Top 7 Practices for Real-Time Data Synchronization
Real-time data synchronization ensures that updates across systems happen instantly, avoiding delays and keeping information accurate and actionable. This is critical for industries like finance, healthcare, and e-commerce, where outdated or mismatched data can lead to costly errors. Here’s a quick summary of the seven best practices to get it right:
- Set Clear Requirements: Identify critical data, prioritize updates, and establish a reliable source of truth to avoid conflicts.
- Choose the Right Strategy: Decide between client-server or peer-to-peer models based on your system’s architecture and performance needs.
- Resolve Conflicts Effectively: Implement automated techniques like Last-Write-Wins or version vectors to handle data discrepancies.
- Adopt Event-Driven Architectures: Use tools like Apache Kafka to trigger instant updates and maintain synchronization.
- Leverage Change Data Capture (CDC): Focus on tracking and syncing only modified data for low-latency updates.
- Secure and Scale Your System: Use encryption, access controls, and scalable infrastructure to handle growth and protect data.
- Optimize Networks and APIs: Ensure low-latency connections and robust APIs with retry mechanisms and monitoring.
These practices ensure reliable, fast, and secure synchronization, vital for real-time analytics, AI systems, and other critical applications.
Building real-time data sync solutions with Remix
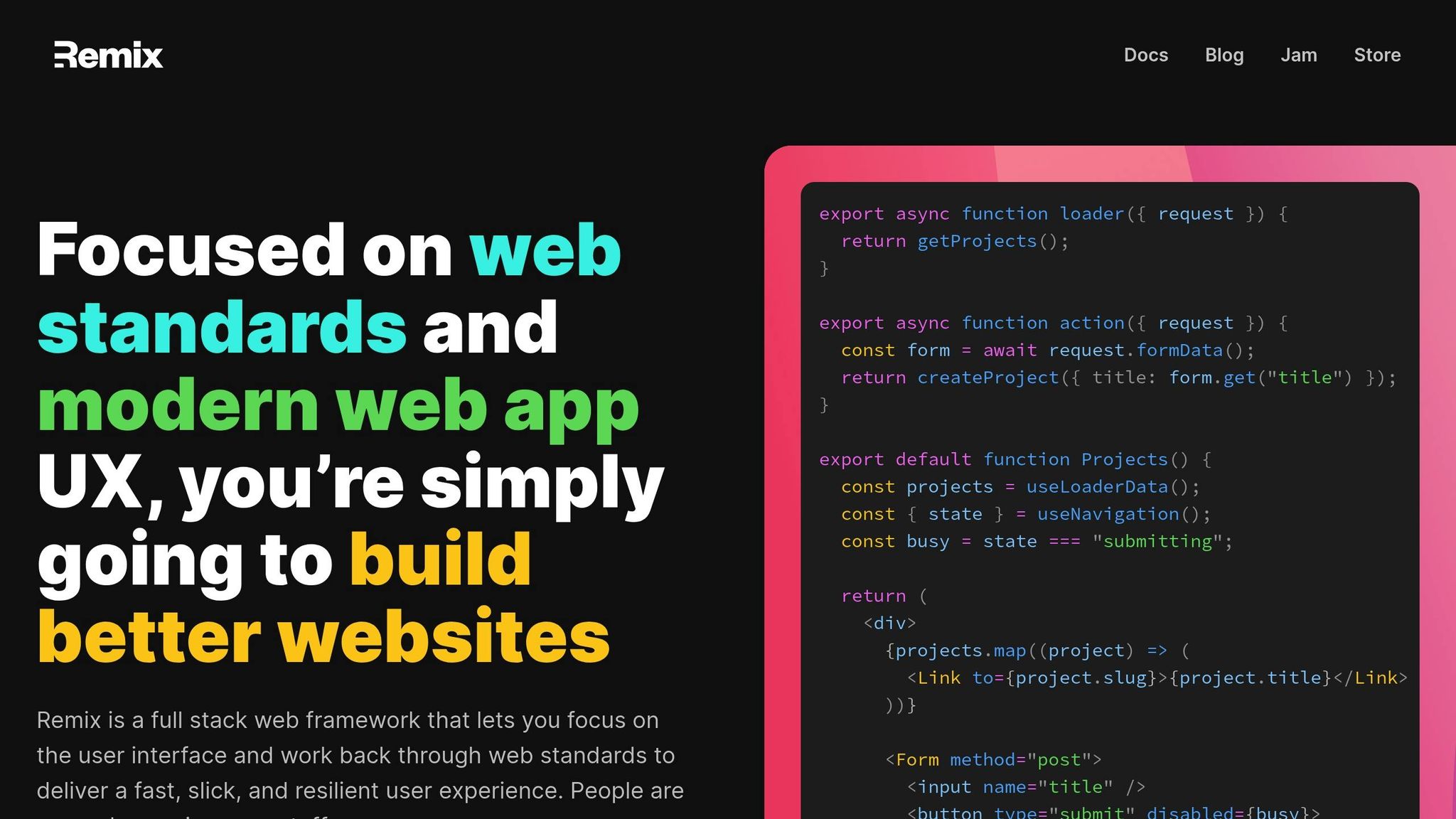
1. Define Clear Synchronization Requirements
Setting clear synchronization requirements is crucial to avoid performance hiccups, data conflicts, and system downtime. Think of this step as the blueprint that guides all your technical decisions.
