
Cross-Region Failover Design for Disaster Recovery
Cross-region failover ensures business continuity during major disruptions by automatically transferring workloads from a primary to a secondary region. This approach is ideal for large-scale outages like hurricanes or regional power failures. However, it comes with higher costs and significant complexity compared to other disaster recovery methods.
Key points to consider:
- Reliability: Provides strong protection against regional outages with automated failover and data replication.
- Costs: Expensive due to duplicated infrastructure and data transfer fees.
- Complexity: Requires advanced setup, including DNS routing and failback processes.
- Recovery Time Objective (RTO): Varies by setup:
- Active-active: Near-zero RTO.
- Warm standby: Minutes.
- Cold standby: Hours.
Other options include active-active redundancy (high reliability, highest cost) and active-passive redundancy (more affordable, slower recovery). Choosing the right strategy depends on your business’s downtime tolerance and budget.
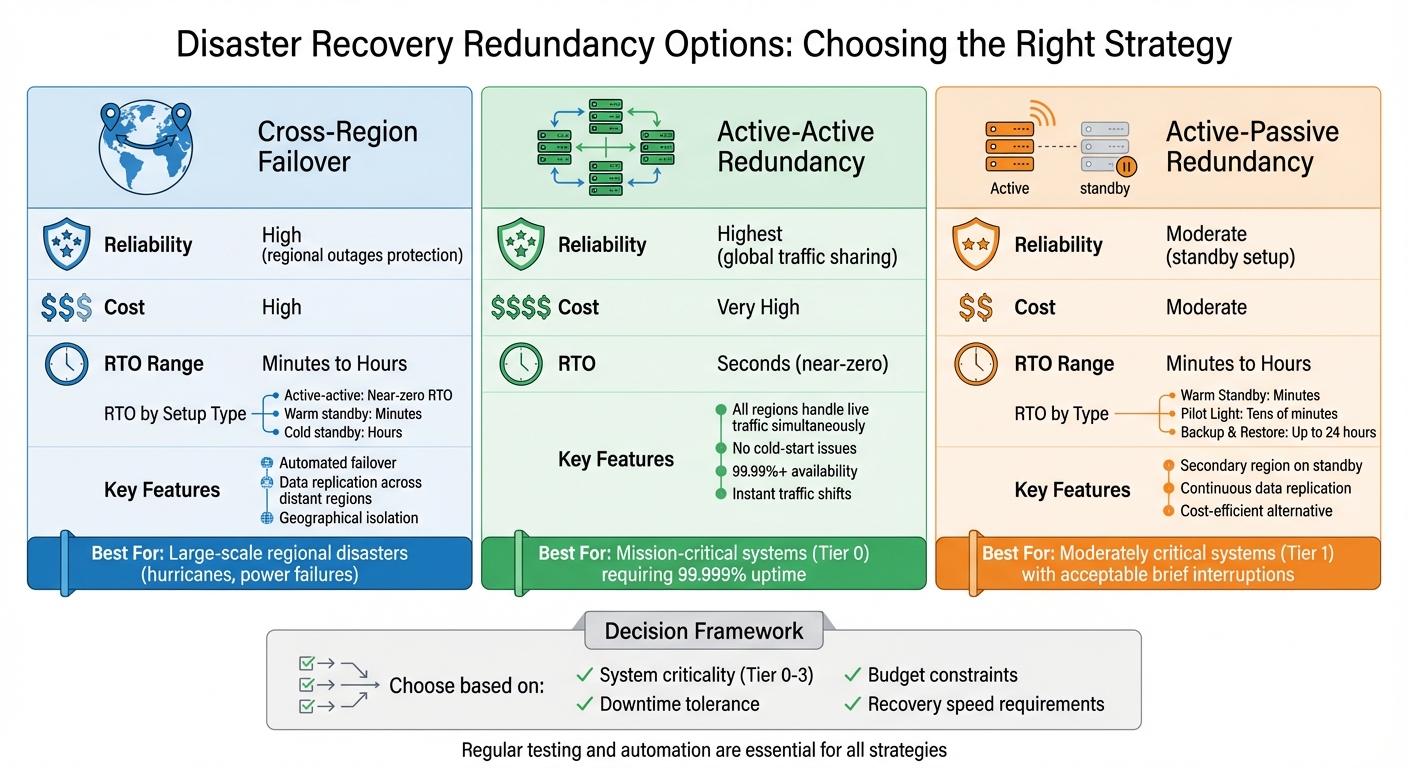
| Redundancy Option | Reliability | Cost | RTO |
|---|---|---|---|
| Cross-Region Failover | High (regional outages) | High | Minutes-Hours |
| Active-Active | Highest (global traffic sharing) | Very High | Seconds |
| Active-Passive | Moderate (standby setup) | Moderate | Minutes-Hours |
Selecting the right method involves balancing reliability, cost, and recovery speed based on your system’s criticality. Regular testing and automation are essential for success.
