
Hoe werkt het samenvoegen van containerlogboeken?
Aggregatie van containerlogs vereenvoudigt het verzamelen en organiseren van logs van containers met een korte levensduur in één centraal systeem. Dit proces is essentieel omdat containeromgevingen enorme hoeveelheden logbestanden genereren en containers vaak snel verdwijnen, waardoor de logbestanden verloren gaan. Zonder aggregatie wordt het oplossen van problemen inefficiënt en gefragmenteerd.
Dit is wat u moet weten:
- Containers loggen naar streams (STDOUT/STDERR), niet naar bestanden. Logbestanden verdwijnen wanneer containers stoppen, tenzij ze naar externe systemen worden doorgestuurd.
- Beheerde Kubernetes Centraliseert logboeken op knooppuntniveau. Tools zoals kubelet verzorgen de logrotatie, terwijl paden zoals
/var/log/pods/Bewaar logbestanden tijdelijk. - Verzamelmethoden omvatten agents op knooppuntniveau en sidecars. Node-agents (zoals Fluent Bit) zijn efficiënt voor clusterbrede logboeken, terwijl sidecars geschikt zijn voor applicaties met aangepaste logboekformaten.
- Centrale opslag garandeert continuïteit. Logbestanden worden naar platforms zoals Elasticsearch of Loki gestuurd voor het opvragen, analyseren en langdurig bewaren ervan.
Waarom het belangrijk is: Het centraliseren van logbestanden verkort de tijd die nodig is voor het oplossen van problemen, doordat gestructureerde zoekopdrachten en realtime monitoring mogelijk worden. Om te voorkomen dat logbestanden verloren gaan, dient u ze altijd naar standaardstreams te leiden en een betrouwbare infrastructuur te gebruiken voor opslag en transport.
Voor schaalbare configuraties kunt u agents op nodeniveau combineren met robuuste opslagbackends zoals Kafka of Elasticsearch. Dit zorgt ervoor dat logbestanden toegankelijk en georganiseerd blijven, zelfs in omgevingen met een hoog volume.
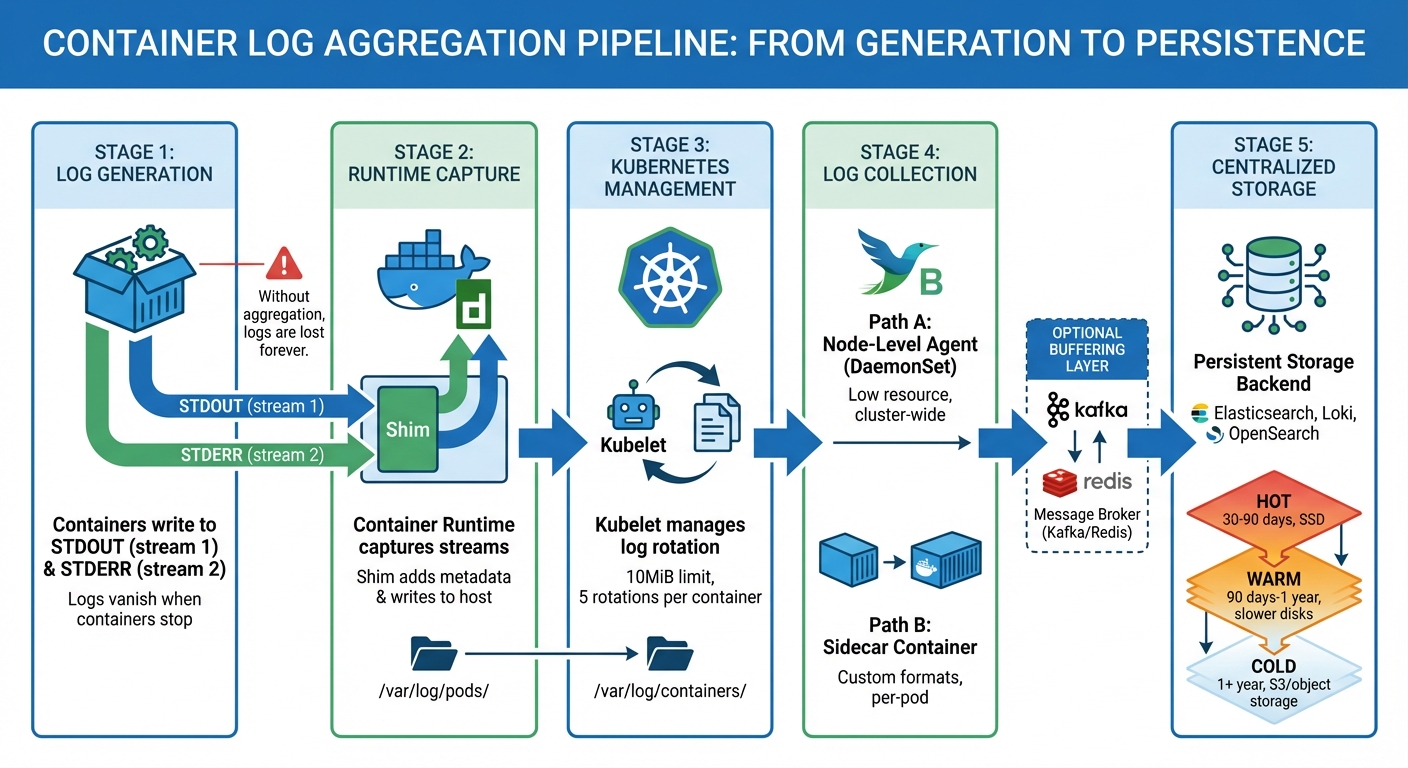
Containerlog-aggregatiepipeline: van generatie tot opslag
Kubernetes-logboekaggregatie: logboeken verzamelen voor het hele cluster | Complete handleiding
sbb-itb-59e1987