Identify Key Data Elements
Start by cataloging all your data sources and ranking them based on their business impact and how often they need updates.
For example, in retail analytics, transaction records and inventory levels demand immediate synchronization to prevent overselling or missed opportunities. On the other hand, static data like product categories can be updated less frequently without disrupting operations. High-priority items typically include customer transactions, sensor readings, and financial records, as these directly affect critical business functions.
To prioritize effectively, evaluate data based on operational importance, compliance needs, and the cost of inconsistencies. In a healthcare system, for instance, patient vital signs and medication orders would rank as critical, while administrative records might take a backseat.
Collaboration is key here. Involve IT teams to understand technical constraints and business users to pinpoint the data that drives decision-making. This ensures you focus on synchronizing what truly matters – not just what’s easiest to handle technically.
Set Synchronization Frequency and Direction
Two major factors to address are synchronization frequency (how often data is exchanged) and direction (whether updates flow one way or both ways between systems). These decisions can help reduce network strain and avoid data conflicts.
Here’s a breakdown of synchronization types and their ideal use cases:
| Synchronization Type | Use Cases | Benefits |
|---|---|---|
| Real-Time | Fraud detection, critical transactions | Instant updates for immediate decisions |
| Near-Real-Time | Inventory updates, customer analytics | Balances speed with system performance |
| Batch | Historical reporting, large data migrations | Resource-efficient and cost-effective |
For example, financial trading systems often require millisecond-level synchronization, while marketing analytics might only need hourly updates. When deciding, consider factors like network bandwidth, system capacity, and the cost of frequent updates.
Using techniques like Change Data Capture (CDC) or timestamp-based synchronization can further optimize performance. These methods ensure only changed data is moved, cutting down on unnecessary network traffic and processing time.
Establish a Source of Truth
A single source of truth is essential to maintaining consistency and resolving data conflicts. Without it, disagreements about which system holds the "correct" data can lead to inefficiencies and errors.
Choose your source of truth based on factors like data accuracy, update frequency, system reliability, and business ownership. For example, in many organizations, the CRM system is the go-to for customer data, while the ERP system oversees product and inventory information.
When conflicts inevitably arise, the designated source of truth takes precedence, automatically resolving discrepancies. This reduces the need for manual intervention and minimizes the risk of human error.
To make this process seamless, document your source of truth decisions and share them with all stakeholders. Include the reasoning behind each choice – this will be invaluable for future troubleshooting and system upgrades.
If your organization uses Serverion‘s hosting solutions, their global data center infrastructure provides the reliability and low latency needed to maintain consistent source of truth systems across different locations. Their managed services can also ensure that your authoritative systems stay accessible and perform well, supporting smooth synchronization workflows.
2. Choose the Right Synchronization Strategy
Once you’ve defined your requirements, the next step is selecting the best synchronization strategy to ensure smooth real-time data flows. Your choice here is critical – it forms the backbone of your system’s operation. Picking the wrong approach can lead to inefficiencies, unnecessary complications, or even system failures. The two main options – client-server and peer-to-peer – each have their own strengths, depending on what your system needs.