Disaster Recovery Redundancy Options Comparison: Cost, RTO, and Reliability
How To Configure Cross-Region Application Failover?
Proper configuration often requires choosing the right datacenter locations to minimize latency and ensure redundancy.
sbb-itb-59e1987
1. Cross-Region Failover
Cross-region failover is a disaster recovery approach designed to shift production workloads from a primary region to a secondary one located far away. While Multi-AZ strategies handle local data center failures within about 60 miles, cross-region failover steps up to tackle much larger disasters – think earthquakes, floods, or regional power outages. This setup relies on infrastructure spread hundreds or even thousands of miles apart. Below, we’ll dive into its reliability, cost considerations, operational challenges, and how it affects Recovery Time Objective (RTO).
Reliability
Cross-region failover provides geographical isolation, making it a robust solution for regional outages. For example, if a hurricane causes a power outage across an entire region, the secondary region seamlessly takes over. Automated monitoring systems detect performance issues and trigger failover, while continuous block-level replication ensures data stays intact, safeguarding both infrastructure and critical information.
The AWS Well-Architected Framework highlights that skipping proper failover practices poses a "High" risk level for workload resilience. Regular recovery drills are key to ensuring your disaster recovery plan actually works when it’s needed. These drills move plans from being theoretical to proven, which is crucial for keeping services running and avoiding revenue loss.
Cost Considerations
Cross-region failover comes with a hefty price tag compared to Multi-AZ solutions. The reason? You’re essentially doubling your storage and operational costs by maintaining mirrored databases and applications across distant regions. On top of that, data transfer fees for cross-region replication can quickly add up, with costs varying significantly depending on the regions involved.
For large organizations with over 2,000 employees, disaster recovery expenses using in-house solutions can range from $675,000 to $1,750,000 annually. If you’re aiming for near-zero RTO, expect those costs to climb even higher. Real-time replication to meet minimal RPO requirements further increases expenses. To manage these costs, many businesses choose to replicate only their most essential applications rather than their entire environment.
Operational Complexity
Setting up cross-region failover isn’t as straightforward as flipping a switch – it requires advanced orchestration. You’ll need to handle global DNS routing, asynchronous data replication, and automated failover processes across distant regions. Using Infrastructure as Code (IaC) is critical for maintaining consistency and repeatability between your primary and secondary setups.
The process of failback – returning operations to the primary region after recovery – is even more challenging. It involves resynchronizing data to prevent loss, redirecting traffic via DNS, and managing reversed replication to secure the newly active instances. This level of complexity demands skilled teams and detailed documentation to execute smoothly.
Recovery Time Objective (RTO)
Your RTO depends heavily on the failover model you choose. Active-active configurations allow both regions to handle traffic simultaneously, achieving near-zero RTO. Warm standby setups, where minimal services run in the secondary region, can deliver RTOs measured in minutes. On the other hand, cold standby approaches, where resources are spun up only after a failure, result in RTOs measured in hours.
For systems requiring 99.999% availability, RTOs are typically measured in seconds, while less critical systems with 99.9% availability can tolerate downtime measured in hours. Automated runbooks and IaC tools reduce the risk of human error during failover, helping you stick to tight RTO targets – especially when every minute of downtime translates to lost revenue and customer trust.
2. Active-Active Redundancy
Active-active redundancy ensures that applications run simultaneously in two or more regions, with live traffic distributed across all of them. Unlike active-passive setups, where the secondary region remains idle or minimally active, active-active configurations have every region handling real user requests. This eliminates cold-start issues since all regions are always operational. Let’s explore how this setup boosts reliability, even during severe regional failures.