Hoe containers logbestanden genereren
Containers genereren logbestanden door gebruik te maken van streams in plaats van ze op te slaan als statische bestanden. Elk proces binnen een container gebruikt drie I/O-streams die afkomstig zijn van Unix: STDIN (stroom 0) voor invoer, STDOUT (stroom 1) voor standaarduitvoer, en STDERR (stream 2) voor foutmeldingen.
Wanneer uw applicatie wordt uitgevoerd, verzendt deze operationele gegevens en statusupdates naar STDOUT, terwijl fouten, waarschuwingen en diagnostische berichten worden doorgestuurd naar STDERR. De containerruntime – of het nu Docker, Containerd of een andere CRI-compatibele tool is – legt deze streams rechtstreeks vast vanuit het gecontaineriseerde proces. Dit wordt bereikt via pipes die de uitvoer van de geïsoleerde omgeving van de container omleiden naar de container. virtuele privéservers hostbestandssysteem.
""De eenvoudigste en meest gebruikte logmethode voor gecontaineriseerde applicaties is het schrijven naar de standaard uitvoer- en standaardfoutstreams." – Kubernetes-documentatie
Het is belangrijk om logbestanden niet op te slaan in de beschrijfbare laag van de container. Zodra een container stopt of wordt verwijderd, verdwijnt alles erin – inclusief alle logbestanden. Om te voorkomen dat logbestanden verloren gaan, moeten applicaties alle logboekregistratie doorsturen naar de beschrijfbare laag van de container. STDOUT en STDERR. Voor oudere applicaties die logbestanden schrijven, kunt u symbolische links maken naar /dev/stdout of /dev/stderr.
Laten we nu eens bekijken hoe deze uitvoerstromen worden vastgelegd en beheerd.
Containerloguitvoerstreams
Container-runtimes doen meer dan alleen logs vastleggen – ze formatteren en beheren ze ook. Wanneer Docker of Containerd gegevens ontvangt van STDOUT of STDERR, een component genaamd de Vulplaatje Het verwerkt het. De Shim leest de uitvoer, voegt metadata toe en schrijft deze naar logbestanden op de host. Deze configuratie zorgt ervoor dat loggegevens bewaard blijven, zelfs als de container een korte levensduur heeft.
