
Ultieme gids voor prestaties op het gebied van load balancing in meerdere clouds
Load balancing tussen meerdere clouds zorgt ervoor dat uw applicaties snel, betrouwbaar en toegankelijk blijven door het verkeer te verdelen over meerdere cloudproviders en virtuele privéservers zoals AWS, Azure en Google Cloud. Deze aanpak verbetert de prestaties, minimaliseert downtime en verwerkt verkeerspieken naadloos. In tegenstelling tot oplossingen voor één cloud, werken load balancers voor meerdere clouds wereldwijd en maken ze gebruik van softwaregedefinieerde systemen voor flexibiliteit en schaalbaarheid.
Belangrijkste punten:
- Wereldwijde verkeersverdeling: Leidt gebruikers door naar de dichtstbijzijnde of meest operationele serverpool met behulp van Global Server Load Balancing (GSLB).
- Verminderde latentieSlimme routering verlaagt de latentie aanzienlijk, bijvoorbeeld van 230 ms naar 123 ms voor een Duitse gebruiker die toegang probeert te krijgen tot een Amerikaanse server.
- FailovermechanismenGeautomatiseerde gezondheidscontroles en verkeersisolatie voorkomen domino-effecten tijdens stroomuitval.
- VerkeersrouteringsmethodenDit omvat op latentie gebaseerde, geografische, op belasting gebaseerde en op gezondheid gebaseerde benaderingen.
- BeveiligingFuncties zoals Anycast, DDoS-bescherming en SSL/TLS-offloading beveiligen het verkeer.
Load balancing over meerdere clouds is cruciaal voor moderne IT-omgevingen en zorgt voor hoge beschikbaarheid en optimale prestaties van gedistribueerde systemen. Hieronder gaan we dieper in op de architectuur, uitdagingen en best practices voor de implementatie ervan.
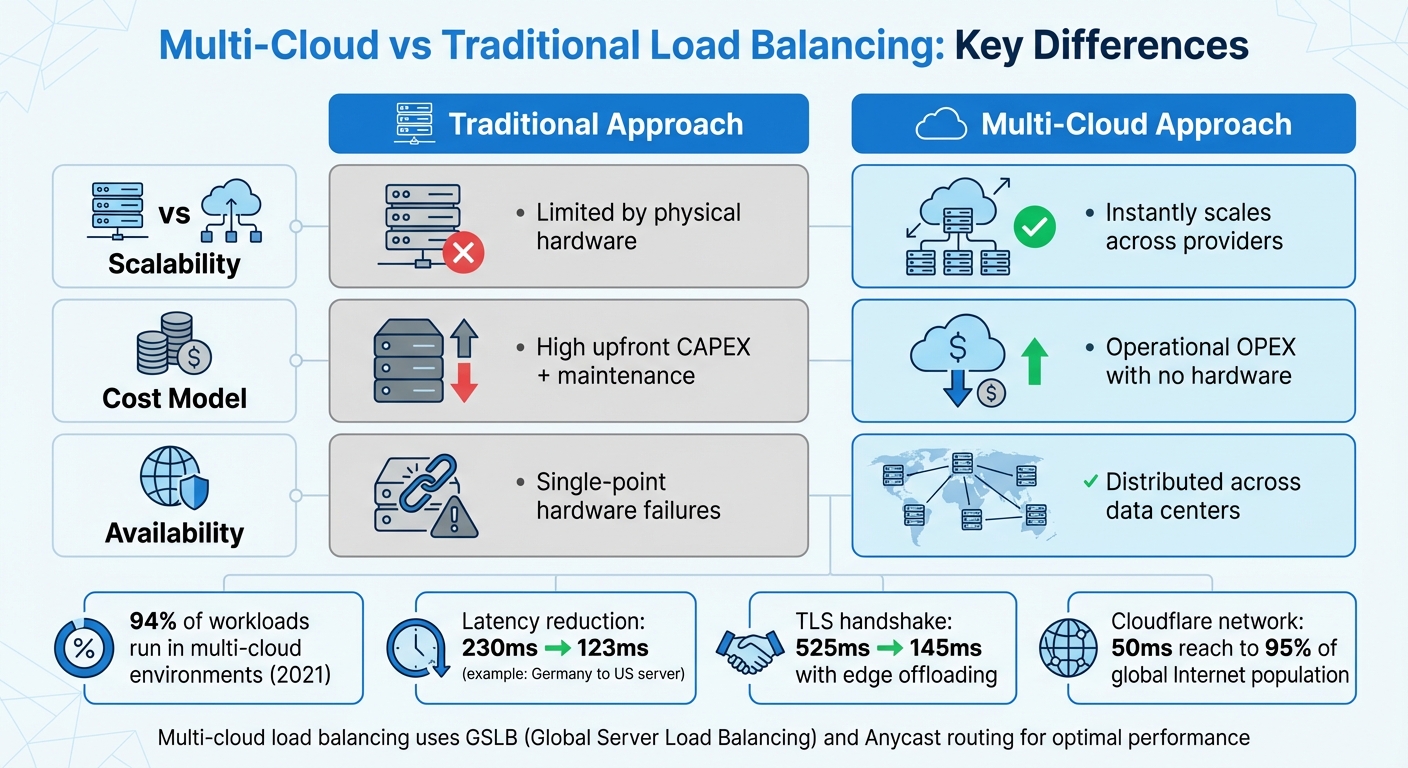
Multicloud versus traditionele loadbalancing: belangrijkste verschillen
Maak uw load balancing-strategie toekomstbestendig voor gebruik in multi-cloud en hybride cloudomgevingen.
sbb-itb-59e1987
Multi-cloud load balancing architectuur
Multicloud-configuraties zijn afhankelijk van Globale serverbelastingverdeling (GSLB) om het verkeer te verdelen over virtuele serverpools Gehost door verschillende cloudproviders in diverse regio's. In tegenstelling tot traditionele hardwaregebaseerde systemen die gebonden zijn aan één datacenter, werkt GSLB onafhankelijk van specifieke infrastructuren, waardoor het ideaal is voor omgevingen die verspreid zijn over platforms zoals AWS, Azure en Google Cloud.