Reliability
Active-active configurations provide top-tier reliability among disaster recovery strategies. Services like Amazon Route 53 Application Recovery Controller continuously monitor the health of multiple regions and automatically redirect traffic away from failing infrastructure. This setup is ideal for mission-critical workloads (Tier 0) that demand Service Level Objectives exceeding 99.99%. For businesses where even a few seconds of downtime can lead to lost revenue or eroded customer trust, this level of reliability is indispensable.
"Automation Beats Heroics: Having an automated failover process is infinitely better than relying on someone to manually fix things during an outage." – Alex Brooks, AWS Solutions Architect
Cost Efficiency
Active-active redundancy is the most expensive disaster recovery option. This is because you’re paying for full compute and storage capacity in multiple regions 24/7. Costs are further increased by continuous cross-region data replication and hourly billing for resources like Amazon EBS volumes and snapshots. However, for businesses where downtime directly impacts revenue, these expenses are often considered worthwhile. For less critical systems, active-passive warm standby setups may offer a more economical alternative.
Implementation Complexity
Setting up active-active redundancy is more intricate than standard failover models. It requires precise global synchronization, including synchronized caching (e.g., ElastiCache), advanced traffic routing, and maintaining consistent data across regions.
Data consistency poses a significant challenge. Synchronous replication ensures accuracy but increases write latency and is usually limited to a single region. Asynchronous replication supports cross-region recovery but introduces lag, which can result in outdated data. To manage these complexities, Infrastructure as Code (IaC) can replicate network topologies and security configurations across regions. Automation tools and runbooks handle database promotion and traffic routing during failures, while Amazon CloudWatch aggregates metrics to decide when failover should occur.
Recovery Time Objective (RTO)
Active-active redundancy delivers an RTO measured in seconds, often achieving near-zero downtime. Since all regions are already serving live traffic, failover involves simply adjusting traffic weights rather than waiting for resources to spin up or databases to promote. Tools like AWS Global Accelerator use static IP addresses that remain constant, even when backend endpoints fail, allowing for faster traffic shifts compared to DNS-based failover methods.
| Dimension | Active-Active Redundancy | Active-Passive (Warm Standby) |
|---|---|---|
| Reliability | Highest; traffic active in all regions | High; requires successful failover |
| Cost Efficiency | Most expensive; full resources in all regions | More cost-effective; secondary region scaled down |
| Complexity | High; needs global data synchronization | Moderate; automated failover scripts required |
| RTO | Near-zero; traffic shifts instantly | Minutes to hours; depends on scaling/promotion |
This table highlights key differences between active-active and active-passive configurations, offering a clearer perspective on their trade-offs.
3. Active-Passive Redundancy
Active-passive redundancy is a disaster recovery setup where your primary region handles all live traffic, while a secondary region stays on standby, ready to take over if needed. This approach offers a more budget-friendly alternative to active-active configurations but comes with trade-offs, particularly in failover speed. Unlike active-active setups, the secondary region doesn’t process requests until a failure occurs. There are two main types of active-passive setups: Pilot Light, which keeps only essential resources like databases running, and Warm Standby, which maintains a lightweight but operational version of your workload in the secondary region.
Reliability
Active-passive configurations rely on continuous data replication to ensure reliability, with the primary region regularly syncing data to the secondary region. This data is safeguarded with encryption, and failover is triggered through DNS changes, often monitored and automated via tools like CloudWatch.
However, there are challenges. The biggest concern is replication lag, where data updates might not be fully synchronized between regions. Some orchestration tools don’t automatically check for lag before initiating failover, meaning manual intervention might be needed to avoid data loss. After failover, the system requires "reversed replication" to protect the newly active region, which isn’t automatic. Additionally, if network bandwidth is insufficient, continuous replication can fail, leaving your data unprotected.
Cost Efficiency
Active-passive redundancy strikes a balance between cost and performance. It’s more affordable than active-active setups but pricier than simple backup-and-restore methods. Costs depend on the type of configuration:
- Pilot Light keeps costs low by running only essential resources like databases, while compute resources remain staged but inactive.
- Warm Standby is costlier because it keeps a scaled-down version of your workload running in the secondary region.