Docker maakt gebruik van logboekstuurprogramma's om te bepalen hoe en waar logbestanden worden opgeslagen. De standaard json-bestand De driver slaat logbestanden op in JSON-formaat op de schijf van de host. Elk logbericht bevat de tijdstempel, de bronstream (stdout of stderr) en het logbericht zelf. Om prestatieproblemen bij grote hoeveelheden uitvoer te voorkomen, biedt Docker een niet-blokkerende modus. Deze modus gebruikt een buffer van 1 MB per container om vastlopen te voorkomen, hoewel dit wel betekent dat sommige berichten mogelijk verloren gaan als de buffer vol raakt.
| Streamnaam | Bestandsdescriptor | Doel |
|---|---|---|
| STDIN | 0 | Invoer |
| STDOUT | 1 | Standaarduitvoer |
| STDERR | 2 | Foutmeldingen |
Het verschil begrijpen tussen STDOUT en STDERR is cruciaal voor filtering en waarschuwingen. Omdat STDERR Deze gegevensstroom markeert doorgaans fouten of waarschuwingen. Monitoringtools kunnen worden geconfigureerd om waarschuwingen te verzenden op basis van deze gegevensstroom, terwijl ze tegelijkertijd de fouten of waarschuwingen verwerken. STDOUT als informatief. Applicaties kunnen echter problemen ondervinden als deze streams blokkeren door tegendruk. De niet-blokkerende modus van Docker verhelpt dit probleem, hoewel dit ten koste gaat van het mogelijk verliezen van nieuwe logberichten.
Hoewel container-runtimes de basis van logging afhandelen, gaat Kubernetes een stap verder met beheerbeleid op knooppuntniveau.
Kubernetes-logbeheer
In Kubernetes, de kubelet Het neemt de verantwoordelijkheid voor het beheren van logbestanden op zich. Het bepaalt waar logbestanden op elke node worden opgeslagen en handhaaft rotatiebeleid om te voorkomen dat de schijfruimte opraakt. Standaard slaat Kubernetes containerlogbestanden op in het volgende pad:
/var/log/pods/{namespace}_{pod-name}_{pod-uid}/{container-name}/{restart-count}.log.
Daarnaast creëert het symbolische verbindingen bij /var/log/containers/ voor eenvoudigere toegang door mensen en logboekverzamelingstools.
Kubernetes roteert logbestanden zodra ze een grootte van 10 MiB bereiken, waarbij maximaal vijf rotaties per container worden bewaard. Een pod met drie containers heeft bijvoorbeeld drie afzonderlijke sets logbestanden. Wanneer je dit uitvoert... kubectl logs, De kubelet haalt deze bestanden rechtstreeks uit de opslag van het knooppunt.
""Shim is verantwoordelijk voor: het lezen van stdout/stderr-uitvoer van containerprocessen... het formatteren van logbestanden... en het rechtstreeks schrijven naar logbestanden." – Addo Zhang, CNCF-ambassadeur
De integratie tussen de kubelet en de containerruntime volgt het CRI-logformaat (Container Runtime Interface). Deze standaard zorgt ervoor dat Kubernetes logboeken consistent verwerkt, ongeacht de gebruikte runtime – of het nu Docker, Containerd, CRI-O of een andere optie is. Vanaf Kubernetes v1.32 is er een nieuwe alpha-functie genaamd PodLogsQuerySplitStreams Hiermee kunt u een zoekopdracht uitvoeren. STDOUT en STDERR streams afzonderlijk via de Pod API. Dit geeft je meer controle over welke logstreams je wilt benaderen.
Deze mechanismen zorgen ervoor dat Kubernetes gecentraliseerde systemen kan voorzien van gestructureerde, betrouwbare loggegevens.
Logboekverzamelingsmethoden
Wanneer containers logbestanden naar het bestandssysteem van een node schrijven, hebt u een betrouwbare manier nodig om deze logbestanden in uw hele cluster te verzamelen. Er zijn twee belangrijke benaderingen: agenten op knooppuntniveau voor efficiënte, clusterbrede logverwerking, en zijspancontainers voor toepassingsspecifieke behoeften. Elke methode biedt specifieke voordelen, afhankelijk van uw configuratie en vereisten.
Logboekregistratieagenten op knooppuntniveau
Het gebruik van loggingagents op knooppuntniveau houdt in dat er op elk knooppunt een loggingtool wordt geïmplementeerd via Kubernetes. DaemonSet. Dit zorgt ervoor dat er op elk werkknooppunt één agent-pod actief is – die tools zoals Fluentd of Fluent Bit uitvoert. Deze agents koppelen mappen zoals /var/log/pods of /var/log/containers, waardoor directe toegang wordt verkregen tot de containerlogboeken die op de host zijn opgeslagen.