Client-Server vs. Peer-to-Peer Models
Understanding how these two models differ is key to making a decision that fits your system’s architecture and performance goals.
Client-server synchronization relies on a central server that acts as the hub for all communications. Devices connect to this server, which handles data updates and ensures consistency across the system.
Peer-to-peer synchronization, on the other hand, skips the central server entirely. Devices communicate directly with each other, sharing updates as needed.
| Synchronization Model | Advantages | Disadvantages | Best Use Cases |
|---|---|---|---|
| Client-Server | Centralized control, easier to monitor, simpler conflict resolution | Single point of failure, potential bottlenecks | Cloud apps, SaaS platforms, mobile apps |
| Peer-to-Peer | No single point of failure, reduced local latency, scalable within local networks | Complex conflict resolution, harder to monitor | IoT networks, local collaboration, ad-hoc systems |
The client-server model works well when centralized control and easy conflict resolution are priorities. With the server as the "source of truth", it’s easier to manage and resolve inconsistencies. However, this centralization can also be a weakness – if the server goes down or becomes overwhelmed, the entire system can grind to a halt.
Peer-to-peer models avoid this issue by removing the need for a central server, making them more resilient and better suited for local operations. Devices can continue syncing even if part of the network goes offline. But this comes with its own challenges, particularly when it comes to resolving conflicts between devices.
Choosing the right model depends on balancing these benefits and trade-offs to meet your system’s specific needs.
Factors in Selecting a Synchronization Model
When deciding between synchronization strategies, consider these key factors:
- System Architecture: For cloud-based applications, the client-server approach often integrates more smoothly. On the other hand, distributed setups like IoT or edge computing tend to perform better with peer-to-peer models.
- Data Volume and Update Frequency: If your system handles a high volume of updates, a single server might struggle to keep up, making peer-to-peer or hybrid models more practical. For moderate data loads with strict consistency needs, client-server is usually a better fit.
- Latency Requirements: Applications requiring ultra-low latency for local operations benefit from peer-to-peer setups, as they bypass server round-trips. If consistency is more important than speed, the client-server model can handle the slight latency trade-off.
- Network Reliability: In areas with unstable network connections, peer-to-peer models shine because they can operate locally without relying on global connectivity. However, for systems needing global synchronization, a robust client-server infrastructure is essential.
- Security and Compliance: Centralized systems make it easier to enforce consistent security policies and meet regulatory requirements. Peer-to-peer systems, while resilient, can pose challenges in maintaining security and monitoring.
- Scalability Goals: Client-server models scale vertically by upgrading server resources, which can get expensive and hit physical limits. Peer-to-peer systems scale horizontally by adding more devices, but managing this distributed network requires sophisticated coordination.
For example, if you’re using Serverion’s hosting solutions, their global network of data centers ensures reliable and low-latency performance – ideal for client-server models. Their dedicated servers and VPS options are designed to handle the demands of real-time synchronization, while their managed services keep your infrastructure running smoothly across various locations.
3. Implement Strong Conflict Resolution Mechanisms
After establishing clear synchronization requirements and strategies, the next step is to focus on effective conflict resolution. This is essential for preserving data integrity across systems. When multiple systems update the same data simultaneously, conflicts can arise, leading to inconsistencies or even corrupted data. These issues can undermine the reliability of your operations if not addressed properly.
Conflicts happen more often than you might think. Imagine a customer updating their email address via a mobile app at the same time the billing system processes an address change. Or consider an inventory system receiving updates from both the warehouse and an e-commerce platform at nearly the same moment. To avoid chaos, automated conflict resolution mechanisms are necessary to keep everything running smoothly.
Common Conflict Resolution Techniques
Choosing the right conflict resolution approach depends on your system’s needs. Here are some of the most widely used techniques, each suited for specific scenarios:
- Last-Write-Wins (LWW): A straightforward approach where the system accepts the most recent update based on timestamps, discarding older changes. This method is ideal for systems prioritizing speed, though it risks overwriting important updates. For instance, a SaaS company in 2024 reduced sync times from 30 minutes to just 2 minutes by adding a
last_modifiedcolumn to their customer table. They processed only rows updated after the last sync, using LWW to ensure consistency. - Version Vectors: This method uses version numbers or vectors to track changes, helping systems decide whether an update is newer or if merging is required. It’s particularly effective in distributed environments with multiple nodes but requires a more complex setup and additional storage.