De kern van deze architectuur wordt gevormd door een wereldwijde transitlaag die centraal netwerkbeleid, routering en beveiliging beheert. Geïntegreerde statuscontroles bewaken de prestaties en activeren geautomatiseerde failovers wanneer nodig. Samen zorgen deze elementen – wereldwijde load balancing, routeringsconfiguraties en failovermechanismen – voor de betrouwbaarheid van multi-cloudsystemen.
Globale loadbalancers en Anycast
Globale load balancers fungeren als "load balancers van load balancers" en leiden verkeer naar regionale diensten op basis van factoren zoals status, capaciteit en nabijheid. Een belangrijk onderdeel van dit systeem is Anycast-routering, Dit maakt gebruik van één enkel IP-adres dat vanuit meerdere geografische locaties wordt geadverteerd via het Border Gateway Protocol (BGP). Wanneer gebruikers verbinding maken, routeert BGP hun verkeer naar het dichtstbijzijnde datacenter op basis van de netwerktopologie.
""Anycast werkt in principe als volgt: gebruikersverkeer wordt naar het dichtstbijzijnde datacenter geleid dat het voorvoegsel adverteert waarmee de gebruiker verbinding probeert te maken, zoals bepaald door het Border Gateway Protocol." – David Tuber, Cloudflare
Met Anycast kan een statisch globaal IP-adres verkeer direct omleiden naar het dichtstbijzijnde, goed functionerende datacenter. Als een datacenter problemen ondervindt, zorgt het intrekken van een BGP-route ervoor dat het verkeer automatisch wordt omgeleid naar de eerstvolgende locatie. Google Cloud gebruikt deze methode bijvoorbeeld op meer dan 80 edge-locaties, met behulp van een 'Waterfall by Region'-algoritme dat rekening houdt met nabijheid, belasting en capaciteit om de verkeersstroom te optimaliseren.
Een voorbeeld hiervan in de praktijk deed zich voor in augustus 2023, toen het datacenter van Cloudflare in Ashburn, Virginia (IAD02) te kampen kreeg met hardwareproblemen. Hun "Duomog"-systeem verplaatste het verkeer naadloos naar acht andere, goed functionerende subsecties binnen de regio, waardoor de uptime van 100% behouden bleef zonder handmatige tussenkomst. Dit laat zien hoe op Anycast gebaseerde systemen in realtime kunnen reageren op storingen, en daarmee de snelheid van traditionele DNS-failovermethoden ruimschoots overtreffen.
Actief-actief versus actief-passief configuraties
Multicloudsystemen maken vaak gebruik van actieve-actieve of actieve-passieve configuraties, elk met zijn eigen sterke punten.
- Actieve-actieve configuratiesIn deze configuratie verwerken alle regio's gelijktijdig live verkeer, waardoor de resources optimaal worden benut en de responstijden verbeteren. Deze aanpak is ideaal voor systemen die prioriteit geven aan prestaties en redundantie.
- Actieve-passieve configuratiesHier wordt het verkeer naar een primaire actieve pool geleid, met een secundaire passieve pool in standby-modus voor failover. Hoewel deze configuratie kan leiden tot tragere failovers en onderbenutte standby-bronnen, vereenvoudigt het het beheer en verlaagt het de operationele kosten.
Big Cartel gebruikt bijvoorbeeld een actief-passieve strategie. Hun CDN, Fastly, haalt data uit Backblaze B2 als primaire bron, waarbij Amazon S3 fungeert als geautomatiseerde failover-bestemming. Dit garandeert een ononderbroken dienstverlening tijdens storingen en houdt de kosten beheersbaar.
Deze configuraties, in combinatie met intelligente failover-mechanismen, versterken de systeemveerkracht verder.
Failovermechanismen tussen clouds
Effectieve failoverstrategieën zijn afhankelijk van realtime monitoring van de systeemstatus en geautomatiseerde capaciteitsaanpassingen. Deze mechanismen zorgen ervoor dat verkeer alleen naar functionerende eindpunten wordt geleid, waardoor de prestaties behouden blijven en de latentie tijdens storingen tot een minimum wordt beperkt.
Sommige systemen gaan nog een stap verder door Traffic Predictors te gebruiken om potentiële problemen te voorspellen en failover-beleid vooraf te configureren. Cloudflare simuleerde bijvoorbeeld een regionale storing door ping-verzoeken naar honderdduizenden IP-adressen te sturen en BGP-verschuivingen te analyseren. Hun systeem voorspelde dat 99,81 TP3T aan verkeer succesvol zou worden omgeleid naar Auckland, waardoor technici preventief beleid konden aanpassen en konden voorkomen dat verkeerspieken de back-uplocaties zouden overbelasten.
Failovers tussen verschillende cloudproviders worden georkestreerd met behulp van platformonafhankelijke tools zoals Terraform of Pulumi. Deze automatiseringsframeworks verzorgen het failoverproces naadloos, waardoor verkeer zonder handmatige tussenkomst of DNS-updates naar gezonde alternatieven wordt overgeschakeld. Dit niveau van automatisering zorgt ervoor dat multi-cloudsystemen betrouwbaar en efficiënt blijven, zelfs tijdens onverwachte storingen.