""Agent op knooppuntniveau, zoals een Fluentd daemonset. Dit is het aanbevolen patroon." – AWS Native Observability Guide
De agent bewaakt continu logbestanden en verrijkt deze met Kubernetes-metadata (zoals podnaam, namespace, containernaam en labels) om het zoeken in de logs in gecentraliseerde opslagsystemen zoals Elasticsearch of OpenSearch te vergemakkelijken. Vloeiend stukje Het is een populaire keuze voor deze rol vanwege het lichte ontwerp en het minimale grondstoffenverbruik.
Om de prestaties te optimaliseren, configureert u de agent als volgt: Filter logs bij de bron.. Het verwijderen van onnodige logbestanden op knooppuntniveau vermindert zowel het netwerkverkeer als de opslagkosten. Stel limieten in voor de geheugenbuffer (bijv., Mem_Buffer_Limit (in Fluent Bit) om overmatig geheugengebruik tijdens logpieken of backend-uitval te voorkomen. Configureer voor grote clusters agents om metadata lokaal van de kubelet op te halen (Gebruik_Kubelet) in plaats van de Kubernetes API-server te bevragen, wat helpt om API-snelheidslimieten te omzeilen.
| Functie | Agent op knooppuntniveau (DaemonSet) | Zijspancontainer |
|---|---|---|
| Brongebruik | Laag (één agent per knooppunt) | Hoog (één agent per pod) |
| App-aanpassing | Geen vereist | Vereist wijzigingen in de pod-specificaties. |
| Schaalbaarheid | Hoog | Matig (vergroot de voetafdruk van de pod) |
| Beste gebruiksscenario | Logboekafhandeling op clusterniveau | Apps met aangepaste logformaten |
kubectl logs Ondersteuning | Volledig ondersteund | Niet ondersteund voor door de agent verwerkte logboeken. |
Deze methode biedt een schaalbare en efficiënte manier om logbestanden te verzamelen binnen uw cluster zonder individuele applicaties aan te passen.
Zijspancontainers voor het verzamelen van houtblokken
Sidecar-containers bieden een meer op maat gemaakte aanpak, vooral wanneer applicaties rechtstreeks naar bestanden loggen. zijspan container Deze applicatie draait naast de hoofdapplicatiecontainer in dezelfde pod en deelt opslag- en netwerknamespaces. Deze configuratie is ideaal voor applicaties die logs naar bestanden schrijven in plaats van naar de server. STDOUT of STDERR, met name bij complexe formaten zoals Java-logbestanden met meerdere regels, die agenten op knooppuntniveau mogelijk moeilijk kunnen verwerken.
""Het sidecar-/agentmodel... is nuttig wanneer het verwerken van logs uit containerlogs mogelijk niet zo efficiënt is als het rechtstreeks lezen vanuit een applicatie (bijv. Java-verwerking van meerdere regels)." – Anurag Gupta, Fluent Bit
In dit model schrijft de applicatie logbestanden naar een gedeeld volume (meestal een Kubernetes-volume). lege map), en de sidecar-container volgt deze logs en stuurt ze door naar een gecentraliseerde backend. Tools zoals Fluentd, Fluent Bit en Filebeat worden vaak als sidecars gebruikt. Vanaf Kubernetes v1.29 maakt native sidecar-ondersteuning het mogelijk om sidecars te definiëren als herstartbare init-containers met herstartbeleid: Altijd, waardoor ze starten vóór de hoofdcontainer en pas stoppen nadat deze is beëindigd.
Hoewel sidecars nauwkeurige logverwerking mogelijk maken, brengen ze hogere resourcekosten met zich mee. Elke pod draait zijn eigen loggingagent, wat de opslagvereisten kan verdubbelen als de sidecar logs naar de pod streamt. STDOUT. Om de overhead te minimaliseren, gebruik sidecars alleen voor applicaties die niet rechtstreeks naar standaardstreams kunnen loggen, en zorg ervoor dat de sidecar-container zo licht mogelijk is.
Centraliseren en transporteren van boomstammen
Na de bespreking van het genereren en verzamelen van logs, gaan we nu dieper in op hoe logs worden gecentraliseerd en getransporteerd. Eenmaal verzameld, moeten logs worden opgeslagen in een betrouwbare opslagplaats die bestand is tegen herstarts van pods en nodefouten. Dit proces omvat vaak het gebruik van een bufferlaag om plotselinge pieken in het verkeer op te vangen en een extern opslagsysteem dat is ontworpen voor snelle query's. Hieronder zullen we onderzoeken hoe logs worden getransporteerd en georganiseerd voor efficiënte toegang.