- Custom Logic: Tailored to specific business needs, custom logic allows you to define rules for conflict resolution. For example, a CRM system might prioritize sales team updates for contact details while giving billing data precedence to the accounting team. This approach offers flexibility but requires detailed documentation and ongoing maintenance.
- Source of Truth: By designating a single authoritative system, you can simplify conflict resolution. This system acts as the master record keeper, overriding updates from other sources during synchronization. It works well in centralized setups but can be a single point of failure in distributed systems.
| Technique | Best For | Advantages | Limitations |
|---|---|---|---|
| Last-Write-Wins | Speed-critical, high-volume systems | Simple and fast | May overwrite important updates |
| Version Vectors | Distributed systems | Handles complex scenarios well | Complex to implement; requires storage |
| Custom Logic | Business-critical, rule-based data | Highly adaptable to specific needs | Requires thorough documentation |
| Source of Truth | Centralized architectures | Clear authority over data | Risk of single point of failure |
The right choice will depend on your architecture, the importance of your data, and performance goals.
Document Conflict Resolution Policies
Once you’ve selected the best technique, documenting your conflict resolution policies is a must. Without clear documentation, your team may struggle with troubleshooting, onboarding, or adapting to system changes.
Start by explaining why you chose one method over another. For instance, why LWW might work better than version vectors in your setup. This context helps future team members understand the reasoning behind your decisions.
Define specific rules for prioritizing data sources. For example, document which system acts as the source of truth for certain data types, how timestamps are managed across time zones, and what to do if the authoritative system becomes unavailable. Include examples of typical conflict scenarios, such as a customer profile update clashing with a batch address-processing job, and outline the expected resolutions.
It’s also important to plan for manual intervention. Specify who has the authority to override automated decisions, how to handle resolution failures, and the process for updating policies when new challenges arise. Regularly review and update your policies to keep them aligned with evolving business needs. For regulated industries, maintaining version history and approval processes is especially important.
For organizations using Serverion’s hosting services, their global data centers and managed solutions provide a reliable foundation for conflict resolution. Their servers can handle the computational demands of complex algorithms, while their management services help enforce your policies across distributed systems.
By investing in detailed documentation, your team will have a reliable resource to quickly diagnose and resolve conflicts, ensuring data integrity even in high-pressure situations.
[1] Source: Skyvia, 2025
4. Use Event-Driven Architectures
Building on solid synchronization techniques and conflict resolution, event-driven architectures take responsiveness to the next level. These systems replace scheduled updates with instant reactions to data changes, ensuring real-time consistency across all connected systems.
When data is updated, an event is triggered to notify all relevant systems immediately. This creates a dynamic environment where databases, applications, and services are updated automatically and without delay.
The Role of Event-Driven Systems
Event-driven systems are designed to handle real-time updates efficiently using messaging platforms like Apache Kafka and Google Pub/Sub. These tools manage high-throughput event streams, making them ideal for keeping systems synchronized.
Here’s how it works: when data changes, an event is published to a specific topic. Subscribing systems then receive and process the update immediately. Thanks to the producer-consumer model, data sources (producers) and consuming systems (consumers) remain independent. Producers send events whenever changes occur, while consumers subscribe to topics and act on the updates as they arrive.
For example:
- Financial trading platforms rely on Kafka to synchronize trades and account balances across global data centers in milliseconds. This speed is critical for avoiding losses during market fluctuations.
- E-commerce companies use Pub/Sub to update inventory and order statuses in real time. When a customer places an order, the inventory system instantly reflects the change, and order tracking is updated seamlessly across all platforms.
Scalability is another key advantage. Event-driven systems can manage massive event volumes by adding more consumers or distributing topics across multiple servers.
Maintain Event Schema and Message Order
To ensure smooth communication across systems, structured event schemas play a crucial role. These schemas define the content and format of events, making sure every system interprets the data correctly. Without them, misinterpretations could lead to data corruption or synchronization errors.