Verkeersrouterings- en distributiemethoden
Nadat je je multi-cloudarchitectuur hebt opgezet, is de volgende stap het bepalen van de verkeersroutering. De gekozen routeringsmethode heeft direct invloed op de gebruikerservaring, de serverprestaties en de algehele systeemefficiëntie.
Op latentie gebaseerde en geografische routering
Routering op basis van latentie Dit zorgt ervoor dat gebruikers worden doorverwezen naar het datacenter met de laagste round-trip time (RTT). Door de netwerklatentie tussen IP-adressen van gebruikers en beschikbare eindpunten te meten, streeft deze methode ernaar de snelst mogelijke reactietijden te bieden. Het is een populaire keuze voor applicaties waar snelheid cruciaal is, zoals financiële handelsplatformen of realtime gaming.
Geografische routeplanning, Geografische routering daarentegen richt zich op de fysieke locatie van de gebruiker. Het routeert verkeer naar het dichtstbijzijnde punt van aanwezigheid op basis van de oorsprong van de DNS-query. In tegenstelling tot routering op basis van latentie, die de netwerkprestaties meet, geeft geografische routering prioriteit aan nabijheid. Deze methode is met name nuttig voor het voldoen aan vereisten voor gegevenssoevereiniteit of het leveren van content die is afgestemd op specifieke regio's.
Om de vertragingen verder te beperken, randafsluiting speelt een cruciale rol. Door TCP- en SSL/TLS-verbindingen aan de netwerkrand af te handelen, worden de verbindingstijden aanzienlijk verkort. Google Cloud meldt bijvoorbeeld dat het gebruik van een externe Application Load Balancer de waargenomen latentie voor een gebruiker in Duitsland die toegang heeft tot een server in de VS kan verlagen van 230 ms naar 123 ms. Op vergelijkbare wijze verlaagt het afhandelen van SSL aan de netwerkrand de TLS-handshakelatentie van 525 ms naar 201 ms – en zelfs naar 145 ms met HTTP/2.
""De externe Application Load Balancer vermindert de extra latentie voor een TLS-handshake aanzienlijk (doorgaans 1-2 extra roundtrips). Dit komt doordat de externe Application Load Balancer SSL-offloading gebruikt, waardoor alleen de latentie naar het edge PoP relevant is." – Google Cloud-documentatie
Bij het implementeren van routering op basis van latentie of geografische routering is het cruciaal om een fallback-eindpunt (vaak "World" genoemd) te configureren om verkeer van niet-toegewezen IP-bereiken af te handelen. Zonder dit vangnet zouden verzoeken van onverwachte locaties volledig kunnen worden geweigerd.
Hoewel op nabijheid gebaseerde methoden de responstijden verbeteren, pakken ze de serverbelasting niet aan. Dat is waar dynamische routering op basis van belasting en serverstatus van pas komt.
Load-Aware en Health-Based Routing
Bij het nemen van routeringsbeslissingen moet ook rekening worden gehouden met de capaciteit en de status van de servers. Load-aware routing Het systeem maakt gebruik van realtime statistieken om het verkeer intelligent te verdelen. Zo stuurt het algoritme "Minste verbindingen" het verkeer naar de server met de minste actieve verbindingen, terwijl "Minste responstijd" de server kiest met de snelste historische prestaties.
Routeplanning op basis van gezondheid Dit zorgt ervoor dat verkeer alleen naar operationele servers gaat. Geautomatiseerde gezondheidscontroles bewaken de beschikbaarheid van eindpunten en als een server uitvalt, stopt de load balancer met het doorsturen van verkeer ernaartoe. De standaard failover-drempel van Google Cloud is 70%, wat betekent dat als minder dan 70% aan eindpunten gezond zijn, het verkeer wordt omgeleid naar back-upservers. Meer geavanceerde configuraties gebruiken automatische capaciteitsafvoer, waarbij de capaciteit van een backend op nul wordt gezet als minder dan 25% van de instanties de gezondheidscontroles doorstaan.
Voor een nog grotere veerkracht maken sommige systemen gebruik van preventieve overloop. Als meer dan 50% aan backends in een regio niet in orde zijn, wordt het verkeer automatisch overgeplaatst naar de dichtstbijzijnde, wel functionerende regio, waardoor gebruikersonderbrekingen worden voorkomen.
In scenario's waarin de complexiteit van verzoeken varieert, kan het "Least Outstanding Requests"-algoritme effectiever zijn dan simpelweg het tellen van verbindingen. Deze aanpak houdt rekening met de verwerkingstijd van verzoeken, wat zorgt voor een betere verdeling van de belasting.
Routeringsbeslissingen op applicatielaagniveau
Naast routeplanning op transportniveau kunnen beslissingen op applicatieniveau het verkeersbeheer verder verfijnen. Layer 7-routering Het maakt gebruik van applicatiespecifieke gegevens – zoals HTTP-headers, URL's of cookies – om complexere routeringsbeslissingen te nemen. Deze aanpak maakt zeer gericht verkeersbeheer mogelijk.
