
Top Features of Enterprise-Grade Decentralized Storage
In 2026, businesses are facing a surge in data demands, fueled by AI agents processing massive file volumes and global data creation reaching 230–240 zettabytes. Centralized storage systems are struggling to keep up due to rising costs, security risks, and scalability challenges. Decentralized storage offers a solution by leveraging blockchain masternode hosting, distributed architecture, and cost-efficient pricing models. Here’s what makes it stand out:
- Resilient Architecture: Data is split into fragments and distributed across nodes, eliminating single points of failure and ensuring availability even during outages.
- Cost Savings: Zero egress fees and lower storage costs reduce expenses by up to 90% compared to centralized providers like AWS.
- Enhanced Security: Client-side encryption, immutable audit logs, and ransomware-resistant features protect data at every stage.
- Compliance: Tools for managing data residency and tamper-proof audit trails simplify adherence to regulations like GDPR.
- Performance: Parallel data retrieval and edge caching improve speed and scalability for demanding workloads.
- Easy Migration: S3-compatible APIs allow seamless integration with existing systems without disrupting workflows.
Decentralized storage combines security, affordability, and scalability, making it a strong choice for enterprises managing today’s massive data growth.
EEA Education Call: How Decentralized Storage Works & How It Will be Used in Business and Commerce
sbb-itb-59e1987
Distributed Architecture and Data Resilience
Decentralized storage swaps the traditional single-server setup for a peer-to-peer network spread across various locations. Instead of keeping your entire file in one data center, the system breaks it into smaller pieces, called shards, and distributes them across multiple nodes. This design ensures no single node holds the complete file, reducing the risk of losing data due to hardware failures or service outages.
To add another layer of protection, erasure coding comes into play. This method splits files into redundant fragments, making it possible to recover data even if some nodes go offline. For instance, platforms like Storj monitor these fragments continuously. If the availability of fragments drops too low, the system automatically repairs and redistributes them. By spreading data across multiple nodes, this system creates a fault-tolerant and secure storage network.
"Decentralized storage systems consist of a peer-to-peer network of user-operators who hold a portion of the overall data, creating a resilient file storage sharing system." – ethereum.org
Eliminating Single Points of Failure
Centralized storage systems have a major flaw: if the provider’s server crashes or a data center experiences downtime, your data could become inaccessible. Decentralized systems solve this problem by scattering data fragments across hundreds – or even thousands – of nodes worldwide. This setup ensures data can be retrieved from any active node in the network, avoiding slowdowns during high traffic or regional disruptions. With shards stored in multiple locations, the risk of a single point of failure is effectively removed.
Blockchain for Trustless Coordination
Decentralized storage doesn’t just rely on redundancy – it also uses blockchain technology for coordination. This often involves sewa server masternodes to maintain network stability and security. Through cryptographic challenges and on-chain hash storage, blockchain ensures nodes are holding and managing data correctly, creating a trustless system. Nodes are regularly tested, and those that fail these tests face penalties or lose their rewards.
"The audit service is a highly scalable and performant analog to the consensus mechanism, typically a distributed ledger, used in other decentralized storage services." – Storj Docs
Some advanced systems now employ two-dimensional erasure coding, enabling self-healing recovery. This means new nodes can restore missing data using bandwidth proportional to what’s lost. By handling node turnover efficiently, these networks maintain data integrity and ensure operations continue smoothly, even when nodes leave or fail.
