverion‘s infrastructure. The solution included:
- Recovery Time Objective (RTO): 2–5 minutes
- Recovery Point Objective (RPO): Under 30 seconds
- Geographic DNS routing and load balancing for automatic failover
- Cost-effective architecture using a warm standby model
The Challenge: Single-Region Infrastructure Risks
Single-Point Failure Vulnerabilities
Relying on a single eastern data center for all critical components – like dedicated servers, databases, and storage – created a major weak spot for the company. This setup left them exposed to regional disruptions that could bring everything to a halt. A power grid failure, network outage, or natural disaster could take down the entire system, and there was no backup location to keep services running. This fragile architecture ultimately led to a costly outage, highlighting the dangers of depending on a single region.
Downtime Impact on Business Operations
In October 2025, a US-EAST-1 outage brought their e-commerce platform to a standstill for almost an entire day. The financial hit was staggering. With a revenue rate of $10,000 per hour, even a four-hour outage racked up $40,000 in losses. The extended downtime compounded this figure, making the financial and operational impact even worse. Beyond the immediate revenue loss, critical internal operations were also paralyzed.
"Every minute of downtime translates to lost revenue… A single prolonged outage can destroy years of trust-building." – Rahul Vala, Technology Analyst
This incident exposed a glaring issue with their recovery strategy. Their Recovery Time Objective aimed for restoration within minutes, but the outage stretched far beyond that, leaving customers frustrated. Error pages and abandoned shopping carts painted a clear picture of the damage. The company quickly realized that without real-time replication to a secondary region, they were putting both their revenue and reputation on the line every single day.
sbb-itb-59e1987
AWS Route 53 Failover | Multi Region Disaster Recovery with HTTPS
The Solution: Multi-Region DR with Serverion Load Balancing

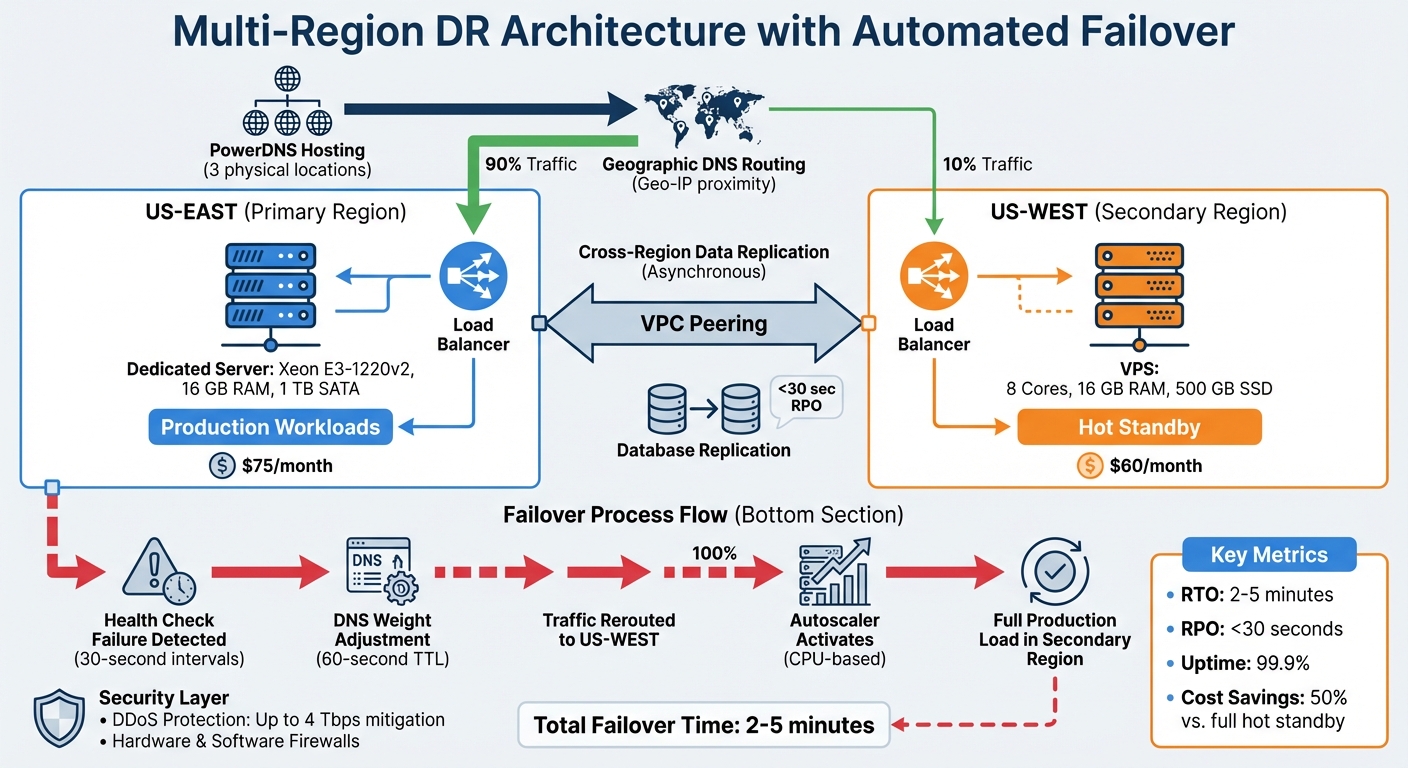
Multi-Region Disaster Recovery Architecture and Failover Process
Serverion’s Multi-Region Architecture
The company revamped its infrastructure using Serverion’s global network of 37 datacenter locations, setting up a primary site in US-EAST and a secondary disaster recovery site in US-WEST. This active/passive setup ensures a hot standby in US-WEST, avoiding delays in resource activation during emergencies.