""Layer-7 load balancers nemen routeringsbeslissingen... op basis van applicatiespecifieke gegevens. Dit omvat de inhoud van de datapakketten, HTTP-headers, URL's en cookies." – Tata Communications
Een veelvoorkomend kenmerk van de applicatielaag is sessie-affiniteit (of "sticky sessions"). Dit zorgt ervoor dat alle verzoeken van een gebruiker tijdens een sessie naar dezelfde backend-instantie worden gestuurd, wat essentieel is voor het behoud van gegevens zoals de inhoud van een winkelwagen of de inlogstatus. Hoewel sessie-affiniteit algoritmes die rekening houden met de belasting kan overrulen, is het noodzakelijk voor bepaalde applicatielogica.
Een ander krachtig hulpmiddel is gewogen routing, Dit verdeelt het verkeer op basis van toegewezen gewichten. Dit is vooral handig tijdens applicatie-upgrades of -migraties. U kunt bijvoorbeeld 90% aan verkeer naar een stabiele productieomgeving routeren, terwijl u een nieuwe versie test met de resterende 10%. Door een gewicht van nul toe te wijzen, kunnen servers bestaande verbindingen tijdens onderhoud geleidelijk afwikkelen zonder nieuwe aanvragen te verwerken. Azure Traffic Manager kan bijvoorbeeld routeringsbeleid binnen één minuut bijwerken, waardoor snelle aanpassingen mogelijk zijn zonder downtime.
Prestaties bewaken en optimaliseren
Nadat je routeringsstrategieën hebt ingesteld, is de volgende stap het nauwlettend in de gaten houden van de prestaties om ervoor te zorgen dat alles soepel verloopt in alle cloudomgevingen. Slimme routering is slechts een deel van de oplossing; continue monitoring helpt je knelpunten te identificeren en de maximale efficiëntie te behouden.
Realtime prestatiemetingen
Het bijhouden van realtime statistieken is essentieel om te begrijpen hoe uw systeem presteert. Enkele van de meest cruciale statistieken zijn: Beschikbaarheid van het gegevenspad en status van de gezondheidssonde, Deze statistieken controleren de netwerk- en serverprestaties. Azure Standard Load Balancer controleert deze statistieken bijvoorbeeld elke twee minuten. Als de beschikbaarheid van het datapad onder de 90% zakt (maar boven de 25% blijft), wordt de status 'Verslechterd' geactiveerd, wat wijst op mogelijke problemen.
Latentiemetingen Een ander belangrijk aandachtspunt zijn de latency-statistieken. Deze helpen om precies te bepalen waar vertragingen optreden. Totale latency meet de end-to-end responstijd, terwijl backend-latentie de verwerkingstijd van de server isoleert. Als de totale latency hoog is, maar de backend-latentie normaal blijft, ligt het probleem waarschijnlijk in het netwerk en niet in de applicatie zelf. Op Google Cloud worden deze statistieken elke 60 seconden gemeten, hoewel het 90 tot 210 seconden kan duren voordat de gegevens in dashboards verschijnen, afhankelijk van de statistiek.
Verkeers- en doorvoerstatistieken Ook spelen deze een cruciale rol. Denk hierbij aan het aantal verzoeken (verzoeken per minuut), het aantal bytes voor inkomende en uitgaande data, en actieve verbindingen. Een vaak over het hoofd geziene meetwaarde is... staartlatentie, met name het 99e percentiel (p99). Hoewel de gemiddelde latentie er prima uit kan zien, onthult de staartlatentie de ervaring van de traagste 1%-gebruikers en legt zo verborgen prestatieproblemen bloot. Deze realtime inzichten stellen u in staat snel aanpassingen te maken om optimale prestaties te behouden.
Configuratieaanpassingen op basis van verkeerspatronen
Met behulp van deze realtime meetgegevens kunt u dynamische aanpassingen maken aan de toewijzing van resources. Naast gangbare strategieën zoals 'Minste verbinding' of 'Korte responstijd', biedt een Waterval per regio Deze aanpak houdt rekening met factoren zoals nabijheid, belasting en capaciteit. Dit zorgt ervoor dat als een regio verzadigd raakt, het verkeer automatisch wordt doorgestuurd naar de dichtstbijzijnde regio met beschikbare resources.
Doelvolging schaalvergroting is een ander handig hulpmiddel. Door statistieken zoals het gemiddelde CPU-gebruik of het aantal aanvragen per doel te monitoren, kunnen automatische schaalbeleidsregels de capaciteit naar behoefte aanpassen. De sleutel is het selecteren van statistieken die stijgen naarmate de belasting toeneemt, waardoor extra resources worden toegevoegd om aan de vraag te voldoen.
Voor meer geavanceerde configuraties, preventieve overloop Verkeer kan worden omgeleid naar back-upregio's voordat de primaire regio volledig overbelast raakt. Als bijvoorbeeld uit gezondheidscontroles blijkt dat meer dan 501 TP3T aan backends niet in orde zijn, wordt het verkeer naar back-uplocaties verplaatst, zelfs als er nog capaciteit beschikbaar is in de primaire regio.
Om onnodige waarschuwingen te voorkomen, kunt u drempelwaarden instellen op basis van gemiddelden over periodes van vijf minuten in plaats van te reageren op korte pieken. Door bijvoorbeeld een waarschuwing in te stellen voor een beschikbaarheid van minder dan 95% gedurende vijf minuten, kunt u echte problemen opsporen zonder overweldigd te worden door valse alarmen.
Geautomatiseerde waarschuwingen en probleemoplossing
Geautomatiseerde waarschuwingen en reacties zijn essentieel voor het handhaven van een hoge beschikbaarheid in multi-cloudsystemen. Handmatige monitoring schiet in deze complexe omgevingen vaak tekort. Geautomatiseerde systemen combineren actieve probes met realtime verkeersanalyse om problemen vroegtijdig te detecteren. Passieve controles, zoals het monitoren van 5xx-fouten of verbindingstime-outs, sporen fouten op logicaniveau op die synthetische probes mogelijk missen.