Cost Efficiency and Zero Egress Fees
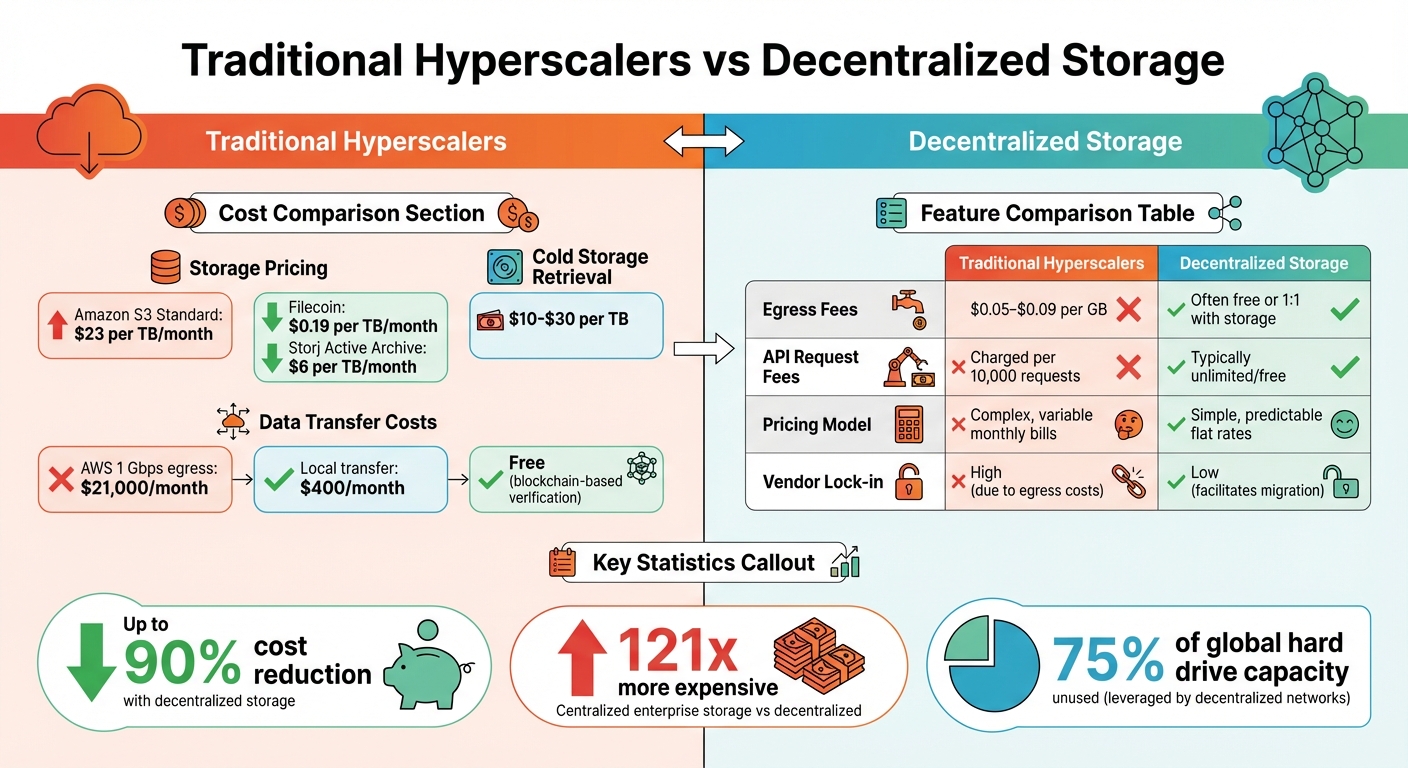
Decentralized vs Traditional Cloud Storage: Cost and Feature Comparison
Traditional cloud providers often rely on "data gravity" to keep customers locked in. The concept is simple: once your data is stored with them, moving it elsewhere becomes prohibitively expensive due to high egress fees. Christine Ackley from Storj puts it bluntly: "Fundamentally, these are exorbitant cloud computing taxes disguised as egress bandwidth fees." To put it in perspective, transferring just 1 Gbps of data out of AWS can cost around $21,000 per month, compared to about $400 per month for local transfers. These hefty fees push enterprises to search for storage solutions that reduce both obvious and hidden costs.