Tools like Avro, Protobuf, or JSON Schema help enforce data structure validation in Kafka. Every event must follow the schema before it’s published, which prevents malformed data from reaching consumers. This validation saves time by catching errors early and reducing debugging efforts.
Schema versioning is equally important. As business needs evolve, new fields can be added without disrupting existing systems. A schema registry ensures compatibility, allowing updates to happen smoothly.
Message order is another critical factor. When events arrive out of sequence, systems might process updates incorrectly, causing conflicts or even data loss. Imagine an inventory system receiving a "product added" event after a "product sold" event for the same item – this could result in a negative inventory count.
Kafka handles this issue with partition keys, ensuring events with the same key are processed in order within a specific partition. This maintains consistency for related updates.
Here’s a quick breakdown of ordering strategies:
| Ordering Strategy | Best For | Implementation | Trade-offs |
|---|---|---|---|
| Partition Keys | Customer records, account updates | Use unique identifiers as keys | Limits parallel processing within partitions |
| Sequence Numbers | Financial transactions, audit logs | Add timestamps or counters to events | Requires buffering by consumers |
| Global Ordering | Critical business processes | Use a single partition for all events | Reduces throughput capacity |
Including sequence numbers or timestamps in event payloads adds an extra layer of ordering control. Consumers can use these to detect out-of-order events and buffer them for proper sequencing. This is particularly useful in scenarios like financial transactions, where the order of operations affects account balances and regulatory compliance.
To further protect data accuracy, design consumers to be idempotent – able to handle duplicate events without causing errors. This is essential because network issues or system failures can sometimes lead to duplicate deliveries.
Finally, regular monitoring is key to maintaining reliability. Set up alerts for issues like failed event processing, unusual delays, or schema validation errors. Catching these problems early ensures your system stays dependable and responsive.
sbb-itb-59e1987
5. Apply Change Data Capture (CDC) and Real-Time Monitoring
Change Data Capture (CDC) is a method that keeps track of database changes in real time, focusing only on the data that’s been modified. It captures inserts, updates, and deletions as they happen, ensuring that only the changes are propagated. This eliminates the need for full dataset transfers, making it an efficient way to handle real-time events and data updates.
CDC works by tapping into transaction logs, triggers, or timestamp columns to identify changes. This ensures that updates reach target systems almost immediately, keeping everything in sync.
Change Data Capture for Low-Latency Updates
CDC shines in its ability to reduce latency and resource usage. Unlike traditional batch processing, which transfers large datasets even if only a few records have changed, CDC pinpoints the exact modifications and sends only those updates. This saves bandwidth and processing time.
Log-based CDC is one of the most efficient methods. Tools like Debezium and Striim monitor database transaction logs directly, capturing changes without straining the source system. This approach works well with databases like PostgreSQL, MySQL, and SQL Server.
Trigger-based CDC, on the other hand, uses database triggers to log changes into separate tracking tables. While this method offers detailed historical records, it can add extra overhead during high-volume operations.
The choice of CDC method depends on specific needs:
| CDC Method | Latency | System Impact | Implementation Complexity | Best For |
|---|---|---|---|---|
| Log-based | Very Low | Minimal | High | High-volume, critical systems |
| Timestamp | Low | Low | Medium | General-purpose synchronization |
| Trigger-based | Low | Medium | Low | Detailed audit requirements |
Industries like financial services and e-commerce rely on CDC to keep account balances and inventory levels accurate across multiple systems in real time.
To maintain reliability, it’s important to track the lineage of records, ensuring you can trace changes from their source to the destination. This creates an audit trail that’s essential for troubleshooting and compliance. Features like table inclusion/exclusion rules help control which data gets synchronized, while column mapping ensures sensitive data stays secure.
Real-Time Monitoring and Alerting
For CDC systems to work effectively, they need constant oversight. Real-time monitoring ensures synchronization processes run smoothly, identifies bottlenecks, and catches failures before they disrupt operations.
Platforms like Prometheus and Grafana offer dashboards that display important metrics, such as synchronization lag, error rates, and throughput. Cloud-based tools like AWS CloudWatch and Google Stackdriver integrate seamlessly with CDC systems, providing monitoring without requiring additional infrastructure.
Critical metrics include:
- Synchronization lag time: Measures how quickly changes are propagated. Most systems aim to keep lag times within a few seconds, though mission-critical setups may demand even faster performance.