The system uses cross-region data replication in asynchronous-commit mode to maintain performance. Within the primary region, two instances operate in synchronous-commit mode across different zones, reducing the risk of data loss in case of a zone-level failure. Automated backups further support a low Recovery Point Objective. Geographic DNS routing – powered by Serverion’s PowerDNS hosting across three global locations – directs traffic to the nearest load balancer based on Geo-IP proximity. This approach addresses the vulnerability of single-region setups and ensures more reliable service availability.
Load Balancing for High Availability
To complement the multi-region setup, integrated load balancing plays a key role in managing traffic effectively. Geographic load balancing reduces latency while ensuring automatic failover. Three independent health check probes continuously monitor each load balancer. In case of a failure, DNS routing policies dynamically adjust record weights, shifting traffic from the primary region to the secondary.
Failover timing follows a calculated approach: Duration of outage = DNS TTL + (Health Check Interval × Unhealthy Threshold). With a DNS Time-to-Live set at 60 seconds and health check intervals at 30 seconds, downtime is kept under two minutes. This precise configuration meets the business’s goal of minimal service interruption. Regional load balancers work independently, ensuring that a failure in one region doesn’t disrupt the entire network.
Serverion Hosting Solutions Used
To deliver this robust architecture, the company utilized several Serverion services. The solution combined dedicated servers in US-EAST with SSD-based VPS instances in US-WEST, creating a resilient hot standby setup.
PowerDNS hosting enabled the geographic routing necessary for automatic failover. Serverion’s Ultimate DDoS Protection, capable of handling attacks up to 4 Tbps, safeguarded both regions against malicious traffic spikes that could trigger false failover events. Around-the-clock monitoring ensured real-time failure detection and automated alerts, while consistent security policies were maintained with hardware and software firewalls across both regions. Together, these services provided the 99.9% uptime required to meet the company’s aggressive Recovery Time Objective.
| Service | Configuration | Monthly Cost | Role |
|---|---|---|---|
| Dedicated Server (Primary) | Xeon E3-1220v2, 16 GB RAM, 1 TB SATA | $75 | Production workloads in US-EAST |
| VPS (Secondary) | 8 Cores, 16 GB RAM, 500 GB SSD | $60 | Hot standby in US-WEST |
| PowerDNS Hosting | 3 physical locations | Included | Geographic traffic routing |
| DDoS Protection | Up to 4 Tbps mitigation | Included | Attack prevention across regions |
Implementation: Deployment and Failover Process
Multi-Region Infrastructure Deployment
The deployment process started by setting up separate VPC networks for US-EAST and US-WEST regions. These networks were linked using VPC Peering, enabling private and secure database replication without exposing any traffic to the public internet. To maintain consistency, the team used Terraform to create instance templates and Managed Instance Groups in both regions. This automation ensured that security policies, firewall rules, and SSL certificates were replicated seamlessly across locations.
To detect potential issues quickly, multi-source health checks were implemented, offering robust anomaly detection across the infrastructure. Cross-region database replication was also established, keeping latency low and ensuring the Recovery Point Objective (RPO) stayed under 30 seconds. These steps created a reliable foundation for failover operations.
Failover and Failback Procedures
With the deployment in place, failover mechanisms were designed to guarantee uninterrupted service. If health checks identify a regional outage, traffic is automatically rerouted using DNS failover policies. The backup region’s autoscaler is configured to respond instantly, scaling resources to handle the production load. By basing autoscaling on CPU utilization instead of connection rates, the system avoids scaling down prematurely during traffic shifts.
To keep the secondary region operational at all times, 10% of traffic is continuously routed there – a method known as traffic trickling. This ensures the US-WEST infrastructure remains active and ready. When the primary region recovers, failback happens automatically once health checks confirm stability. During the transition, both regions can handle traffic simultaneously, ensuring there’s no downtime.
Testing and Validation
Quarterly disaster recovery drills are conducted to simulate failures in the primary region. These drills might involve scaling instances to zero or temporarily removing firewall tags. The goal is to verify that traffic reroutes within a two-minute window while the secondary region scales as needed. Automated checks validate service status, critical port connectivity, and data integrity before declaring the failover successful. Regular testing, managed through Terraform, consistently demonstrates that the architecture meets the company’s demanding recovery goals across its US data centers.