Decentralized storage offers a refreshing alternative by utilizing the 75% of global hard drive capacity that typically goes unused. Instead of building massive, energy-hungry data centers and passing those costs onto customers, decentralized networks leverage existing unused storage at the edge. This model isn’t just more efficient – it can slash costs by up to 90% compared to traditional hyperscalers. In fact, some centralized enterprise-grade virtual private servers can be as much as 121 times more expensive than decentralized options.
Reducing Operational Costs
The cost savings become even clearer when you compare actual pricing. For example, Amazon S3 Standard storage costs roughly $23 per TB per month, while decentralized options like Filecoin start at $0.19 per TB, and Storj’s Active Archive tier provides instantly accessible storage for just $6 per TB per month. For enterprises managing terabytes – or even petabytes – of data, these savings quickly add up, especially as global data is expected to hit 221,000 exabytes by 2026.
Centralized storage providers often inflate costs with additional retrieval and API fees. For companies that need to verify archive integrity annually (a common compliance requirement), these fees can add up fast. Traditional cold storage retrieval fees range from $10 to $30 per TB, making such maintenance costly. Decentralized storage networks sidestep this issue by using blockchain-based automated challenges to continuously verify data integrity – without extra charges.
Avoiding Egress and Hidden Charges
Beyond lower base costs, decentralized storage eliminates many hidden fees that traditional providers sneak into their pricing. For example, platforms like Züs offer free egress and unlimited API requests, while Storj includes a 1:1 ratio of storage to free data transfer in their Global and Regional tiers. This straightforward pricing model removes the unpleasant surprises common with centralized cloud services.
Here’s a quick breakdown of how decentralized storage compares to traditional hyperscalers:
| Feature | Traditional Hyperscalers | Decentralized Storage |
|---|---|---|
| Egress Fees | $0.05–$0.09 per GB | Often free or 1X storage volume included |
| API Request Fees | Charged per 10,000 requests | Typically unlimited/free |
| Pricing Model | Complex, variable monthly bills | Simple, predictable flat rates |
| Vendor Lock-in | High (due to egress costs) | Low (facilitates migration) |
For data-heavy tasks like AI training, big data analytics, or IoT, where frequent data access and updates are the norm, the absence of egress fees is a game-changer. Decentralized storage not only keeps costs under control but also allows businesses to remain flexible, enabling them to move data freely as their needs evolve – without being trapped in costly, restrictive systems.
Security and Data Encryption
When businesses shift to decentralized storage, ensuring security becomes a top priority – especially since data is spread across thousands of nodes. Decentralized systems are built to operate with untrusted nodes, which drives the need for stronger security measures compared to centralized systems.
A cornerstone of this security model is client-side encryption. With this approach, your data is encrypted on your device before it leaves your network. This ensures that the provider cannot access your unencrypted data or encryption keys. The result? End-to-end protection that safeguards your data during upload (in transit), while stored across distributed nodes (at rest), and during download. Encryption methods like AES-256-GCM or Secretbox (Salsa20 and Poly1305) are commonly used, providing confidentiality and tamper detection. If someone alters the encrypted data, your client will catch it during decryption.
Decentralized networks also use hierarchical key derivation to further boost security. This method creates unique keys for each data segment from a Root Secret, meaning a breach in one segment won’t compromise others. Additionally, file paths and metadata are encrypted on your device, preventing attackers from learning anything about your data structure.
This layered approach ensures robust security at every stage – whether your data is in transit, at rest, or undergoing audits.
Encryption at Rest and In Transit
In traditional systems, encryption keys are typically managed server-side, giving providers control over them. Decentralized storage flips this model, putting you in charge of your encryption keys. This zero-knowledge setup ensures that even if a storage node is compromised, attackers only gain access to encrypted data fragments, which are useless without the keys.
The encryption process is multi-layered. First, your data is encrypted and then broken into smaller fragments for redundancy and recovery. These encrypted fragments are distributed across thousands of nodes worldwide. Since no single node stores a complete file or has the decryption keys, reconstructing your data without authorization becomes nearly impossible. Security is further reinforced through Access Grants – client-managed security envelopes containing restricted API keys and path-based encryption keys. These grants allow you to enforce precise access controls without exposing your directory structure or root secret.