Other ongoing expenses include cross-region data transfer fees, Amazon EBS storage charges, and hourly costs for disaster recovery services. To optimize costs, you can use serverless technologies like AWS Lambda and Amazon API Gateway in the passive region, avoiding charges for idle compute resources. For networking, VPC peering is a simpler and more affordable option compared to Transit Gateway.
Implementation Complexity
Setting up active-passive redundancy requires moderate effort. You’ll need to configure DNS redirection, automated failover mechanisms, and a clear process for returning operations to the primary region. Tools like AWS CloudFormation or HashiCorp Terraform can simplify deployment by ensuring consistent resource setups across regions. Regular failover drills are essential to verify that everything works as expected and to train your team on the process.
The failback process adds another layer of complexity. To return to the primary region, you’ll need to copy data back from the recovery region, which can be time-consuming. This often involves deleting outdated primary databases and creating new replicas. Enhancing security by segmenting critical data into separate AWS accounts for staging and recovery regions can add operational overhead, further complicating recovery efforts. These factors ultimately impact recovery time, which we’ll explore next.
Recovery Time Objective (RTO)
The RTO for active-passive setups depends on your chosen strategy:
- Backup and Restore: Typically takes up to 24 hours to recover.
- Pilot Light: Achieves RTO in tens of minutes, as compute resources need to be provisioned and scaled during recovery.
- Warm Standby: Offers faster recovery, often within minutes, since instances are already running and just need scaling.
AWS Elastic Disaster Recovery is a useful tool that combines Pilot Light’s cost savings with Warm Standby’s faster recovery times.
Automation plays a critical role in reducing RTO by cutting out manual steps. For example, DNS TTL settings and Route 53 routing updates determine how quickly users are redirected to the recovery region. Additionally, using data plane APIs can improve the reliability of failover during regional outages, ensuring a smoother transition.
Advantages and Disadvantages
Every redundancy method comes with its own set of trade-offs, balancing cost, complexity, and recovery speed. Here’s a closer look at how these methods stack up:
Cross-Region Failover is a solid choice for high-priority workloads that require uninterrupted business operations during regional outages. It supports automated failover with a defined recovery time objective (RTO). However, this convenience isn’t cheap. Data transfer and synchronization can rack up significant costs, and the failback process can be tricky, involving reversed replication and manual cleanup. As John Formento from Amazon Web Services points out:
"If the multi-Region architecture isn’t built correctly, it’s possible for the overall availability of the workload to decrease."
Active-Active Redundancy provides lightning-fast recovery with near-zero RTO and ensures users are served from the nearest geographic location. This setup is ideal for global audiences needing top-notch performance. On the flip side, maintaining fully operational application stacks in multiple regions drives up costs. Data synchronization can also be a headache, and a poorly designed system could unintentionally reduce overall availability.
Active-Passive Redundancy is a more budget-friendly option, utilizing warm standby or pilot light setups to save on costs. Since you’re not paying for idle compute resources, it’s easier on the wallet. Plus, failover drills don’t disrupt the primary environment. The trade-off? A higher RTO compared to active-active setups. Recovery depends on how quickly passive resources can scale and DNS traffic can be redirected. Additionally, managing data replication is critical to avoid issues like replication lag, which could result in data loss during a failover.
| Redundancy Method | Key Advantages | Key Disadvantages |
|---|---|---|
| Cross-Region Failover | Automated recovery; defined RTO; ensures business continuity | High data transfer costs; complex failback process; risk of data loss from replication lag |
| Active-Active | Near-zero RTO; improves global performance; highest availability | Expensive; challenging data synchronization; potential for reduced availability if misconfigured |
| Active-Passive | Cost-efficient; drills don’t impact primary systems; faster than cold backups | Higher RTO than active-active; requires careful replication management to prevent data loss |
This breakdown highlights the key considerations to weigh when deciding on the best redundancy strategy for your disaster recovery plan. Each method has its strengths and weaknesses, making the right choice highly dependent on your specific needs and priorities.
Conclusion
Choosing the right redundancy method comes down to understanding your business needs and the criticality of your systems. For mission-critical systems (Tier 0), where even a few seconds of downtime is unacceptable, active-active redundancy is the way to go. These systems often demand Service Level Objectives (SLOs) of 99.999% or higher and Recovery Time Objectives (RTOs) that are essentially zero.