Berichtbrokers voor logboektransport
Door gebruik te maken van een berichtenbroker zoals Apache Kafka Kafka is een veelgebruikte methode om logtransport af te handelen. Kafka fungeert als buffer tussen logagents en de opslag, waardoor wordt gegarandeerd dat logs niet verloren gaan tijdens pieken in het verkeer. Door logproducenten en -consumenten los te koppelen, zorgt Kafka ervoor dat agents logs kunnen blijven schrijven, zelfs als het opslagsysteem tijdelijk niet beschikbaar of overbelast is. Deze configuratie zorgt ervoor dat logs veilig in de wachtrij worden geplaatst totdat het opslagsysteem klaar is om ze te verwerken.
Voor eenvoudigere configuraties, Redis Het kan functioneren als een lichtgewicht wachtrij, hoewel het niet de duurzaamheid biedt die Kafka wel biedt. In AWS-omgevingen, Kinesis Data Firehose Kafka is vaak een populaire beheerde service die automatisch schaalt met het logvolume. Bij het instellen van Kafka is het belangrijk om de partities zorgvuldig te berekenen: deel de totale doorvoer door de laagste snelheid van de producent of de consument, en houd het aantal partities onder de 4000 per broker om de prestaties te behouden.
Logboekopslagorganisatie
De manier waarop logbestanden worden opgeslagen, hangt grotendeels af van het gebruikte opslagsysteem. Hulpmiddelen zoals Elasticsearch en OpenSearch Logboeken ordenen in tijdgebaseerde indexen (bijv., logstash-2026.02.16), waardoor het opvragen van recente gegevens sneller gaat. Aan de andere kant, Grafana Loki Het maakt gebruik van een kostenefficiëntere methode door alleen metadata (zoals namespace, podnaam en containernaam) te indexeren, terwijl de loginhoud wordt opgeslagen in gecomprimeerde objectopslag.
Voor het langdurig bewaren van logbestanden wordt vaak een gelaagd opslagsysteem gebruikt:
- Hot tierLogbestanden worden 30 tot 90 dagen bewaard op krachtige SSD's, ideaal voor actieve probleemoplossing.
- Warme laagLogbestanden worden naar tragere schijven verplaatst voor historische analyse en worden doorgaans 90 dagen tot een jaar bewaard.
- Koude laagLogbestanden ouder dan een jaar worden gearchiveerd in objectopslag, zoals AWS S3, voor nalevings- of auditdoeleinden.
Wanneer logbestanden in objectopslag worden opgeslagen, worden ze vaak gepartitioneerd op datum en servicenaam. Deze structuur helpt bij het optimaliseren van query's voor tools zoals Amazon Athena, waardoor het gemakkelijker wordt om specifieke logbestanden op te halen wanneer dat nodig is.
Logboeken analyseren en raadplegen
Zodra de logbestanden gecentraliseerd zijn, kunt u ze gebruiken CLI-tools voor snelle probleemoplossing of vertrouw op gecentraliseerde backends voor een diepgaande analyse. Hulpmiddelen zoals kubectl logs en docker logs Ze zijn perfect voor directe toegang, omdat ze rechtstreeks lokale logbestanden lezen door te communiceren met de containerruntime of kubelet. Deze tools vereisen geen gecentraliseerde backend, waardoor ze handig zijn voor realtime controles.
Voor meer geavanceerde analyses worden logbestanden naar platforms zoals Elasticsearch, OpenSearch of Grafana Loki gestuurd. Elk systeem verwerkt gegevens op een andere manier: Elasticsearch gebruikt tijdgebaseerde indexen (bijv., logstash-2026.02.16) voor full-text zoeken, terwijl Loki zich richt op het indexeren van metadata zoals podnamen, namespaces en labels, en de daadwerkelijke loginhoud opslaat in gecomprimeerde objectopslag. Deze aanpak maakt Loki een kosteneffectieve optie voor grootschalige implementaties. Zoals de Kubernetes-documentatie het stelt:, ""In een cluster moeten logbestanden een aparte opslag en levenscyclus hebben, onafhankelijk van knooppunten, pods of containers. Dit concept wordt cluster-level logging genoemd.""