- Error rates: Monitoring error thresholds ensures that significant issues are flagged for investigation.
- Data freshness indicators: Show the last update time on target systems, with any gaps signaling potential problems like network issues or tool failures.
"Automated alerts for AWS Lambda improve monitoring and incident response by identifying key metrics and leveraging integrated tools for swift actions." – Serverion Blog Post, October 12, 2025
Effective alerting requires setting thresholds that account for normal variations. Instead of flagging every minor delay, alerts should focus on sustained issues that exceed acceptable limits. Automated notifications – via email, SMS, or tools like PagerDuty – ensure the right team members are informed promptly, with escalation protocols for unresolved alerts.
Self-healing mechanisms can also address common issues automatically. For example, if a sync job fails due to a temporary network issue, the system can retry before escalating the problem. Regular synchronization audits during off-peak hours can further verify data accuracy and identify configuration problems.
6. Build Secure and Scalable System Design
When dealing with real-time data synchronization, creating a system that’s both secure and scalable is non-negotiable. You need to protect sensitive data while ensuring your system can handle growing demands without breaking a sweat.
Implement Security Best Practices
Real-time synchronization comes with unique security challenges. To keep data safe during constant updates, end-to-end encryption is a must. Use encryption protocols like TLS/SSL for all API endpoints and AES-256 encryption for stored data. This ensures data is secure both in transit and at rest.
Strengthen your API access by implementing multi-factor authentication (MFA) and OAuth 2.0 to prevent unauthorized access. Additionally, role-based access control (RBAC) ensures users only interact with the data they truly need, minimizing exposure risks.
Layered security is key. Use hardware and software firewalls to create multiple barriers against threats. Protect your uptime with DDoS defenses – services like Serverion offer strong solutions to keep operations running even during attacks.
Compliance is another critical piece of the puzzle. Depending on your industry, you may need to meet standards like HIPAA for healthcare, GDPR for European data protection, or SOC 2 for financial services. Techniques like data masking safeguard sensitive information during development, while audit logging tracks every access and modification for accountability.
Security isn’t a one-and-done task. Regularly update your systems, conduct audits, and use automated compliance checks to address new threats as they emerge. Continuous monitoring tools can help detect unusual activity early, stopping potential issues before they escalate. All of this works hand-in-hand with scalability to ensure your system grows securely.
Design for Scalability and Redundancy
Real-time data synchronization demands a system architecture that can handle spikes in usage without missing a beat. Scalability and redundancy are your allies here.
Start with horizontal scaling and data partitioning to keep query times low and responsiveness high. Cloud-native platforms can be a game-changer, offering automatic scaling to handle traffic surges. Tools like Kubernetes enable dynamic resource allocation, spinning up or down as needed to match demand.
Redundancy is your safety net against failures. Distribute your system across multiple geographic locations to protect against regional outages. An active-active architecture ensures functionality remains intact across all locations. Add load balancers to reroute traffic from failed nodes, keeping services available.
Don’t forget about failover mechanisms – they should activate automatically to minimize downtime. Regularly test these processes to ensure they’ll work when it matters most.
Finally, protect your data with solid backup strategies. Use a mix of regular snapshots and incremental backups to save on storage and speed up recovery times. Performance monitoring tools like Prometheus and AWS CloudWatch can give you real-time insights into system health, from resource usage to error rates. Automated alerts can help you address issues before they snowball, ensuring your system stays reliable and responsive.
7. Optimize Network Infrastructure and APIs
Making sure your network and APIs are fine-tuned is essential for smooth, real-time data synchronization. Even the most advanced strategies can falter if network lag slows things down or APIs can’t handle the pressure of constant updates. By addressing these basics, you can ensure data moves quickly and reliably across systems.
Build a Low-Latency Network
When it comes to real-time analytics, network latency is a big deal. The faster data reaches its destination, the better. Every millisecond counts.
- Modern SSDs and high-speed NICs (10–100 Gbps) are game-changers. They significantly cut down on storage and transfer delays, keeping data moving efficiently.
- Geographic proximity matters. By placing servers closer to users, like Serverion does with its global network, you can reduce round-trip times from hundreds of milliseconds to just a few.