For moderately critical systems (Tier 1), where brief interruptions are manageable, an active-passive warm standby setup offers a solid middle ground between cost and quick recovery. This method is particularly effective for customer-facing applications that need dependable performance without overspending. However, regular testing is crucial to ensure your disaster recovery plan works when it’s needed most.
When it comes to operational systems (Tier 2), where longer RTOs of a few hours are acceptable, active-passive cold standby provides a cost-efficient option. Similarly, administrative workloads (Tier 3) often rely on backup and restore methods, with recovery times stretching from hours to days. These tiered strategies form the foundation of a robust disaster recovery plan.
To make these strategies work seamlessly, align your redundancy methods with the criticality of your workloads. Managed services can simplify this process by automating redundancy and replication tasks. Automating failover mechanisms is another key step to reducing downtime. As the Microsoft Azure Well-Architected Framework advises:
"More workload redundancy equates to more costs. Carefully consider adding redundancy and regularly review your architecture to ensure that you’re managing costs."
Start by categorizing your workloads into tiers and setting clear RTO and Recovery Point Objective (RPO) targets for each. The most effective approach isn’t necessarily the most expensive – it’s the one that balances protection with sustainability.
For operational resilience, consider partnering with Serverion. With their multi-region hosting, you can ensure uninterrupted operations, even during regional disruptions, keeping your critical systems running no matter what.
FAQs
What costs should I consider when setting up cross-region failover for disaster recovery?
Setting up cross-region failover comes with a variety of costs that need careful consideration. A significant expense is tied to compute resources in the secondary region. If you opt for a warm-standby or hot-standby setup, you’ll face higher costs due to running additional instances, storage, and licensing requirements. On the other hand, a cold-standby setup is generally more economical, as it mainly involves maintaining replicated data without keeping instances running continuously.
Another major cost to account for is data replication storage, which is billed separately in each region. Opting for regions with lower storage fees can help keep these costs in check. Additionally, inter-region data transfer fees apply to ongoing data replication and any traffic generated during failover events. These charges can escalate quickly when dealing with large datasets.
You should also factor in management and licensing costs for disaster recovery tools, monitoring systems, and any third-party services you rely on. To manage expenses effectively, many organizations adopt a tiered approach. For example, they might keep only critical services in a warm-standby state, use cost-efficient storage solutions, and plan bandwidth usage carefully based on recovery goals.
By assigning specific values to these cost elements – such as instance rates (e.g., $0.10/hour), storage fees (e.g., $0.023/GB per month), and data transfer costs (e.g., $0.02/GB) – businesses can craft a failover strategy that balances reliability and affordability.
How does cross-region failover improve data reliability during regional outages?
Cross-region failover ensures your data stays accessible by keeping a synchronized backup in a secondary region. If the primary region goes offline due to an outage, traffic is seamlessly redirected to the secondary region. This means users can continue accessing the latest data without interruptions.
This method plays a key role in disaster recovery plans, helping businesses achieve high availability and reducing downtime during regional outages. By replicating data across distant locations, companies can protect their operations and provide a consistent experience for users, no matter what happens.
What should I consider when choosing between active-active and active-passive redundancy setups?
When choosing between active-active and active-passive redundancy setups, it’s important to weigh factors like cost, performance requirements, and operational complexity.
An active-passive setup is generally more budget-friendly. It uses a primary server with a standby, making it straightforward to deploy and maintain. On the other hand, an active-active configuration involves higher expenses because it doubles the infrastructure and requires more effort to manage.
Performance needs and tolerance for downtime are also critical considerations. Active-active setups shine in high-traffic environments where consistent performance is a must. By distributing traffic across all nodes, they eliminate failover delays. However, for smaller applications or systems with moderate demands, an active-passive setup is often sufficient and easier to handle.
Lastly, think about your team’s capacity and how much downtime is acceptable. Active-active systems demand advanced management and synchronization, which may require more skilled resources. Meanwhile, active-passive setups are simpler and work well for teams with limited resources or those that can manage brief failover periods. Both options can be adjusted to strike the right balance between cost, performance, and availability for your specific needs.