Immutable Audit Logs and Data Verification
To maintain data integrity, decentralized systems rely on continuous cryptographic audits. File Audits regularly check random data pieces to confirm they’re retrievable from storage nodes, functioning similarly to consensus mechanisms. When you download your data, authenticated encryption algorithms verify that it hasn’t been tampered with. If the number of available data pieces drops below a critical level, the system automatically repairs and redistributes data to maintain durability.
Ransomware Defense with Object Lock
Ransomware attacks remain a serious threat, but decentralized storage offers strong defenses. Features like S3-compatible Object Lock ensure data immutability by preventing designated files from being overwritten or deleted until a set retention period ends. This approach, backed by industry certifications, makes it an ideal solution for backup protection.
Pairing Object Lock with object versioning adds another layer of defense. If ransomware encrypts your latest files or if important data is accidentally deleted, you can easily recover earlier versions. The distributed nature of decentralized storage further strengthens protection. Encrypted fragments are spread across thousands of nodes, meaning an attacker would need to breach multiple nodes and obtain your client-side encryption keys – an almost impossible task. This makes decentralized storage far more resilient to ransomware and targeted attacks than centralized systems.
These comprehensive security measures, combined with enterprise-grade decentralized strategies, deliver a strong shield for your data.
| Feature | Traditional Centralized Storage | Enterprise-Grade Decentralized Storage |
|---|---|---|
| Encryption Key Ownership | Managed by the provider (server-side) | Controlled by the client (zero-knowledge) |
| Data Distribution | Stored in central data centers | Split into encrypted fragments and distributed globally |
| Tamper Detection | Relies on provider logs | Verified cryptographically during decryption |
| Ransomware Defense | Focused on perimeter security and backups | Uses Immutable Object Lock and decentralized redundancy |
Regulatory Compliance and Data Sovereignty
Decentralized storage makes navigating regulations like GDPR and CCPA much easier. Its design gives you direct control over where your data is stored and who can access it. This level of control can be a game-changer for enterprises, boosting confidence in their operations. Plus, it builds on the transparency and security features already baked into decentralized storage, as previously discussed.
Another big advantage comes from its blockchain foundation: tamper-proof audit trails. Every action – whether it’s a data transaction, an access request, or a modification – is recorded on an unchangeable ledger. This creates clear, verifiable evidence for audits. It also supports compliance with rules like the "right to erasure", allowing you to manage permissions and delete data fragments across the network without needing a central authority.
Data residency requirements are becoming stricter. Non-compliance with GDPR, for instance, can lead to fines as high as €20 million or 4% of global revenue. By 2024, global fines have already surpassed $1.2 billion. Countries such as India, Indonesia, Vietnam, and Saudi Arabia are also enforcing local data storage mandates. Decentralized networks help you meet these obligations by letting you choose storage nodes based on location, ensuring data stays within required jurisdictions like the EU.
Jurisdictional Data Residency
Decentralized storage platforms use tools like host filtering and selection to comply with location-specific data residency laws. This means you can select storage providers based on their geographic location, along with factors like cost and reliability. Techniques like geo-fencing ensure data doesn’t leave authorized regions.
Encryption keys also stay within their designated locations. For example, EU-based keys remain within the EU. Smart routing and geo-IP detection further enhance compliance by directing authentication and storage requests to the appropriate regional cluster based on the user’s location. For sensitive data, a hybrid approach can be used: personally identifiable information (PII) is stored in regional points-of-presence, while non-sensitive processes remain centralized. However, this comes with added costs – deploying in three regions is about 3.2 times the cost of a single-region setup, and five regions can cost roughly 5.8 times more.