- Software-defined networking (SDN) gives you an edge by dynamically prioritizing synchronization traffic. Unlike traditional setups, SDN reroutes data around congested areas and allocates bandwidth where it’s needed most, especially during peak times or outages.
In top-tier data centers, optimized routing and high-speed networks can bring latency down to just 1-2 milliseconds – essential for real-time analytics, where even slight delays can disrupt decision-making.
- Redundant network paths are a must. These ensure traffic is automatically rerouted during outages, keeping latency low even if part of the network fails. Using multiple ISPs and diverse routing options adds another layer of reliability.
To keep things running smoothly, continuous monitoring is key. Tools that track latency, packet loss, and throughput can catch potential issues early. Automated alerts for latency spikes help maintain error rates below 0.1%, especially critical for systems where precision is non-negotiable.
Develop Secure APIs for Synchronization
APIs are the backbone of real-time synchronization systems, acting as the communication channels that keep everything in sync. They need to handle constant data flow while staying secure and reliable.
- WebSockets are ideal for real-time synchronization. Unlike REST APIs, which require constant polling, WebSockets maintain persistent, bidirectional connections. This allows servers to push updates instantly, cutting down latency and reducing network overhead.
- Security is non-negotiable. Use HTTPS and WebSockets with TLS encryption, and implement strong authentication protocols like OAuth 2.0 and API keys. Input and output validation is also crucial to prevent malicious data from sneaking in.
To handle inevitable hiccups like transient network issues or API rate limits:
- Automatic retries with exponential backoff can reduce data loss and downtime by up to 90%.
- Idempotent API endpoints ensure reliable synchronization by producing the same result, even if the same request is made multiple times. This is critical for avoiding duplicate updates during retries.
- Transaction and error logging helps diagnose and fix issues quickly. Adding circuit breakers and fallback strategies ensures service continuity, even when downstream systems face problems.
- Performance monitoring is essential. Tools like Prometheus or AWS CloudWatch let you track API response times, error rates, and throughput in real time. Automated alerts for latency spikes or rising error rates help address problems before they affect users.
For demanding API workloads, hosting on high-performance infrastructure like Serverion’s dedicated servers and VPS solutions makes all the difference. With features like DDoS protection capable of handling attacks up to 4 Tbps and 99.99% uptime guarantees, your APIs can maintain consistent performance even under challenging conditions.
Use Message Queues for Reliability and Ordering
Message queues act as a safety buffer between producers and consumers, ensuring data remains intact during traffic surges or unexpected system issues. This makes them a valuable addition to the event-driven and CDC (Change Data Capture) strategies discussed earlier, helping maintain synchronization across systems.
Why Message Queues Matter
Message queues enhance system stability by ensuring messages are delivered and processed in the correct order, even during disruptions. They’re especially useful in scenarios where reliability is non-negotiable.
One of their standout features is guaranteed delivery. If your database crashes or a service goes offline, messages don’t vanish – they stay in the queue until the system is back up. This is crucial for industries like finance, where losing even a single transaction record could lead to compliance headaches. For example, Amazon SQS can scale automatically to handle millions of messages per second, making it ideal for peak times like Black Friday sales. The queue absorbs the traffic spike, ensuring no data is lost while systems catch up.
Another key benefit is order preservation. For processes that rely on sequential data, like transaction logs, maintaining the correct order is critical. Apache Kafka, for instance, ensures messages within a partition are processed in sequence. Imagine a customer making a deposit followed by a withdrawal – Kafka guarantees these events are processed in the right order, so your analytics or reporting systems reflect accurate data.
Message queues also provide fault tolerance. If a consumer service goes down, the queue holds unprocessed messages until the service recovers, allowing producers to continue working without interruption. This decoupling ensures smooth operation even when parts of the system face issues.
Lastly, they handle load buffering during traffic spikes. Instead of overwhelming backend systems, queues absorb bursts of data, letting consumers process messages at a manageable pace. This is especially useful during high-demand periods or when recovering from outages. Hosting environments with robust infrastructure, like Serverion, can further enhance queue performance with high-speed storage and reliable network connectivity.