""Loadbalancers worden automatisch voorzien van meetinstrumenten om informatie te leveren over verkeer, beschikbaarheid en latentie... daarom fungeren loadbalancers vaak als een uitstekende bron van SLI-statistieken zonder dat applicatie-instrumentatie nodig is." – Google Cloud
Wanneer er problemen optreden, geautomatiseerde verkeersafvoer Het verwijdert ongezonde backends uit de rotatie. Tegelijkertijd starten orchestratietools zoals Kubernetes of cloud-native autoscaling vervangende instanties op. Dit zelfherstellende proces zorgt ervoor dat uw systeem blijft draaien zonder menselijke tussenkomst.
Voor diepgaander inzicht in multi-cloudomgevingen bieden tools zoals Prometheus en Grafana platformonafhankelijke monitoring. Cloud-native oplossingen, zoals Google Cloud Monitoring, Azure Monitor Insights en Cloudflare Load Balancing Analytics, bieden aanvullende mogelijkheden. Veel organisaties stappen over op uniforme monitoring met OpenTelemetry, dat metrics, logs en traces van alle cloudproviders integreert in één samenhangend overzicht.
Beveiliging en compliance in multi-cloudomgevingen
Bij het beheren van load balancing in meerdere clouds is beveiliging net zo belangrijk als prestaties en betrouwbaarheid. Het gaat niet alleen om het beveiligen van verkeer, maar ook om het garanderen van consistente bescherming bij verschillende cloudproviders, met inachtneming van wettelijke normen. Elk cloudplatform heeft zijn eigen beveiligingsconfiguraties, die tot beveiligingslekken kunnen leiden als ze niet zorgvuldig worden beheerd. Deze beveiligingsmaatregelen werken samen met de reeds besproken dynamische routing- en failovermechanismen en vormen zo een alomvattende strategie voor meerdere clouds.
DDoS-bescherming en verkeersversleuteling
Anycast-technologie Anycast is een belangrijke verdediging tegen DDoS-aanvallen. In plaats van al het verkeer via één punt te leiden, maakt Anycast het mogelijk om hetzelfde IP-adres te adverteren in alle datacenters van uw netwerk. Dit verdeelt de belasting tijdens een aanval en voorkomt knelpunten. Het netwerk van Cloudflare opereert bijvoorbeeld binnen een straal van ongeveer 50 ms van 951 TP3T van de wereldwijde internetgebruikers, waardoor er voldoende capaciteit is om aanvallen op te vangen.
DDoS-aanvallen vallen doorgaans in twee categorieën: Layer 4-aanvallen, die zich richten op transportlagen zoals TCP/UDP-verbindingen, en Layer 7-aanvallen, die zich richten op applicatielagen zoals HTTP-verzoeken. Aanvallen op laag 7 zijn bijzonder lastig omdat ze legitiem verkeer nabootsen, waardoor ze moeilijker te detecteren zijn. Een robuuste load balancer moet beide typen aanvallen effectief kunnen afhandelen.
SSL/TLS-offloading Op load balancer-niveau wordt het encryptieproces vereenvoudigd. Het neemt het zware werk van encryptie en decryptie, evenals certificaatbeheer, voor zijn rekening. Zorg er echter voor dat uw compliance-eisen geen end-to-end encryptie tot aan de oorspronkelijke server vereisen.
Webapplicatiefirewalls en inbraakpreventie
A architectuur met één doorgang Dit is cruciaal voor het behoud van prestaties en tegelijkertijd het toevoegen van beveiliging. In plaats van verkeer via meerdere beveiligingsapparaten – zoals een WAF, IPS en DLP – te routeren, inspecteren moderne beveiligingsgateways het verkeer in één keer. Dit vermindert de latentie en verbetert de algehele doorvoer.
""Het grootste nadeel [van het stapelen van leveranciers] is het verlies van volledig inzicht in het verkeer wanneer je achter een andere leverancier zit, wat veel van Cloudflare's op dreigingsinformatie gebaseerde diensten belemmert, zoals botbeheer, snelheidsbeperking, DDoS-mitigatie en de IP-reputatiedatabase." – Cloudflare
Vermijd het stapelen van meerdere beveiligingslagen, omdat dit blinde vlekken kan creëren die de detectie van bedreigingen verzwakken. Een WAF met volledig inzicht in verkeerspatronen kan bots beter identificeren, misbruikmakende clients beperken en IP-reputatiedatabases effectief gebruiken. Randgebaseerde inspectie, Door het verkeer dichter bij de bron te filteren, worden zowel hoge prestaties als sterke beveiliging gegarandeerd.
Deze robuuste firewall- en inbraakpreventiemaatregelen dragen ook bij aan de naleving van industriestandaarden.
Naleving van regionale en branchenormen
Het naleven van normen zoals HIPAA, PCI DSS en SOC2 In een multi-cloudomgeving is zorgvuldig beheer van dataresidentie en verwerkingslocaties vereist. De stuurlaag van uw load balancer kan dit afdwingen. jurisdictionele routering, waarbij ervoor gezorgd wordt dat klantverzoeken worden afgehandeld door de infrastructuur binnen specifieke wettelijke kaders.
Gegevensclassificatie speelt een cruciale rol. Verdeel uw gegevens in categorieën zoals inhoud, operationele telemetrie en persoonsgegevens. Elke categorie moet duidelijke regels hebben voor verwerkingslocaties, bewaartermijnen en toegangsrechten. Persoonsgegevens (PII) moeten bijvoorbeeld mogelijk binnen een specifiek cloudaccount blijven, terwijl geaggregeerde telemetriegegevens vrijer kunnen worden verplaatst.