Immutable Retention Policies
Compliance-heavy industries like healthcare, finance, and legal services often require data retention policies that ensure information cannot be altered or deleted prematurely. Decentralized storage enforces these rules at the protocol level. Once data is distributed across nodes, any modification becomes detectable.
Smart contracts further streamline compliance by automating workflows for consent management, data requests, and enforcing data minimization principles. Features like version control allow you to retrieve historical data and manage different file versions, which is crucial during regulatory audits. As Züs Network highlights:
"Every transaction and access request is recorded in a tamper-proof manner on the blockchain, enabling auditors and stakeholders to trace the history of data interactions."
These blockchain-backed records provide the traceability that regulations like GDPR require. Meanwhile, regular cryptographic checks ensure that data fragments remain intact and unaltered over time. Together, these compliance tools strengthen the case for decentralized storage, adding to its cost efficiency and security benefits for enterprises.
Performance and Scalability
Decentralized storage doesn’t just bring security and cost advantages – it also delivers performance and scalability that can meet the needs of high-demand enterprise applications. Its unique architecture transforms how data moves through a network, offering speeds and scalability that traditional centralized systems often can’t match.
Low Latency and High Throughput
One of the standout features of decentralized storage is its ability to deliver high-speed performance through parallel data retrieval. Instead of relying on a single server to fetch an entire file, the system divides files into smaller fragments (or shards) and distributes them across multiple nodes. When you request a file, these fragments are pulled simultaneously from different nodes, speeding up the process. As Kanga University explains, this method of downloading from multiple sources significantly accelerates file retrieval.
Geographic proximity plays a key role in reducing latency. Data nodes are selected based on their closeness to the user, ensuring that information is transmitted from nearby, high-quality sources. Additionally, dynamic load balancing continuously optimizes node selection based on real-time network conditions.
For frequently accessed data, edge caching provides an extra boost. Decentralized data acceleration layers can achieve sub-millisecond latency per query and handle up to 3,000 queries per second on a single thread. In contrast, traditional cloud storage solutions often experience latencies ranging from hundreds of milliseconds to several seconds when dealing with petabyte-scale data. By layering distributed caching on top of hyperscale data lakes, some organizations have reported performance gains of up to 1,000x compared to querying Parquet files stored on conventional cloud object storage like AWS S3 Standard. For AI and machine learning workloads, decentralized caching has also enhanced GPU utilization by 20%, optimizing overall system efficiency.
This high-speed, low-latency architecture lays the foundation for scalability in enterprise environments.
Scalability for Enterprise Workloads
Decentralized storage systems are designed to scale seamlessly to meet enterprise-level demands. Instead of relying on massive data centers, these systems use contract-based persistence with specific nodes, enabling them to handle enormous data volumes – potentially reaching zettabyte levels and beyond.
The use of erasure coding and fragmentation is central to this scalability. Files are split into smaller pieces and distributed across a global network, allowing for parallel data retrieval and increased throughput. By tapping into underutilized edge storage, these networks grow organically as more nodes join, further enhancing their ability to scale. For context, the Ethereum blockchain is about 500 GB to 1 TB in size; if enterprise-scale data were managed similarly, standard blockchain masternodes wouldn’t be able to operate effectively.
To maintain performance during peak usage, decentralized storage systems avoid traditional blockchain constraints like global consensus. Users can retrieve their files without syncing the entire network, thanks to coordination avoidance. Network partitioning isolates users and file transfers, preventing traffic spikes from one organization from affecting others. For enterprises with extreme throughput needs, running dedicated metadata management nodes allows them to bypass public coordination bottlenecks and fine-tune their infrastructure for optimal performance.
This architecture makes decentralized storage a strong fit for dynamic enterprise applications, whether it’s supporting AI/ML workloads or managing large-scale backup systems.
API Compatibility and Migration Ease
API compatibility plays a key role in ensuring a smooth transition when moving from traditional cloud storage to decentralized infrastructure. The good news? You don’t need to overhaul your entire application stack. With S3-compatible APIs, enterprises can switch providers without disrupting existing workflows.