Bij het opvragen van logbestanden kunnen tools zoals KQL (Kibana Query Language) Ofwel SQL-gebaseerde syntax wordt vaak gebruikt. Het zoeken naar fouten in een specifieke namespace kan er bijvoorbeeld zo uitzien: log.level: "ERROR" EN kubernetes.namespace: "production"". Op de commandoregel, kubectl logs biedt filteropties zoals labels (-l app=nginx), tijdsperioden (--sinds=1 uur), en zelfs het ophalen van logbestanden van gecrashte containers met behulp van de --vorig vlag. Hoewel CLI-tools geweldig zijn voor directe behoeften, bieden gecentraliseerde systemen een breder overzicht voor historische en trendanalyses.
CLI-tools voor logboekquery's
Commandoregeltools zijn onmisbaar voor snel inzicht, vooral wanneer logbestanden centraal worden verzameld. kubectl logs Het commando wordt veel gebruikt, maar het heeft wel beperkingen. Kubernetes kubelet roteert bijvoorbeeld logbestanden wanneer ze een bepaalde grootte bereiken. 10 mijl en houdt alleen 5 bestanden per container. Dit betekent dat als een pod 40 MiB aan logs genereert, je alleen de meest recente 10 MiB zult zien. kubectl logs. Voor problemen op systeemniveau draaien Linux-nodes. systemd Hiermee kunt u kubelet- en container-runtimelogs opvragen met de journalctl commando.
Hier volgen enkele nuttige tips. kubectl logs vlaggen:
--sinds: Haalt logbestanden op uit een specifiek tijdsbestek, zoals het laatste uur (--sinds=1 uur).--staart: Beperkt de uitvoer tot de laatste paar regels, bijvoorbeeld de meest recente 20 regels (--tail=20).--tijdstempelsVoegt tijdstempels toe aan elke logregel, waardoor het gemakkelijker wordt om timinggerelateerde problemen te analyseren.
Vergelijking van aggregatiemodi
Het begrijpen van de verschillen tussen lokale logrotatie en gecentraliseerde aggregatie is essentieel voor het kiezen van de juiste aanpak. Lokale rotatie, beheerd door de kubelet, slaat logs op de schijf van de node op. /var/log/pods. Deze logbestanden gaan echter verloren wanneer een pod wordt verwijderd of een node uitvalt. Gecentraliseerde aggregatie daarentegen slaat logbestanden op in externe systemen zoals Elasticsearch of cloudopslag, waardoor de logbestanden toegankelijk blijven, zelfs nadat containers zijn beëindigd.
| Functie | Standaard (lokale) rotatie | Gecentraliseerde aggregatie |
|---|---|---|
| Opslaglocatie | Lokale schijf van het knooppunt (/var/log/pods) | Externe backend (bijv. Elasticsearch, cloudopslag) |
| Vasthoudendheid | Logbestanden worden verwijderd na rotatie of verwijdering van de pod. | Behouden na afloop van de levenscyclus van pods en nodes. |
| Toegankelijkheid | Toegang via kubectl logs (alleen het meest recente bestand) | Toegang via webinterface of API (volledige geschiedenis) |
| Zoekmogelijkheid | Basis tekststreaming/tailing | Geavanceerde zoekopdrachten, indexering en correlatie |
| Impact op hulpbronnen | Minimaal (afgehandeld door kubelet) | Hoger (vereist agents en netwerkbandbreedte) |
Gecentraliseerde logboekregistratieplatforms kunnen de tijd die besteed wordt aan oorzaakanalyse aanzienlijk verkorten – soms wel met een factor van... 80%, Volgens branchegegevens is deze efficiëntie te danken aan functies zoals geavanceerde querymogelijkheden, correlatie van logboeken van meerdere services en het bewaren van historische gegevens. In omgevingen met grote hoeveelheden logboeken kan het implementeren van logboeksampling in de verzamelfase helpen de opslagkosten te beheersen en tegelijkertijd essentiële inzichten in de systeemprestaties te behouden. Deze balans tussen persistentie en querymogelijkheden is cruciaal voor effectief logboekbeheer.