Lokale sleutelbewaring Zorgt ervoor dat encryptiesleutels binnen hun aangewezen rechtsgebieden blijven door gebruik te maken van regionale sleutelbeheersystemen (KMS). Wanneer de geografische locatie van de klant onduidelijk is, wordt standaard de strengste verblijfsregel toegepast.
Hulpmiddelen zoals Infrastructuur als code (Bijvoorbeeld Terraform) kan de implementatie van beveiligingsbeleid in verschillende clouds automatiseren. Dit zorgt ervoor dat WAF-regels, snelheidsbeperkingen en toegangscontroles consistent worden toegepast. Bewaar dataflowdiagrammen, processorlijsten en routeringsregels in versiebeheer voor collegiaal gecontroleerde audit trails, waardoor compliancecontroles en -verificaties worden vereenvoudigd.
Schaalbaarheid en resourcebeheer
Load balancing in meerdere clouds zorgt niet alleen voor een soepele werking van systemen, maar biedt ook flexibiliteit bij het schalen en helpt de kosten effectief te beheren. Door resources dynamisch aan te passen op basis van het verkeer, zorgt het ervoor dat applicaties responsief blijven tijdens piekuren en onnodige kosten tijdens rustigere perioden worden vermeden.
Beleid en triggers voor automatisch schalen
Op verkeer gebaseerde statistieken zijn essentieel voor snelle en efficiënte schaalvergroting. Het monitoren van verzoeken per seconde (RPS) stelt systemen bijvoorbeeld in staat om te reageren op pieken in de vraag voordat er prestatieproblemen ontstaan. Aan de andere kant kan het gebruik van CPU of geheugen trager zijn – tegen de tijd dat deze waarden pieken, merken gebruikers mogelijk al vertragingen.
Doelgerichte trackingbeleidsregels helpen om consistente prestaties te garanderen. Door bijvoorbeeld een doel van 70% CPU-gebruik in te stellen, zorgt u ervoor dat de autoscaler ingrijpt wanneer het gebruik dit niveau overschrijdt. Hierdoor worden er indien nodig resources toegevoegd en wordt er weer afgeschaald wanneer de vraag afneemt. De Gateway-resources van Google Cloud kunnen bijvoorbeeld tot 100.000.000 RPS aan, wat ruim voldoende capaciteit biedt voor scenario's met een hoge vraag.
Door de initialisatieperiodes voor nieuwe virtuele machines (VM's) correct in te stellen, wordt ervoor gezorgd dat ze niet te vroeg worden meegenomen in schaalbeslissingen. Daarnaast zorgt cross-regionale overloop ervoor dat verkeer tijdelijk wordt omgeleid totdat de lokale resources volledig online zijn. Deze strategieën helpen een balans te vinden tussen prestaties en kosten, terwijl de betrouwbaarheid behouden blijft.
Kostenoptimalisatie met dynamische toewijzing van middelen
Opschaling is slechts één onderdeel van de puzzel; efficiënte toewijzing van middelen is even belangrijk om de kosten laag te houden. Kostengebaseerde routing Dit zorgt ervoor dat verkeer wordt doorgestuurd naar regio's met de laagste leverings- of bandbreedtekosten, waardoor elke dollar die aan infrastructuur wordt besteed, optimaal wordt benut.
Het aanpassen van de autoscaling-triggers kan ook geld besparen. Door bijvoorbeeld een hogere drempelwaarde in te stellen, zoals 90% CPU-gebruik in plaats van 70%, wordt de noodzaak om kostbare ongebruikte capaciteit aan te houden verminderd. Regionale overloop fungeert als vangnet en leidt verkeer om naar andere clouds wanneer een regio zijn limiet bereikt. Deze aanpak verlaagt de kosten en levert tegelijkertijd een betrouwbare service.
| Functie | Traditionele aanpak | Multicloudbenadering |
|---|---|---|
| Schaalbaarheid | Beperkt door fysieke hardware | Schaalbaar over verschillende aanbieders. |
| Kostenmodel | Hoge investeringskosten vooraf + onderhoud | Operationele OPEX zonder hardware |
| Beschikbaarheid | Hardwarestoringen op één punt | Verdeeld over datacenters |
Failover-drempelwaarden verfijnen de balans tussen kosten en prestaties verder. Deze drempelwaarden, die doorgaans op 70% zijn ingesteld, bepalen wanneer verkeer naar back-upregio's wordt verplaatst. Door dit bereik aan te passen tussen 1% en 99% kunt u de mate van resourcegebruik nauwkeurig afstemmen op de behoeften van de werkbelasting.
Het verwerken van verkeerspieken in de cloud.
Het beheersen van plotselinge verkeerspieken vereist een slimme verdeling van de verkeersdrukte. Watervalalgoritmen Geef prioriteit aan het vullen van de regio die het dichtst bij de maximale capaciteit is, alvorens overtollige capaciteit door te sturen naar de eerstvolgende regio. Deze aanpak minimaliseert de latentie en voorkomt overbelasting van één enkele cloudprovider of datacenter.
Preventieve overloop is een andere beveiliging. Als meer dan 50% aan backends in een regio niet goed functioneren, wordt het verkeer omgeleid, zelfs als er nog capaciteit beschikbaar is. Dit voorkomt dat gebruikers naar gedeeltelijk defecte systemen worden geleid. De capaciteit wordt pas hersteld zodra ten minste 35% aan backend-instanties gedurende 60 seconden stabiel blijven, waardoor constant schakelen tussen actieve en inactieve statussen wordt voorkomen.