S3-Compatible APIs for Easy Integration
Amazon S3 has set the standard for object storage APIs, and most enterprise applications are built around it. Decentralized storage platforms take advantage of this by offering full S3 compatibility, making them a seamless drop-in replacement for traditional providers.
What does this mean in practice? Migrating is as simple as updating your endpoint URL and access credentials. As Bill Thorp from Storj puts it:
"By making a cloud object storage system compatible with these APIs, it makes it much easier for users to migrate to new services without much effort."
For example, using the AWS CLI, you’d just point the --endpoint-url to a decentralized gateway like https://gateway.storjshare.io and input the new credentials. That’s it – your tools and workflows stay the same.
This compatibility isn’t limited to basic functionality. Decentralized gateways support standard S3 features like buckets, keys, HTTP verbs (GET, PUT, HEAD), multipart uploads, object versioning, and even object lock functionality. Popular third-party tools like Rclone, FileZilla, Restic, and the AWS CLI work without changes. Even automation scripts using the Python SDK (boto3) are supported up to version 1.35.99, ensuring a seamless transition.
Minimizing Migration Challenges
Migration doesn’t have to be a headache. Storj’s documentation highlights how straightforward the process can be:
"All you have to do is point files to the new buckets and migrate any static data you’d like to keep."
There’s no need to redesign your data management systems or train teams on unfamiliar interfaces. Enterprises can choose between hosted S3-compatible gateways for cloud-native applications or self-hosted gateways for hybrid or on-premise setups requiring end-to-end encryption. Both options maintain parity with traditional S3 features, including support for up to 10,000 parts per multipart upload and no cap on total object size. For files exceeding 5 TB, a simple adjustment to your S3 client’s multipart_chunksize setting ensures smooth handling.
The benefits go beyond compatibility. Customers with limited bandwidth often experience over 3x faster access speeds compared to centralized providers. And the cost savings are hard to ignore: storage costs can drop to $4.00 per TB per month, with egress fees around $7.00 per TB – up to 80% lower than conventional cloud storage. For enterprises with data residency requirements, S3 "LocationConstraint" parameters allow you to specify storage regions, such as regional-1 for US-only data or global-1 for worldwide availability.
Blockchain-Based Transparency and Verification
Blockchain technology builds on secure encryption and audit mechanisms, adding an unchangeable layer of transparency. It ensures accountability through on-chain, immutable records. Instead of relying on a single provider, enterprises can verify data integrity using cryptographic proofs stored on the blockchain. This creates a permanent, time-stamped audit trail that cannot be altered.
Transparent and Verifiable Storage
Blockchain-based storage systems ensure data security through protocols like Proof of Data Possession (PDP) and Proof-of-Replication (PoRep). These protocols verify that storage providers actually possess the data they claim to store. As explained in Filecoin’s documentation:
"Proof of Data Possession (PDP) is a cryptographic protocol that allows a client or smart contract to verify that a storage provider still holds a data set, without downloading it again."
The process works through randomized challenge-response mechanisms. Providers must answer these challenges correctly to confirm data integrity in real time. Data is structured into Merkle trees, and providers submit inclusion proofs to the blockchain. Smart contracts then verify these proofs automatically, ensuring the stored data remains unaltered. These features, combined with blockchain’s economic incentives, improve data resilience and cost efficiency – qualities that are essential for modern enterprises.
Beyond secure record-keeping, blockchain also enhances network reliability using token-based incentives.
Incentivized Data Replication
Blockchain networks create algorithmic marketplaces where storage providers earn native tokens for offering reliable storage. Unlike traditional cryptocurrency mining, which focuses on maintaining blockchain consensus, this model rewards providers based on the useful storage they supply. Protocol Labs describes this system as:
"The protocol weaves these amassed resources into a self-healing storage network that anybody in the world can rely on."