Hoe Serverion Ondersteunt logboekaggregatie

Nadat u strategieën voor het verzamelen en opslaan van logbestanden hebt ingesteld, is de volgende stap het beschikken over de juiste infrastructuur om de integriteit van de logbestanden te waarborgen – en dat is waar Serverion in uitblinkt. Effectieve logaggregatie vereist beide. permanente opslag en hoogwaardige infrastructuur, Dat is precies wat de VPS- en dedicated servers van Serverion bieden. Omdat containers van nature tijdelijk zijn, verdwijnen hun logs wanneer de container stopt, tenzij er stabiele hostopslag is om ze te bewaren. Permanente opslag is essentieel om logs intact te houden gedurende de levenscyclus van containers, vooral bij podfouten of herstarts. Serverion pakt dit aan door dedicated opslag aan te bieden die is gekoppeld aan de host. /var/log/, waardoor uw logbestanden behouden blijven na herstarts van containers, verwijdering van pods en zelfs bij het uitvallen van knooppunten.
Servers Ze onderscheiden zich door hun vermogen om logaggregatietaken af te handelen. In tegenstelling tot gevirtualiseerde omgevingen elimineren bare-metal servers de hypervisorlaag, waardoor ze ideaal zijn voor resource-intensieve logtaken en het verwerken van grote hoeveelheden telemetriegegevens. Dit is vooral cruciaal in gedistribueerde containeromgevingen waar logvolumes snel kunnen groeien. Bovendien vermindert het gebruik van een logagent op node-niveau – waarbij één agent logs verzamelt van alle containers op een host – de belasting van de CPU en het geheugen in vergelijking met op sidecars gebaseerde logmethoden.
Serverion's wereldwijde datacentra Voeg een extra laag efficiëntie toe aan logaggregatie. Ze maken het mogelijk om logs dichter bij de bron te verwerken of op te slaan, waardoor de netwerklatentie wordt verminderd en realtime monitoring wordt verbeterd. Deze gedistribueerde aanpak helpt ook om te voldoen aan regionale regelgeving, zoals GDPR of HIPAA, door auditlogs binnen specifieke rechtsgebieden te bewaren. Voor applicaties met veel verkeer ondersteunt Serverion niet-blokkerende loglevering, waarbij logs in het geheugen worden gebufferd (standaard meestal tot 1 MB) voordat ze worden verwerkt. Dit voorkomt dat logbewerkingen uw applicaties vertragen, terwijl de prestaties en compliance worden geoptimaliseerd.
Een ander cruciaal voordeel van de infrastructuur van Serverion is het vermogen om knelpunten in de systeembronnen te voorkomen. Logging-agents zoals Filebeat of Fluentd zijn afhankelijk van een constante I/O- en netwerkbandbreedte, met name tijdens pieken in de logactiviteit. Met dedicated resources kan de logging-pipeline realtime indexering en zoekopdrachten uitvoeren zonder te concurreren met uw productieworkloads om systeembronnen.
Voor organisaties die hun logaggregatie centraliseren, biedt de infrastructuur van Serverion een totaaloplossing: van het implementeren van DaemonSets om logs te verzamelen op elk Kubernetes-knooppunt tot het hosten van opslagbackends die historische gegevens bewaren tot ver na de standaard rotatielimiet van 10 MiB. Deze combinatie van persistente opslag, verwerkingskracht en wereldwijde beschikbaarheid garandeert schaalbare logaggregatie. Met Serverion blijven uw logs toegankelijk en betrouwbaar, ongeacht wat er met individuele containers, pods of knooppunten gebeurt.
Conclusie
In containeromgevingen, Logaggregatie is essentieel. voor het behoud van overzicht en het garanderen van een soepele werking. Containers zijn per definitie tijdelijk. Wanneer ze stoppen of crashen, verdwijnen hun logbestanden. Zonder een gecentraliseerd aggregatiesysteem blijven er verspreide datasilo's over verschillende knooppunten over, waardoor het vrijwel onmogelijk wordt om problemen in gedistribueerde applicaties te diagnosticeren. Zoals Karl Kalash, Product Marketing Manager bij Chronosphere, uitlegt: ""Logaggregatie is een fundamenteel aspect van observeerbaarheid en beveiliging. Door logs te consolideren, krijgt u volledig inzicht in het gedrag en de prestaties van uw systemen, applicaties en infrastructuur.""