Strategies for Ensuring Reliability
To maximize reliability, consider these strategies:
- At-least-once delivery: This ensures no data is lost. Consumers must explicitly confirm when they’ve processed a message. Until then, the queue retains the message. If a consumer crashes mid-task, the message is re-delivered, ensuring nothing slips through the cracks. To prevent duplicates, design consumers to be idempotent by using unique message identifiers.
- Persistent storage: For critical data, configure queues to save messages to disk. This ensures recovery even after server crashes.
- Dead-letter queues: When a message can’t be processed after several retries, it’s moved to a separate queue for troubleshooting. This prevents problematic messages from clogging the system while giving you insight into the issue.
- Transactional processing: To avoid race conditions in distributed systems, use transactional processing when possible. Some queue systems, like Amazon SQS, offer built-in deduplication features to handle duplicate messages automatically.
- Monitoring and alerting: Keep track of queue depth, processing speed, and error rates. Set up alerts for when queues back up or error rates spike. Tools like Prometheus or AWS CloudWatch can provide real-time insights into queue performance.
For added reliability, consider partitioning your data across multiple queues to boost processing speeds and isolate faults. Replication across nodes or data centers provides another layer of protection against hardware failures or network issues.
Integrating these strategies into your real-time synchronization setup ensures consistent data flow and strengthens the overall system. Whether you’re managing analytics, transaction processing, or other critical operations, message queues are a cornerstone of a reliable infrastructure.
Conclusion
This checklist highlights essential steps for achieving effective real-time data synchronization – a cornerstone of modern analytics. By following these seven best practices, you can ensure a steady, accurate flow of data through a combination of technical infrastructure and strategic planning.
Laying the groundwork involves defining clear requirements, selecting the right strategies, and implementing strong conflict resolution mechanisms. Tools like Change Data Capture (CDC) and real-time monitoring provide the performance boost needed for synchronization at scale. Meanwhile, optimized networks and secure APIs ensure data moves swiftly and safely.
Key Takeaways
Organizations that excel in real-time synchronization often see significant improvements in reliability and accuracy. Combining event-driven architectures with message queues results in systems that can handle traffic surges without losing data or compromising order. The most successful implementations focus on three critical areas:
- Creating a single source of truth to avoid data conflicts.
- Using continuous monitoring with automated alerts to quickly identify and address issues.
- Planning for scalability to support growth without requiring major system overhauls.
These practices are particularly important for mission-critical applications. Whether you’re working on real-time analytics, AI-driven projects, or business intelligence systems, the quality of your data synchronization directly influences the accuracy of insights and decision-making.
FAQs
What’s the best way for businesses to choose between client-server and peer-to-peer synchronization models?
When deciding on the best synchronization model for your business, it’s all about understanding your specific needs. If centralized control and handling large amounts of data are priorities, a client-server model could be your best bet. On the other hand, if your focus is on decentralized systems and direct device-to-device sharing, a peer-to-peer model might be the way to go.
Key considerations include the volume of data you’re dealing with, the reliability of your network, and your security requirements. Partnering with dependable hosting providers, such as Serverion, can make a big difference in achieving secure and efficient data synchronization.
What are the best practices to ensure data security and compliance during real-time data synchronization?
To keep data secure and maintain compliance during real-time data synchronization, there are a few key steps to follow. Start by encrypting all data – both while it’s being transmitted and when it’s stored. This helps protect sensitive information from prying eyes. Pair this with strong firewalls to block unauthorized access.
It’s also crucial to stay ahead of potential threats by regularly updating your systems and applying security patches. This minimizes vulnerabilities that could be exploited. Around-the-clock system monitoring is another must, as it helps you detect and address issues immediately. Lastly, maintaining frequent backups ensures your data remains intact and accessible, even if something unexpected happens.
By sticking to these practices, you can create a system that’s both secure and compliant.
How do event-driven architectures and Change Data Capture (CDC) enhance real-time data synchronization?
Event-driven architectures and Change Data Capture (CDC) combine to enhance the efficiency and precision of real-time data syncing. CDC works by identifying and recording data changes as they occur, minimizing delays and ensuring updates are both timely and accurate.
Event-driven architectures take this a step further by immediately reacting to these captured changes. This allows systems to synchronize data effortlessly across various platforms. When used together, these approaches establish a strong foundation for maintaining consistency and reliability in real-time analytics.