To ensure reliability, these systems conduct automated audits and enforce economic penalties. For example, Filecoin’s WindowPoSt protocol requires proof of sector availability every 30 minutes. Providers who fail to meet these proofs lose their pledged collateral, and their storage power is reduced. If data redundancy drops below a safe threshold, the network automatically triggers data repair mechanisms. This ensures that your data remains accessible, even if individual nodes experience failure.
Wrapping It Up
Choosing the right storage solution has never been more critical, considering the demands of performance, cost management, security, compliance, and scalability. As Stefaan Vervaet from Akave aptly states:
"The architecture you choose in 2026 will either give you proof, predictability, and control. Or leave you exposed."
For organizations with strict sovereignty requirements, relying on cryptographic proof of data residency is a must – contractual assurances alone won’t cut it. By 2028, 60% of such organizations are expected to transition to new cloud environments to mitigate extraterritorial risks. To simplify migration and maintain predictable AI economics as workloads grow, focus on solutions with S3-compatible APIs and zero egress fees.
Security cannot be compromised. Look for features like client-side encryption, erasure coding across distributed nodes, and immutable audit logs backed by blockchain verification. With cyberattacks increasingly exploiting stolen credentials, eliminating single points of failure is vital to safeguarding your data. Additionally, as autonomous AI agents become prevalent in many G2000 roles by 2026, your system must handle machine-scale read/write demands seamlessly.
Before making a final decision, validate performance in a real-world setting. Run a one-week pilot using identical datasets across at least two solutions. Test for durability, latency, and costs to ensure they align with your budget and operational needs. Match your persistence model to your data’s lifecycle, whether it’s one-time fees for permanent archives, market-priced contracts for large-scale verifiable storage, or pinned replicas for content distribution.
As the global datasphere approaches an astounding 221,000 exabytes by 2026, decentralized storage – with its distributed, secure, and scalable architecture – emerges as a key strategy for enterprises managing this unprecedented data explosion. Your choices today will shape your ability to scale and adapt tomorrow.
FAQs
How does decentralized storage enhance data security compared to traditional centralized systems?
Decentralized storage boosts data security by distributing information across numerous geographically dispersed nodes. This setup minimizes the chances of a single point of failure, making it harder for cyberattacks, ransomware, or data breaches to compromise the system.
On top of that, many decentralized storage platforms use advanced encryption and layered security measures. These safeguards ensure that only authorized individuals can access the stored data. For businesses, this means stronger control over sensitive information while keeping privacy well-protected.
What are the cost advantages of decentralized storage for enterprises?
Decentralized storage offers a clear financial edge for businesses, primarily because it’s significantly cheaper than traditional centralized options. For instance, the average cost of decentralized storage is around $2.11 per terabyte (TB) per month, while centralized providers often charge $9.88 or more for the same amount. For companies with extensive storage needs, this price gap can translate into major cost reductions.
What’s more, decentralized storage does away with hidden fees like egress charges and avoids the restrictive contracts that many centralized providers impose. This makes it a flexible and budget-friendly choice for enterprises aiming to streamline their data management costs without compromising on scalability or security.
How does decentralized storage help meet global data privacy and security regulations?
Decentralized storage helps businesses stay compliant with global data regulations by using a distributed setup that boosts data privacy, security, and control. Instead of relying on a single location, data is stored across multiple nodes in various regions. This reduces the chance of single points of failure and limits the risk of unauthorized access. It also allows businesses to store data in specific regions to meet legal requirements like GDPR or data localization laws.
Many decentralized storage systems also incorporate advanced encryption techniques, such as end-to-end encryption, ensuring that sensitive information is accessible only to authorized users. On top of that, these systems often include transparent audit trails, which let organizations monitor data access and changes – an essential feature for regulatory compliance. By combining strong security measures, clear tracking, and regional flexibility, decentralized storage simplifies the process of meeting international data protection standards.