Gecentraliseerde logboekregistratie is niet alleen handig, het is ook een echte gamechanger. Praktijkervaringen met SaaS-implementaties tonen aan dat ze de gemiddelde oplostijd van incidenten kunnen verkorten van 4 uur tot minder dan 40 minuten. Zo'n verbetering kan het verschil betekenen tussen een kleine storing en een volledige uitval.
Om dit effectief te laten werken, behandel logbestanden als gebeurtenisstromen en leid ze allemaal door naar STDOUT en STDERR. Implementeer agents op knooppuntniveau om de grote hoeveelheden logbestanden efficiënt te verwerken en gebruik de juiste logrotatie om schijfuitputting te voorkomen. Het allerbelangrijkste is dat uw logbestanden een levenscyclus hebben die onafhankelijk is van de containers die ze genereren. Deze configuratie elimineert de noodzaak voor handmatig zoeken op verschillende knooppunten en maakt geautomatiseerde waarschuwingen en correlaties tussen verschillende lagen mogelijk voor snellere probleemoplossing.
Voor organisaties die containergebaseerde workloads uitvoeren, is de infrastructuur die uw logstrategie ondersteunt net zo cruciaal. Betrouwbare oplossingen, zoals VPS en dedicated servers van Serverion, Wij bieden de opslagcapaciteit, verwerkingskracht en wereldwijde datacenterdekking die nodig zijn om te voldoen aan de eisen van logverwerking en -bewaring. Of u nu een kleine implementatie beheert of honderden nodes, een betrouwbare infrastructuur zorgt ervoor dat uw logs toegankelijk blijven en uw monitoringsystemen responsief blijven – zelfs tijdens incidenten onder hoge druk in de productieomgeving.
Veelgestelde vragen
In welk logformaat moeten mijn containers de output leveren?
Containers moeten logbestanden in een consistent formaat produceren, zoals platte tekst, gericht aan standaarduitvoer en stderr. Deze methode volgt de gevestigde best practices voor het verwerken van logstreams, waardoor logs eenvoudig te verzamelen, centraliseren en analyseren zijn. Door deze aanpak te volgen, wordt de integratie met tools voor logaggregatie vereenvoudigd en het logbeheer binnen containeromgevingen verbeterd.
Wanneer moet ik een sidecar gebruiken in plaats van een node agent?
Wanneer je het nodig hebt isolatie per dienst en nauwkeurige controle voor taken zoals logboekregistratie, monitoring of beveiliging binnen individuele pods, een zijspan Dat is de beste aanpak. Sidecars draaien naast de hoofdcontainer in dezelfde pod en breiden de functionaliteit ervan uit zonder dat er wijzigingen in de code van de container nodig zijn. Dit maakt ze perfect voor het toevoegen van functionaliteiten die zijn afgestemd op specifieke services.
Anderzijds, knooppuntagenten Sidecars werken op knooppuntniveau en verwerken logboeken of statistieken over meerdere pods. Hoewel ze effectief zijn voor bredere taken, bieden ze niet dezelfde mate van controle of isolatie als sidecars voor individuele applicaties of microservices.
Hoe voorkom ik dat logbestanden verloren gaan tijdens backend-uitval?
Om te voorkomen dat logbestanden verloren gaan tijdens backend-uitval, is het belangrijk om te beschikken over... betrouwbare strategieën voor het verzamelen van logboeken op de juiste plek. Zo kunnen lokale buffer- en wachtrijmechanismen bijvoorbeeld helpen om logbestanden tijdelijk op te slaan totdat ze kunnen worden afgeleverd. Tools die zijn ontworpen om logbestanden te bufferen en de aflevering te herhalen, zijn vooral nuttig om ervoor te zorgen dat logbestanden niet verloren gaan tijdens onverwachte downtime.
Het is ook verstandig om logbestanden te centraliseren in een systeem dat zowel schaalbaar als redundant is. Dit zorgt ervoor dat logbestanden toegankelijk en veilig blijven, zelfs als onderdelen van het systeem uitvallen. Daarnaast is het cruciaal om de juiste logrotatie en opslagbeleidsregels in te stellen. Dit helpt om de schijfruimte effectief te beheren en overloop te voorkomen, wat vooral belangrijk is in containeromgevingen waar de resources vaak beperkt zijn.