Verkeersisolatie Biedt extra controle. In de "strikte" isolatiemodus wordt verkeer geblokkeerd in plaats van omgeleid naar andere regio's. Dit is vooral handig voor latencygevoelige applicaties of gevallen waarin data binnen specifieke rechtsgebieden moet blijven om aan regelgeving te voldoen. Softwarematige loadbalancers die werken op platforms zoals AWS, Azure en Google Cloud maken dit niveau van flexibiliteit mogelijk en zorgen voor een soepele verkeersdistributie zonder hardwarebeperkingen.
Implementatie- en implementatiehandleiding
Het opzetten van load balancing in meerdere clouds vereist zorgvuldige planning en nauwkeurige uitvoering. Het proces omvat het verbinden van verschillende cloudomgevingen, het configureren van de verkeersstroom ertussen en het automatiseren van taken om handmatige fouten te minimaliseren.
Multicloud-integratie instellen
De eerste stap is het tot stand brengen van een veilige verbinding tussen cloudproviders en dedicated servers en on-premises infrastructuur. Dit wordt doorgaans gedaan met behulp van Cloud VPN of Cloud-interconnectie (Dedicated of Partner), die beveiligde tunnels creëren die de omgevingen met elkaar verbinden. Zodra de verbinding tot stand is gebracht, implementeert u beheeragents in elke regio om de centrale console te verbinden met de gedistribueerde load balancer-instanties.
Om de integratie te beveiligen, opent u de benodigde poorten: Poort 53 voor DNS, Haven 3009 voor gegevensuitwisseling (MEP), en Poort 443 voor management. Definieer Netwerk-eindpuntgroepen (NEG's) Of geef de IP-adressen van alle resources in de cloud op. Hierdoor kan de load balancer verkeer identificeren en routeren naar specifieke IP:poort-combinaties. Configureer bovendien health checks om de beschikbaarheid van endpoints te bewaken en ervoor te zorgen dat verkeer alleen naar gezonde serverpools wordt geleid.
Zodra de connectiviteit en de statusbewaking zijn ingesteld, is de volgende stap het configureren van strategieën voor de verkeersverdeling.
Verkeersdistributiebeleid configureren
Het kiezen van het juiste distributiealgoritme is essentieel voor efficiënt verkeersbeheer in de cloud. Bijvoorbeeld:
- Waterval per regioDeze methode verlaagt de latentie door de dichtstbijzijnde regio volledig te benutten voordat overtollig verkeer naar de eerstvolgende locatie wordt verplaatst.
- Spuiten naar de regioDit zorgt voor een gelijkmatige verkeersverdeling over alle zones.
Stel failover-drempelwaarden in op 70% Het verkeer verschuift dus wanneer het aantal gezonde eindpunten onder dit niveau daalt. Schakel automatische capaciteitsbeperking in, die wordt geactiveerd wanneer er minder dan 25% Als de lidinstanties de gezondheidscontroles doorstaan, wordt de capaciteit van de backend automatisch op nul gezet, waardoor wordt voorkomen dat verkeer naar ongezonde instanties wordt geleid.
Voor nauwkeurigere controle kunt u het volgende gebruiken: routering op applicatielaag (laag 7). Dit maakt het mogelijk om verkeer te sturen op basis van HTTP-headers, cookies of URL-paden. Gewogen verkeerssplitsing is met name handig voor canary-implementaties – bijvoorbeeld voor het sturen van verkeer naar specifieke URL's. 95% van het verkeer naar stabiele backends, terwijl nieuwe versies worden getest met de resterende backends. 5%. Voor omgevingen met strenge nalevingsvereisten kunt u de modus "STRICT" inschakelen om verkeersisolatie af te dwingen, waarbij verkeer wordt geblokkeerd in plaats van overloop tussen regio's toe te staan.
Zodra het beleid is vastgesteld, kan automatisering helpen om deze configuraties te stroomlijnen.
Processen automatiseren met API's
Automatisering vermindert handmatige fouten en versnelt de implementatie. Tools zoals Terravorm of de gcloud CLI kan worden gebruikt om programmatisch doorstuurregels, URL-toewijzingen en backendservices te beheren. In gecontaineriseerde omgevingen kunnen Kubernetes-native API's, zoals de Gateway-API of Multi Cluster Ingress (MCI), kan de verkeersverdeling over clusters afhandelen. Doorgaans ondersteunen projecten tot 100 MultiClusterIngress en 100 MultiClusterService standaardbronnen.
Implementeer een Configuratiecluster Het doel is om te fungeren als centraal controlepunt voor load balancing over meerdere clusters. Gebruik API's om schaalbeleid voor doeltracking in te stellen, waarbij het CPU-gebruik op het gewenste niveau wordt gehouden en tegelijkertijd wordt aangepast aan veranderingen in het verkeer. Koppel gezondheidscontroles rechtstreeks aan de backendcapaciteit met behulp van API's voor automatische capaciteitsafbouw en configureer dit. splitBrainThresholdSeconds Om snelle DNS-wijzigingen tijdens tijdelijke netwerkproblemen te voorkomen. Standaardiseer configuraties met op YAML gebaseerde servicebeleidsregels om consistente instellingen te garanderen op platforms zoals AWS, Azure en Google Cloud.