Results and Key Takeaways
Resilience Metrics Achieved
The multi-region setup delivered impressive resilience metrics, achieving an RTO (Recovery Time Objective) of 2–5 minutes and an RPO (Recovery Point Objective) under 30 seconds. Health checks confirmed uninterrupted data path availability, while network-based failover eliminated delays caused by DNS propagation.
For end users, this meant far less downtime compared to the previous single-region setup. Geo-proximity routing further enhanced the experience by directing customers to the nearest healthy deployment, which not only reduced latency but also improved application performance. During quarterly drills, the secondary region successfully scaled from minimal capacity to full load, all within the targeted RTO window.
Cost-Effectiveness Analysis
Beyond delivering on technical goals, the new architecture proved to be a smart financial move. The warm standby model offered a cost-efficient alternative to a full active-active setup. By keeping minimal resources active in the US-WEST region and utilizing Serverion’s VPS solutions with auto-scaling, the company avoided the expense of maintaining idle capacity 24/7. Reserved instances for baseline resources also helped reduce monthly maintenance costs.
The result? The multi-region setup was about 50% cheaper than a full hot standby model, all while providing recovery times measured in minutes instead of hours. Additionally, automating deployments with Infrastructure as Code tools like Terraform minimized manual effort and ensured consistent configurations across regions.
Lessons Learned and Best Practices
The project highlighted several important lessons for refining disaster recovery (DR) strategies. One standout takeaway was the effectiveness of VPC Peering for database replication. This approach maintained security while keeping replication lag under 30 seconds – a significant improvement over public internet routing. Another key insight was the decision to use network-based failover via load balancing rather than relying on DNS-based distribution, which avoided issues caused by client-side caching.
"A Disaster Recovery strategy is only as good as its execution. Regular testing and refinement ensure the plan stays relevant and effective." – Rahul Vala, DevOps Engineer
Routine disaster recovery drills also proved essential. These drills helped uncover minor configuration problems that could have escalated during real incidents. The consistent testing reinforced a critical point: the only way to ensure a DR plan works when it’s needed most is through regular validation. These findings have since guided broader efforts to strengthen multi-region resilience across all critical infrastructures.
Conclusion: Building Resilient Infrastructure with Serverion
In today’s fast-paced world, multi-region disaster recovery is more than just a safety net – it’s a critical component of business continuity. By adopting a multi-region active-active architecture, businesses can achieve rapid recovery with minimal disruption. Serverion’s global infrastructure, spread across 37 data center locations, uses geographic diversity to shield essential systems from regional failures.
This robust setup doesn’t just stop at resilience. With dynamic load balancing, Serverion ensures peak performance at all times. Active-active load balancing, combined with Anycast routing, enables near-instant failover – often within seconds. This means servers are always actively managing traffic, avoiding downtime and delivering 99.99% uptime reliability. For businesses where every second counts, this architecture transforms disaster recovery into a performance-driven strategy.
Serverion’s solutions cater to a wide range of needs, from entry-level VPS to high-performance dedicated servers and AI GPU solutions. The platform simplifies the complexities of disaster recovery by managing both Layer 4 and Layer 7 load balancing, performing automated health checks, and distributing traffic in real time. With pre-configured setups and expert support, businesses of any size can achieve enterprise-level resilience without needing specialized in-house teams. Serverion makes it easier than ever to build a reliable, high-performing infrastructure.
FAQs
What are the advantages of a multi-region disaster recovery strategy?
A multi-region disaster recovery (DR) strategy strengthens business operations by spreading resources across different geographic areas. This setup reduces the chances of a single point of failure, allowing businesses to keep running smoothly even if one region faces an outage. It ensures critical data stays protected, downtime is kept to a minimum, and customer trust remains intact through seamless failover between regions.
Beyond resilience, this strategy also enhances performance and adaptability. By distributing workloads across regions, businesses can cut down on latency for users in various locations and avoid depending too heavily on one data center. It also provides a safeguard against regional disruptions like natural disasters, ensuring essential services stay accessible. Incorporating this approach is key to creating a reliable and scalable IT framework.
How does geographic DNS routing improve system reliability?
Geographic DNS routing boosts system reliability by steering user traffic to the best possible server based on factors such as user location, server health, or current network conditions. This setup leads to quicker response times, lower latency, and a reduced chance of service disruptions.
If a server goes down, the system automatically redirects traffic to another functioning server, ensuring uninterrupted access for users. This method improves both service availability and performance, making it a key solution for businesses that depend on delivering consistent, high-quality service.
What are the cost benefits of using a warm standby model compared to an active-active setup?
A warm standby model offers a more budget-friendly alternative to an active-active setup by operating a partially active environment. During regular operations, resources are scaled down, keeping costs low. These resources are only fully activated in the event of a disaster, ensuring the system can quickly recover when necessary.
This approach strikes a balance between cost savings and preparedness, giving businesses a dependable disaster recovery option without the hefty price tag of running a fully active system around the clock.