Conclusie
Samenvatting van de belangrijkste punten
Load balancing in meerdere clouds is gebaseerd op een flexibele, softwaregestuurde aanpak Dit zorgt ervoor dat het verkeer effectief over meerdere providers wordt verdeeld, waardoor vendor lock-in wordt voorkomen. Naarmate bedrijven gedistribueerde systemen implementeren om te voldoen aan de toenemende eisen op het gebied van prestaties en betrouwbaarheid, zijn deze methoden onmisbaar geworden.
Belangrijke strategieën zoals Wereldwijd verkeersmanagement (GTM) op de DNS- of edge-laag en Loadbalancing op privénetwerken (SLB) Binnen specifieke datacenters wordt de basis gelegd voor een robuuste multi-cloudomgeving. Intelligente routeringstechnieken – zoals Waterval per regio om de latentie te verminderen of Minst openstaande verzoeken Voor het afhandelen van complexe taken – helpt het verkeer naar de snelste en meest stabiele eindpunten te leiden. Realtime statusbewaking, in combinatie met automatische capaciteitsafvoer, Dit zorgt ervoor dat defecte resources worden omzeild, terwijl geautomatiseerde failover-mechanismen het verkeer omleiden wanneer de systeemstatus onder acceptabele drempelwaarden daalt.
Beveiliging en prestaties gaan in deze configuraties hand in hand. Functies zoals edge SSL/TLS-terminatie verminderen de latentie tijdens handshakes, terwijl Layer 7 applicatiebewuste routing Neemt beslissingen op basis van HTTP-headers, cookies of specifieke URL-paden. Zorgt voor consistente handhaving van Webapplicatiefirewalls (WAF) en Identiteits- en toegangsbeheer (IAM) Beleid op alle platformen helpt potentiële kwetsbaarheden af te dichten en een veilige omgeving te waarborgen.
Met deze principes in gedachten kunnen de volgende stappen u helpen bij het opbouwen van een betrouwbare en effectieve multi-cloudstrategie.
Volgende stappen voor een succesvolle multi-cloudomgeving
Om de voordelen van load balancing in meerdere clouds optimaal te benutten, kunt u de volgende stappen overwegen:
- Gebruik Infrastructuur als Code (IaC): Met tools zoals Infrastructure as Code (IaC) kunt u programmatisch doorstuurregels, URL-toewijzingen en backendservices beheren. Dit vermindert niet alleen handmatige fouten, maar versnelt ook implementaties van dagen naar minuten.
- Centraliseer de monitoring: Implementeer tools die realtime inzicht bieden in latentie en resourcegebruik binnen uw multi-cloudomgeving. Dit inzicht helpt u weloverwogen beslissingen te nemen en de systeemgezondheid te waarborgen.
- Implementeer schaalvergroting van doeltracking: De capaciteit dynamisch aanpassen op basis van prestatiecijfers om aan de vraag te voldoen zonder overcapaciteit te creëren.
- Handhaaf verkeersisolatie: Door het verkeer te isoleren, kunt u voorkomen dat regionale storingen zich over uw hele systeem verspreiden, waardoor de verstoringen beperkt blijven tot één specifiek gebied.
Met 94% aan werkbelastingen Nu bedrijven in 2021 in een multi-cloudomgeving draaien, zijn deze werkwijzen niet langer optioneel, maar essentieel om concurrerend te blijven in het snel veranderende digitale landschap van vandaag.
Veelgestelde vragen
Hoe maak ik de keuze tussen actief-actief en actief-passief?
Bij het kiezen tussen actief-actief en actief-passief Bij de configuratie draait alles om het vinden van de juiste balans tussen efficiëntie, fouttolerantie en complexiteit.
Een actief-actief Deze configuratie maakt gebruik van alle servers tegelijk, wat de doorvoer verhoogt en zorgt voor een betere betrouwbaarheid. Het vergt echter meer inspanning om te beheren en te onderhouden. Aan de andere kant, actief-passief Houdt één server actief terwijl de andere in stand-by blijft. Deze optie is eenvoudiger te beheren en zorgt voor een voorspelbaar failoverproces.
De prioriteiten van uw organisatie – of het nu gaat om prestaties, beheersgemak of fouttolerantie – zullen de juiste keuze voor uw behoeften bepalen.
Welke instellingen voor de gezondheidscontrole voorkomen ongewenste failovers?
Om problematische failovers te voorkomen, kunt u gezondheidscontroles instellen met meerdere succesvolle sonde-drempelwaarden en pas zowel de time-out- als de foutdrempels aan. Deze aanpak zorgt ervoor dat alleen echt ongezonde backends worden gemarkeerd en uit de service worden verwijderd. Het nauwkeurig afstellen van deze instellingen helpt de prestaties stabiel te houden en onnodige onderbrekingen te minimaliseren.
Welke meetwaarden zijn het belangrijkst voor latency in een multi-cloudomgeving?
Bij het meten van de latentie in een multi-cloudomgeving zijn er een aantal cruciale meetwaarden om in de gaten te houden:
- Reactietijd van de applicatieDit meet hoe snel een applicatie reageert op gebruikersverzoeken en biedt zo een direct inzicht in de gebruikerservaring.
- Netwerk retourtijdDit meet de tijd die data nodig heeft om van de bron naar de bestemming en terug te reizen, waardoor mogelijke netwerkvertragingen aan het licht komen.
- Prestatie-indicatoren voor resourcesDeze analyses richten zich op de prestaties van servers, databases of andere cloudbronnen en helpen bij het identificeren van eventuele knelpunten.
Deze meetwaarden geven samen een duidelijk beeld van de totale latentie en de reactiesnelheid van het systeem, waardoor het gemakkelijker wordt om de prestaties daar te optimaliseren.




